torch version: 2.5.1
tiktoken version: 0.7.01. Set up
Create a virtual environment
I highly recommend installing Python packages in a separate virtual environment to avoid modifying system-wide packages that your OS may depend on. To create a virtual environment in the current folder, follow the three steps below.
1. Install uv
pip install uv2. Create the virtual environment
uv venv --python=python3.103. Activate the virtual environment
source .venv/bin/activate
Note that you need to activate the virtual environment each time you start a new terminal session. For example, if you restart your terminal or computer and want to continue working on the project the next day, simply run source .venv/bin/activate in the project folder to reactivate your virtual environment.
Optionally, you can deactivate the environment it by executing the command deactivate.
4.Install packages
After activating your virtual environment, you can install Python packages using uv. For example:
uv pip install packagingTo install all required packages from a requirements.txt file (such as the one located at the top level of this GitHub repository) run the following command, assuming the file is in the same directory as your terminal session:
uv pip install -r requirements.txtAlternatively, install the latest dependencies directly from the repository:
uv pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
Note: If you have problems with the following commands above due to certain dependencies (for example, if you are using Windows), you can always fall back to using regular pip: pip install -r requirements.txt or pip install -U -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
2. Working with text data
This section explores techniques for processing and working with text data for language models.
Packages that are being used in this notebook:
- This chapter covers data preparation and sampling to get input data “ready” for the LLM

2.1 Understanding word embeddings
No code in this section
There are many forms of embeddings; we focus on text embeddings in this book
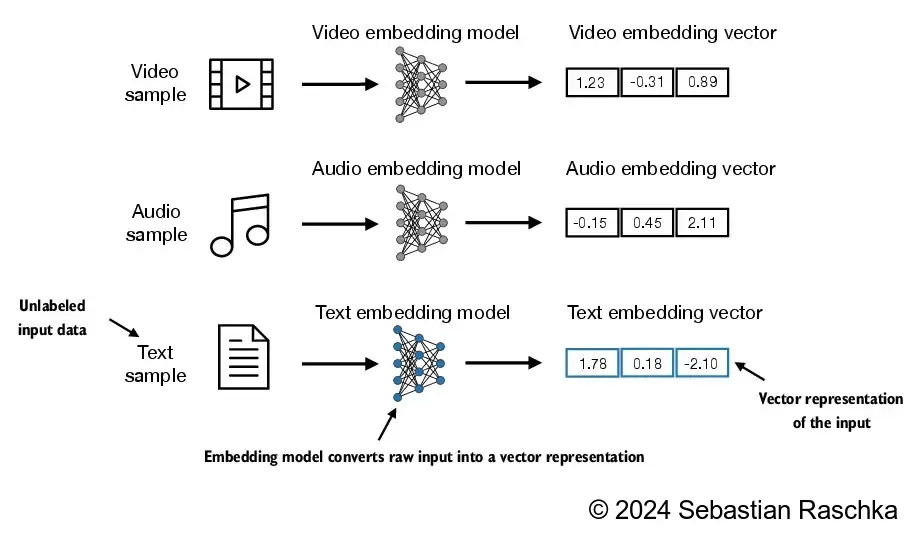
- LLMs work with embeddings in high-dimensional spaces (i.e., thousands of dimensions)
- Since we can’t visualize such high-dimensional spaces (we humans think in 1, 2, or 3 dimensions), the figure below illustrates a 2-dimensional embedding space

2.2 Tokenizing text
- In this section, we tokenize text, which means breaking text into smaller units, such as individual words and punctuation characters

Load raw text we want to work with
The Verdict by Edith Wharton is a public domain short story
(If you encounter an
ssl.SSLCertVerificationErrorwhen executing the previous code cell, it might be due to using an outdated Python version; you can find more information here on GitHub)
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no - The goal is to tokenize and embed this text for an LLM
- Let’s develop a simple tokenizer based on some simple sample text that we can then later apply to the text above
- The following regular expression will split on whitespaces
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']- We don’t only want to split on whitespaces but also commas and periods, so let’s modify the regular expression to do that as well
['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']- As we can see, this creates empty strings, let’s remove them
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']- This looks pretty good, but let’s also handle other types of punctuation, such as periods, question marks, and so on
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']- This is pretty good, and we are now ready to apply this tokenization to the raw text

['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']- Let’s calculate the total number of tokens
46902.3 Converting tokens into token IDs
- Next, we convert the text tokens into token IDs that we can process via embedding layers later
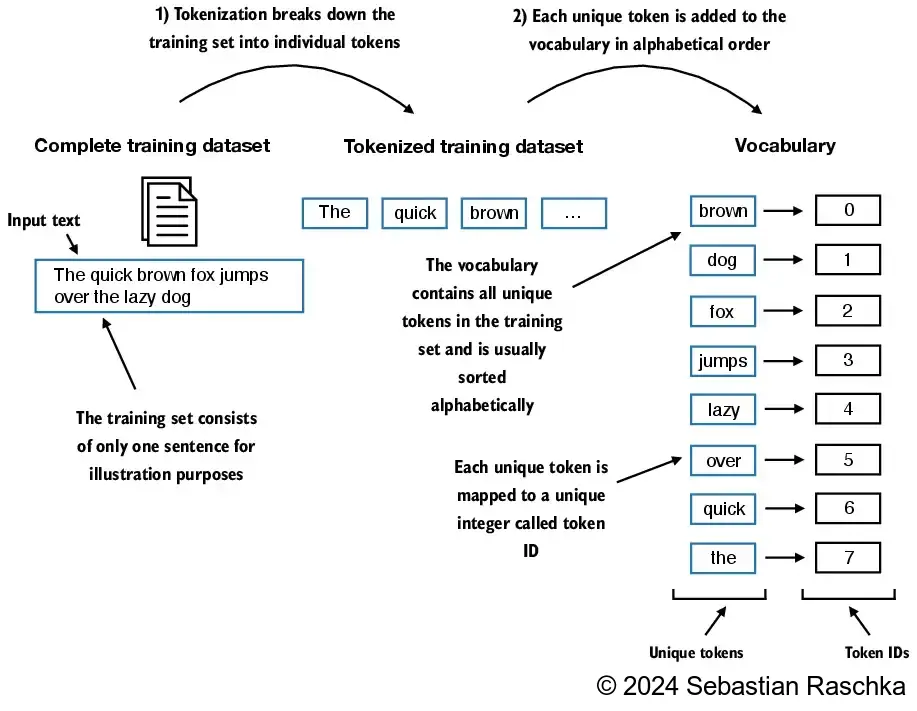
- From these tokens, we can now build a vocabulary that consists of all the unique tokens
1130- Below are the first 50 entries in this vocabulary:
('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
('Chicago', 25)
('Claude', 26)
('Come', 27)
('Croft', 28)
('Destroyed', 29)
('Devonshire', 30)
('Don', 31)
('Dubarry', 32)
('Emperors', 33)
('Florence', 34)
('For', 35)
('Gallery', 36)
('Gideon', 37)
('Gisburn', 38)
('Gisburns', 39)
('Grafton', 40)
('Greek', 41)
('Grindle', 42)
('Grindles', 43)
('HAD', 44)
('Had', 45)
('Hang', 46)
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)- Below, we illustrate the tokenization of a short sample text using a small vocabulary:

Putting it now all together into a tokenizer class
The
encodefunction turns text into token IDsThe
decodefunction turns token IDs back into text

- We can use the tokenizer to encode (that is, tokenize) texts into integers
- These integers can then be embedded (later) as input of/for the LLM
[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]- We can decode the integers back into text
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.''" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'2.4 Adding special context tokens
- It’s useful to add some “special” tokens for unknown words and to denote the end of a text

Some tokenizers use special tokens to help the LLM with additional context
Some of these special tokens are
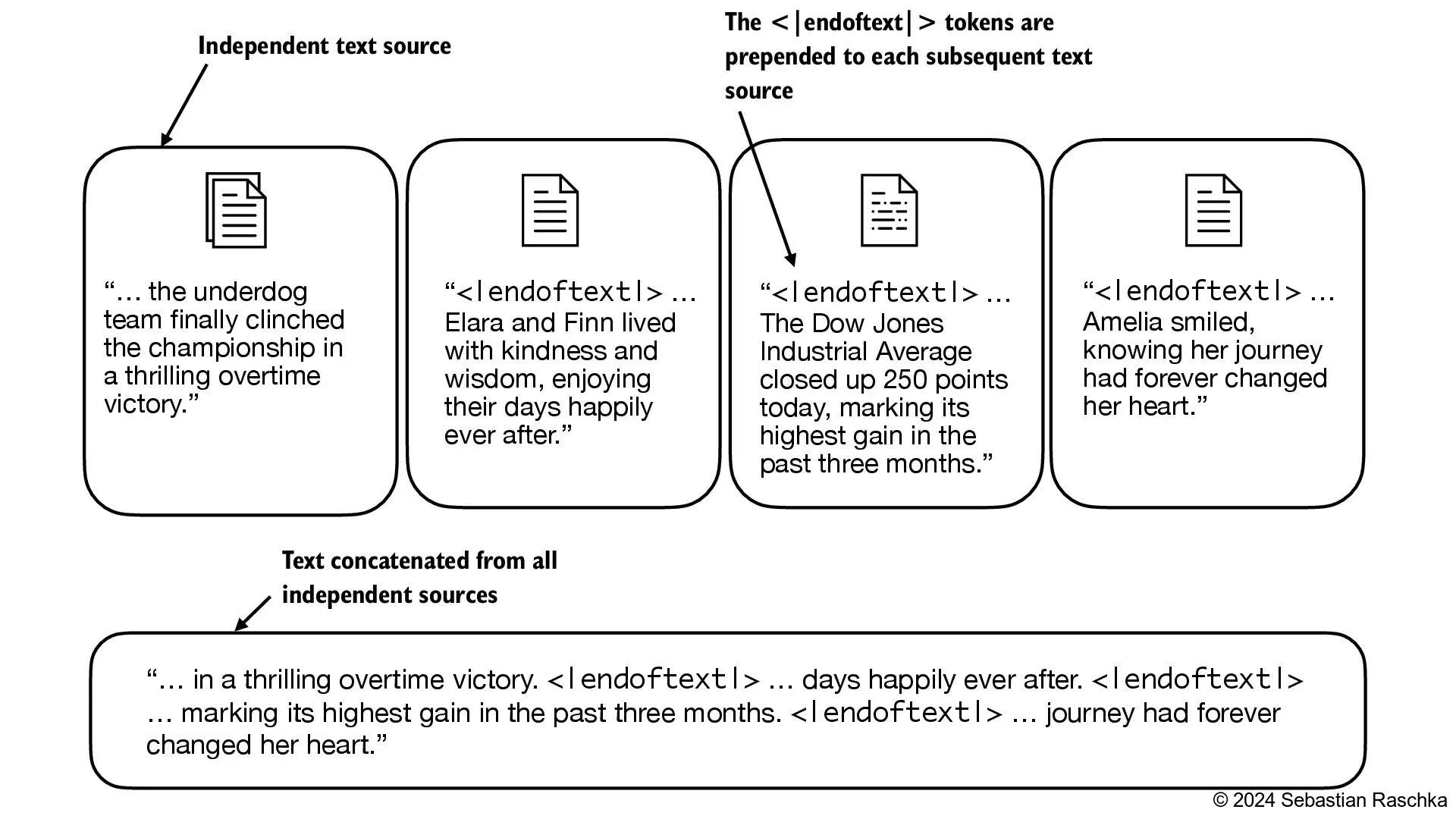
[BOS](beginning of sequence) marks the beginning of text[EOS](end of sequence) marks where the text ends (this is usually used to concatenate multiple unrelated texts, e.g., two different Wikipedia articles or two different books, and so on)[PAD](padding) if we train LLMs with a batch size greater than 1 (we may include multiple texts with different lengths; with the padding token we pad the shorter texts to the longest length so that all texts have an equal length)
[UNK]to represent words that are not included in the vocabularyNote that GPT-2 does not need any of these tokens mentioned above but only uses an
<|endoftext|>token to reduce complexityThe
<|endoftext|>is analogous to the[EOS]token mentioned aboveGPT also uses the
<|endoftext|>for padding (since we typically use a mask when training on batched inputs, we would not attend padded tokens anyways, so it does not matter what these tokens are)GPT-2 does not use an
<UNK>token for out-of-vocabulary words; instead, GPT-2 uses a byte-pair encoding (BPE) tokenizer, which breaks down words into subword units which we will discuss in a later sectionWe use the
<|endoftext|>tokens between two independent sources of text:
- Let’s see what happens if we tokenize the following text:
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[17], line 5 1 tokenizer = SimpleTokenizerV1(vocab) 3 text = "Hello, do you like tea. Is this-- a test?" ----> 5 tokenizer.encode(text) Cell In[13], line 12, in SimpleTokenizerV1.encode(self, text) 7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text) 9 preprocessed = [ 10 item.strip() for item in preprocessed if item.strip() 11 ] ---> 12 ids = [self.str_to_int[s] for s in preprocessed] 13 return ids Cell In[13], line 12, in <listcomp>(.0) 7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text) 9 preprocessed = [ 10 item.strip() for item in preprocessed if item.strip() 11 ] ---> 12 ids = [self.str_to_int[s] for s in preprocessed] 13 return ids KeyError: 'Hello'
- The above produces an error because the word “Hello” is not contained in the vocabulary
- To deal with such cases, we can add special tokens like
"<|unk|>"to the vocabulary to represent unknown words - Since we are already extending the vocabulary, let’s add another token called
"<|endoftext|>"which is used in GPT-2 training to denote the end of a text (and it’s also used between concatenated text, like if our training datasets consists of multiple articles, books, etc.)
1132('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)- We also need to adjust the tokenizer accordingly so that it knows when and how to use the new
<unk>token
Let’s try to tokenize text with the modified tokenizer:
Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]'<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'2.5 BytePair encoding
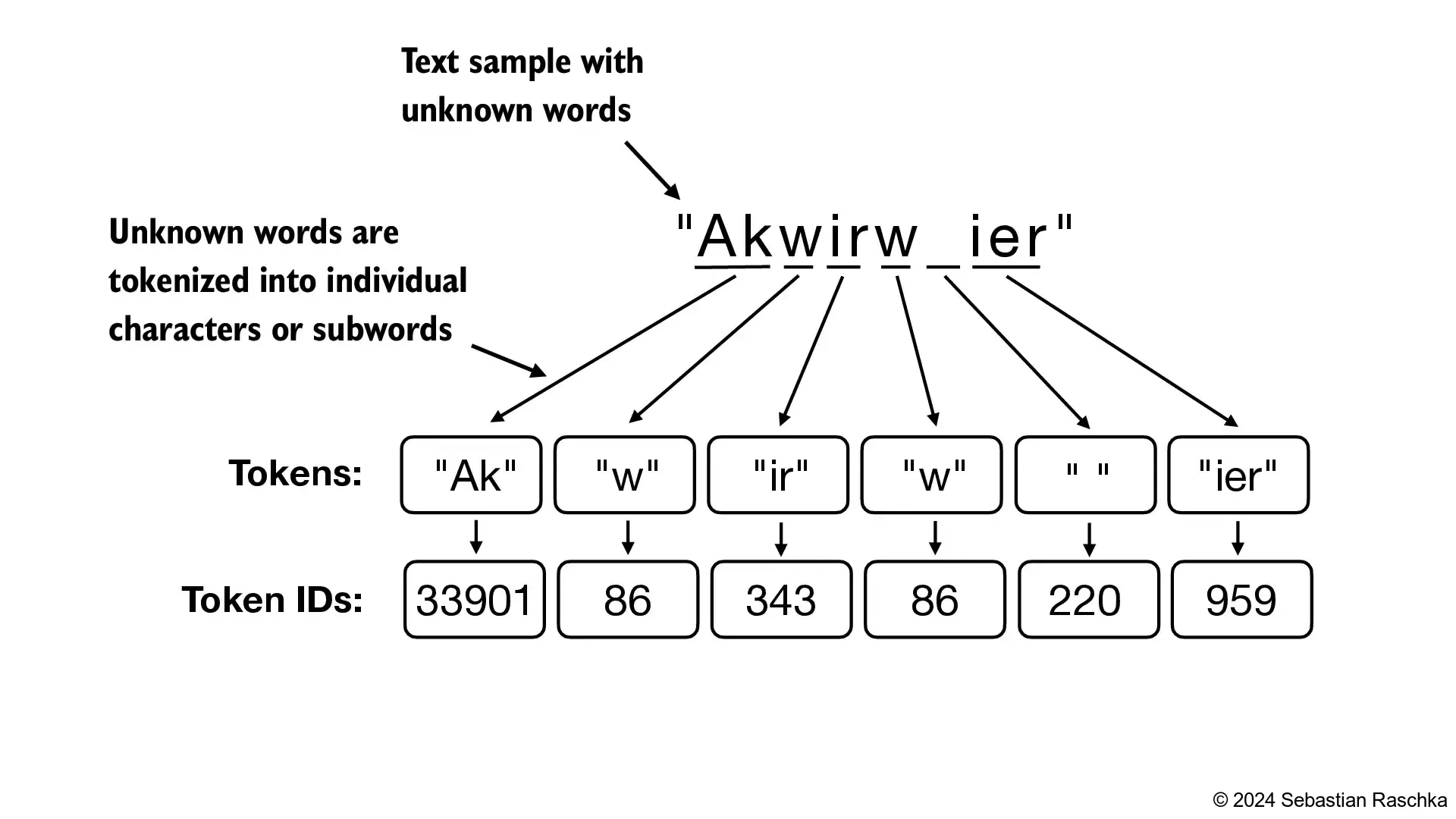
- GPT-2 used BytePair encoding (BPE) as its tokenizer
- it allows the model to break down words that aren’t in its predefined vocabulary into smaller subword units or even individual characters, enabling it to handle out-of-vocabulary words
- For instance, if GPT-2’s vocabulary doesn’t have the word “unfamiliarword,” it might tokenize it as [“unfam”, “iliar”, “word”] or some other subword breakdown, depending on its trained BPE merges
- The original BPE tokenizer can be found here: https://github.com/openai/gpt-2/blob/master/src/encoder.py
- In this chapter, we are using the BPE tokenizer from OpenAI’s open-source tiktoken library, which implements its core algorithms in Rust to improve computational performance
- I created a notebook in the ./bytepair_encoder that compares these two implementations side-by-side (tiktoken was about 5x faster on the sample text)
tiktoken version: 0.7.0[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13]Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.- BPE tokenizers break down unknown words into subwords and individual characters:
2.6 Data sampling with a sliding window
- We train LLMs to generate one word at a time, so we want to prepare the training data accordingly where the next word in a sequence represents the target to predict:

5145- For each text chunk, we want the inputs and targets
- Since we want the model to predict the next word, the targets are the inputs shifted by one position to the right
x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]- One by one, the prediction would look like as follows:
[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257 and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> aWe will take care of the next-word prediction in a later chapter after we covered the attention mechanism
For now, we implement a simple data loader that iterates over the input dataset and returns the inputs and targets shifted by one
Install and import PyTorch (see Appendix A for installation tips)
PyTorch version: 2.5.1- We use a sliding window approach, changing the position by +1:

Create dataset and dataloader that extract chunks from the input text dataset
Let’s test the dataloader with a batch size of 1 for an LLM with a context size of 4:
[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])][tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]- An example using stride equal to the context length (here: 4) as shown below:
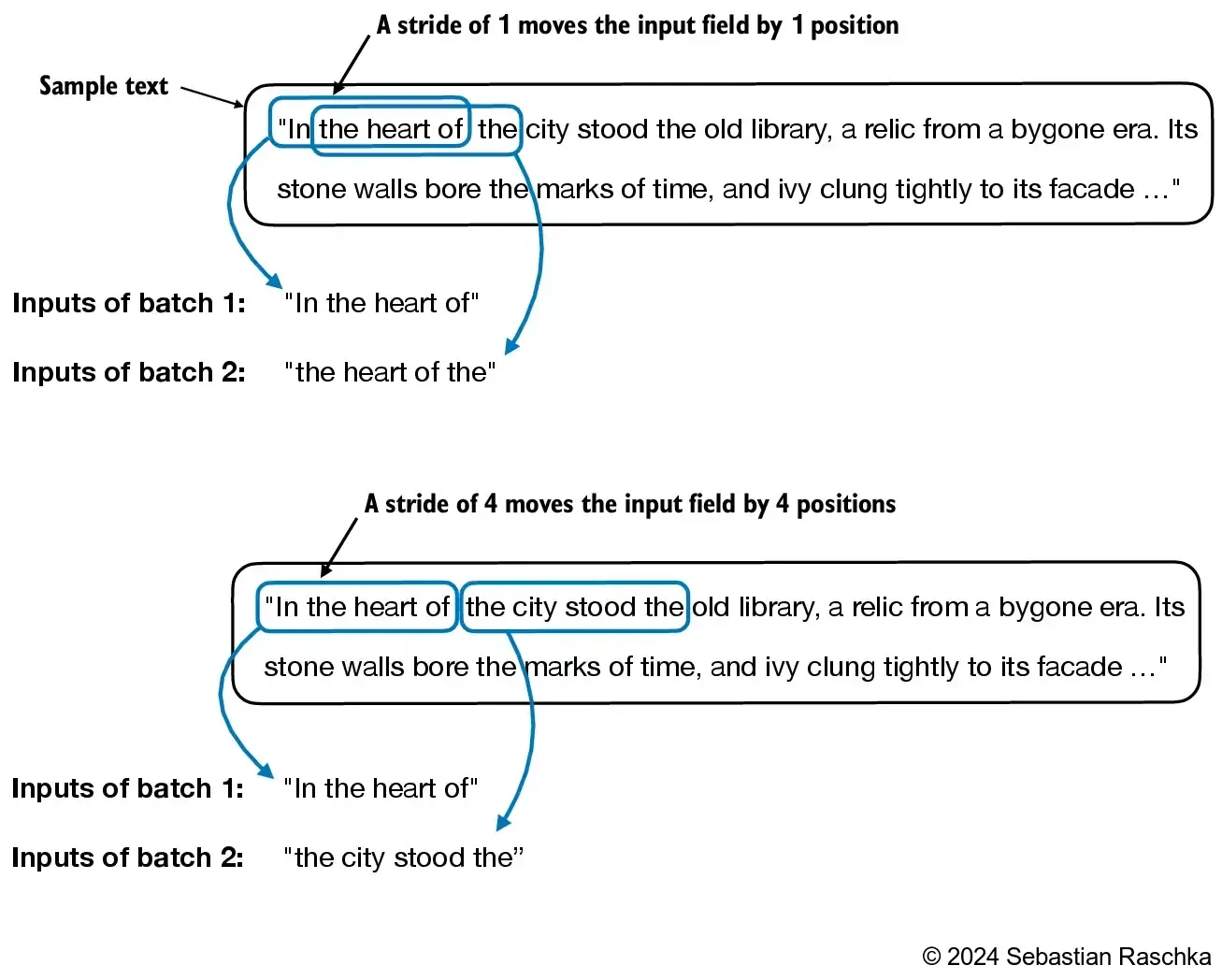
- We can also create batched outputs
- Note that we increase the stride here so that we don’t have overlaps between the batches, since more overlap could lead to increased overfitting
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])2.7 Creating token embeddings
- The data is already almost ready for an LLM
- But lastly let us embed the tokens in a continuous vector representation using an embedding layer
- Usually, these embedding layers are part of the LLM itself and are updated (trained) during model training
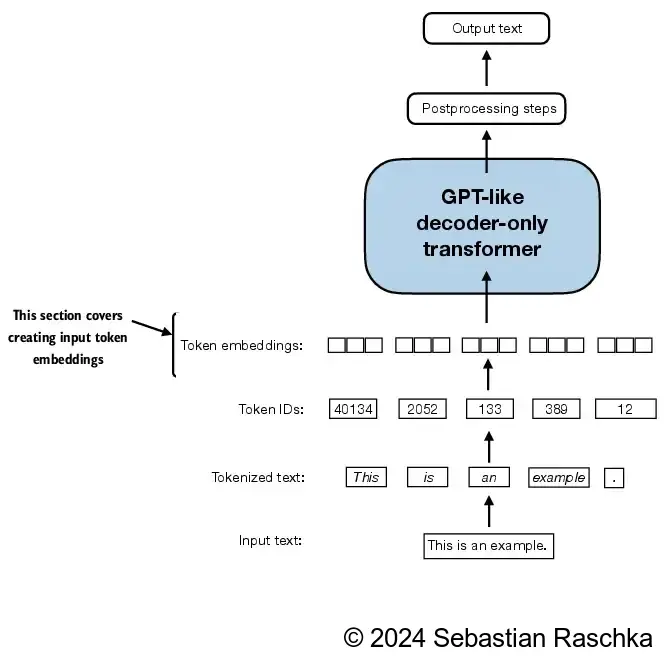
Suppose we have the following four input examples with input ids 2, 3, 5, and 1 (after tokenization):
For the sake of simplicity, suppose we have a small vocabulary of only 6 words and we want to create embeddings of size 3:
This would result in a 6x3 weight matrix:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)For those who are familiar with one-hot encoding, the embedding layer approach above is essentially just a more efficient way of implementing one-hot encoding followed by matrix multiplication in a fully-connected layer, which is described in the supplementary code in ./embedding_vs_matmul
Because the embedding layer is just a more efficient implementation that is equivalent to the one-hot encoding and matrix-multiplication approach it can be seen as a neural network layer that can be optimized via backpropagation
To convert a token with id 3 into a 3-dimensional vector, we do the following:
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)- Note that the above is the 4th row in the
embedding_layerweight matrix - To embed all four
input_idsvalues above, we do
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)- An embedding layer is essentially a look-up operation:

- You may be interested in the bonus content comparing embedding layers with regular linear layers: ../03_bonus_embedding-vs-matmul
2.8 Encoding word positions
- Embedding layer convert IDs into identical vector representations regardless of where they are located in the input sequence:

- Positional embeddings are combined with the token embedding vector to form the input embeddings for a large language model:
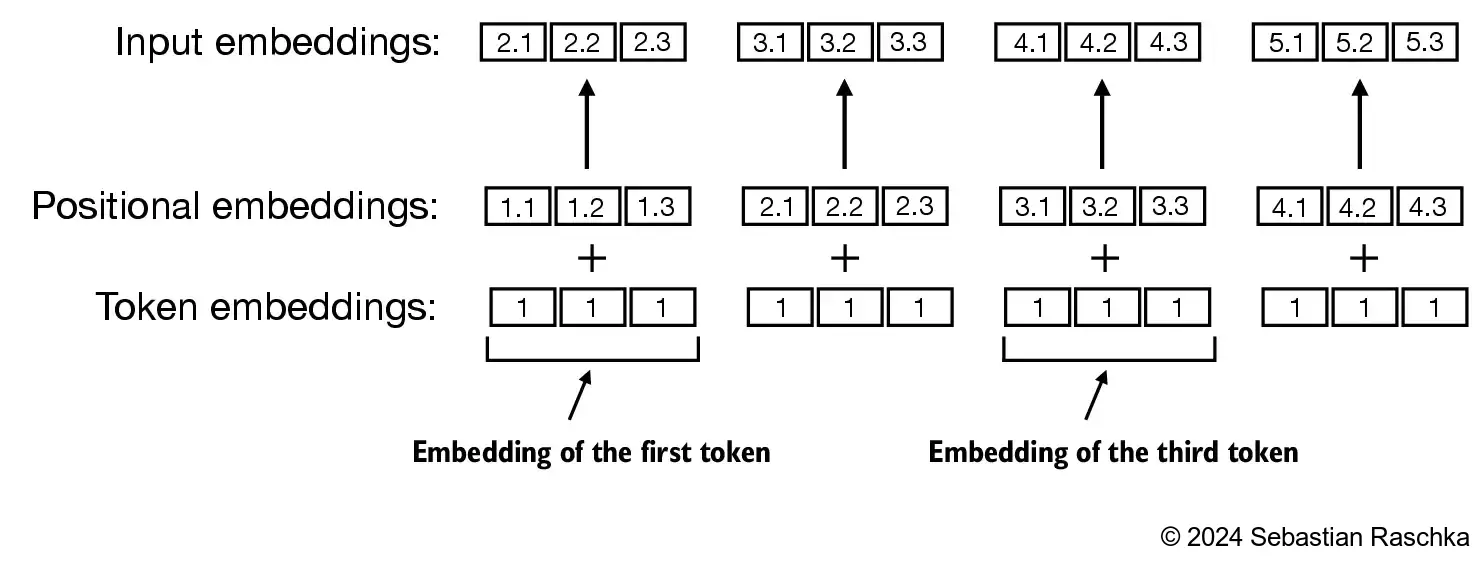
The BytePair encoder has a vocabulary size of 50,257:
Suppose we want to encode the input tokens into a 256-dimensional vector representation:
If we sample data from the dataloader, we embed the tokens in each batch into a 256-dimensional vector
If we have a batch size of 8 with 4 tokens each, this results in a 8 x 4 x 256 tensor:
Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Inputs shape:
torch.Size([8, 4])torch.Size([8, 4, 256])- GPT-2 uses absolute position embeddings, so we just create another embedding layer:
torch.Size([4, 256])- To create the input embeddings used in an LLM, we simply add the token and the positional embeddings:
torch.Size([8, 4, 256])- In the initial phase of the input processing workflow, the input text is segmented into separate tokens
- Following this segmentation, these tokens are transformed into token IDs based on a predefined vocabulary:
Summary and takeaways
See the ./dataloader.ipynb code notebook, which is a concise version of the data loader that we implemented in this chapter and will need for training the GPT model in upcoming chapters.
See ./exercise-solutions.ipynb for the exercise solutions.
See the Byte Pair Encoding (BPE) Tokenizer From Scratch notebook if you are interested in learning how the GPT-2 tokenizer can be implemented and trained from scratch.
3. Coding Attention Mechanisms
Packages that are being used in this notebook:
torch version: 2.4.0- This chapter covers attention mechanisms, the engine of LLMs:
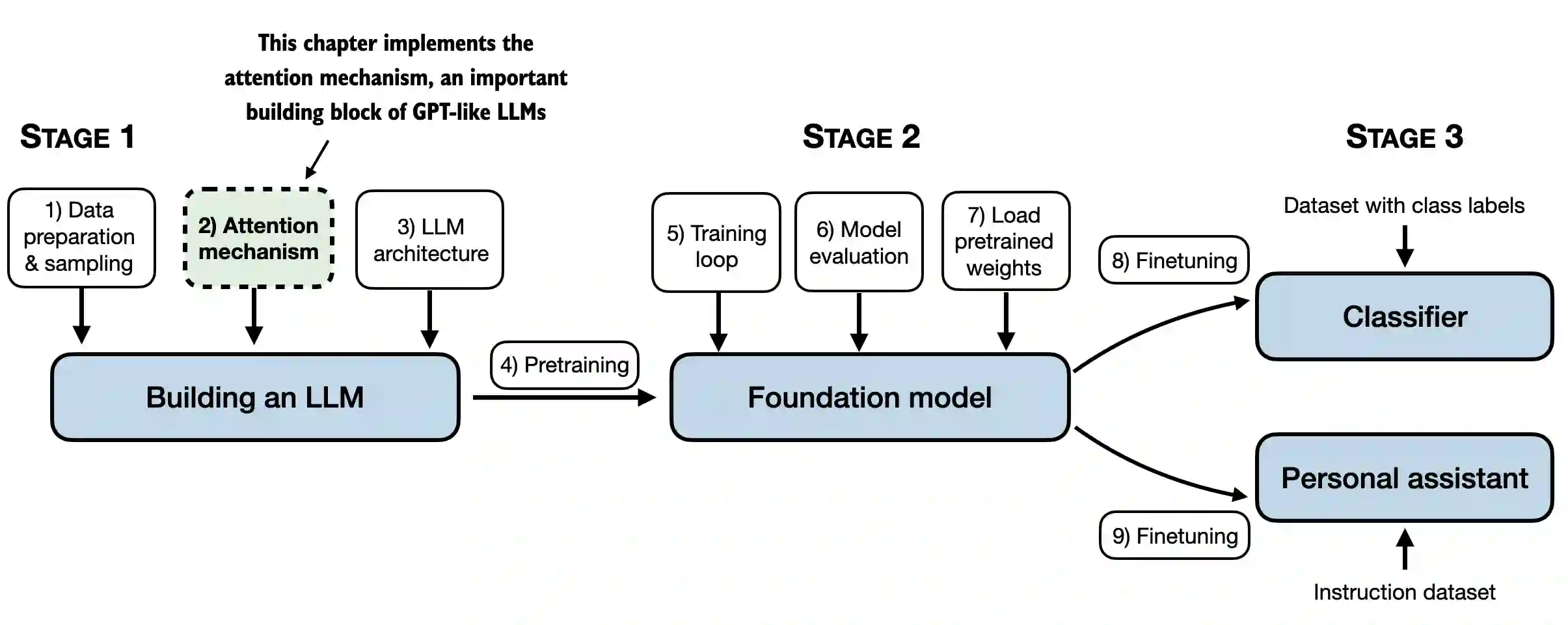

3.1 The problem with modeling long sequences
- No code in this section
- Translating a text word by word isn’t feasible due to the differences in grammatical structures between the source and target languages:
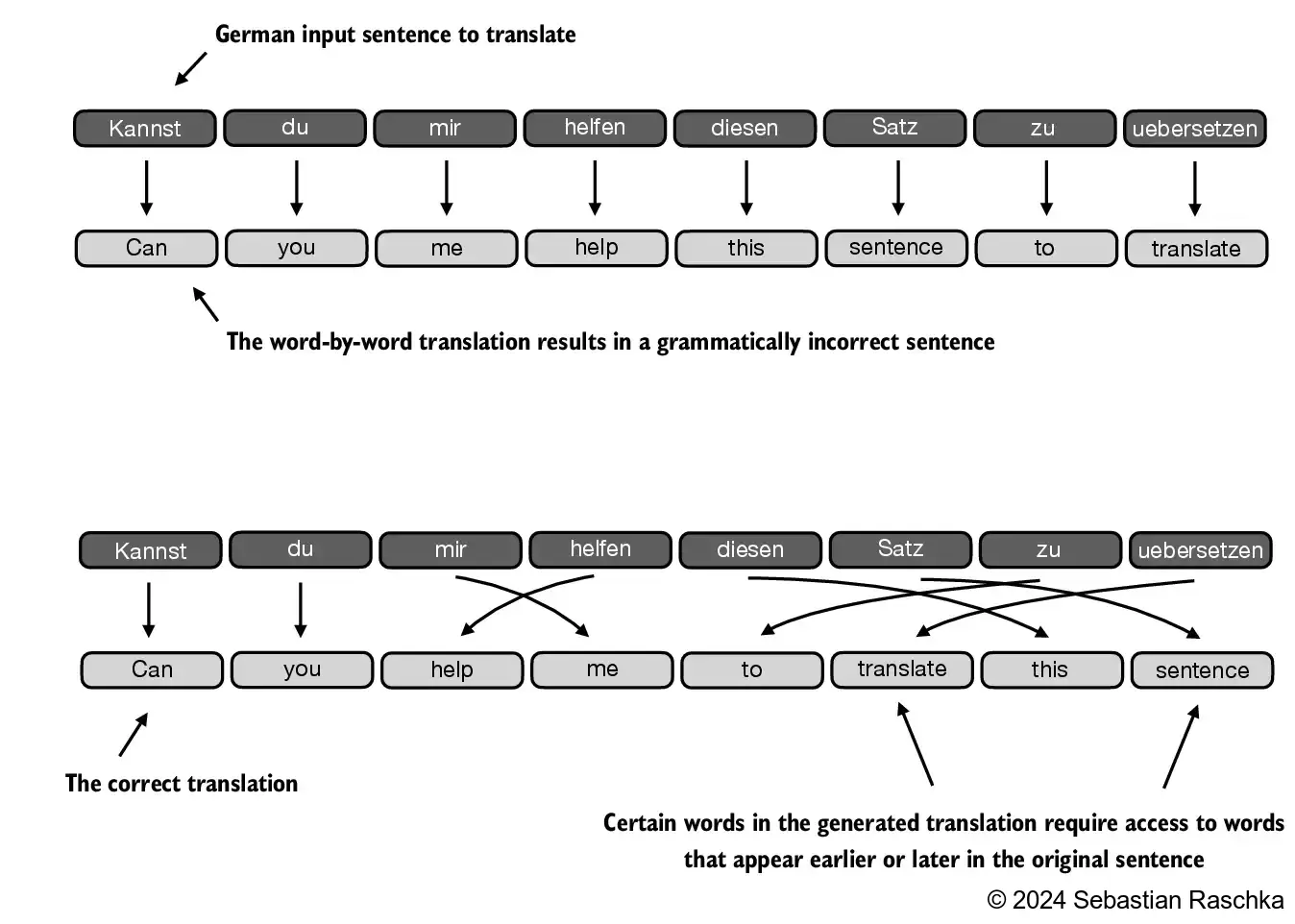
- Prior to the introduction of transformer models, encoder-decoder RNNs were commonly used for machine translation tasks
- In this setup, the encoder processes a sequence of tokens from the source language, using a hidden state—a kind of intermediate layer within the neural network—to generate a condensed representation of the entire input sequence:
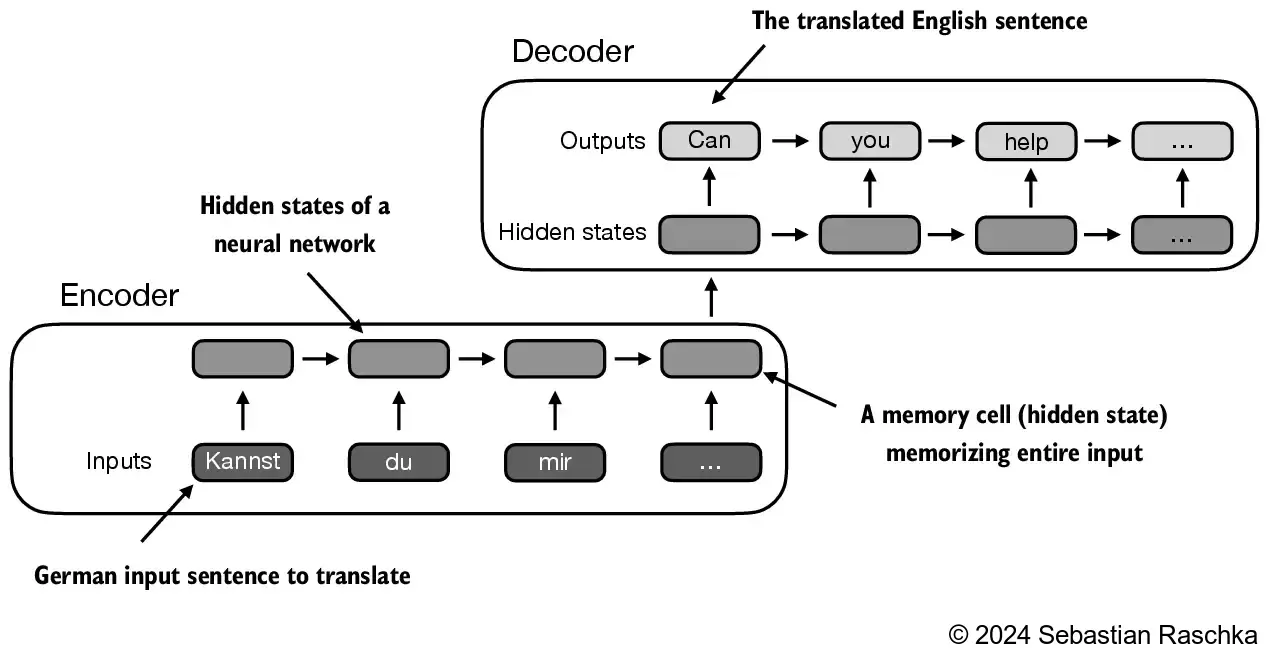
3.2 Capturing data dependencies with attention mechanisms
- No code in this section
- Through an attention mechanism, the text-generating decoder segment of the network is capable of selectively accessing all input tokens, implying that certain input tokens hold more significance than others in the generation of a specific output token:
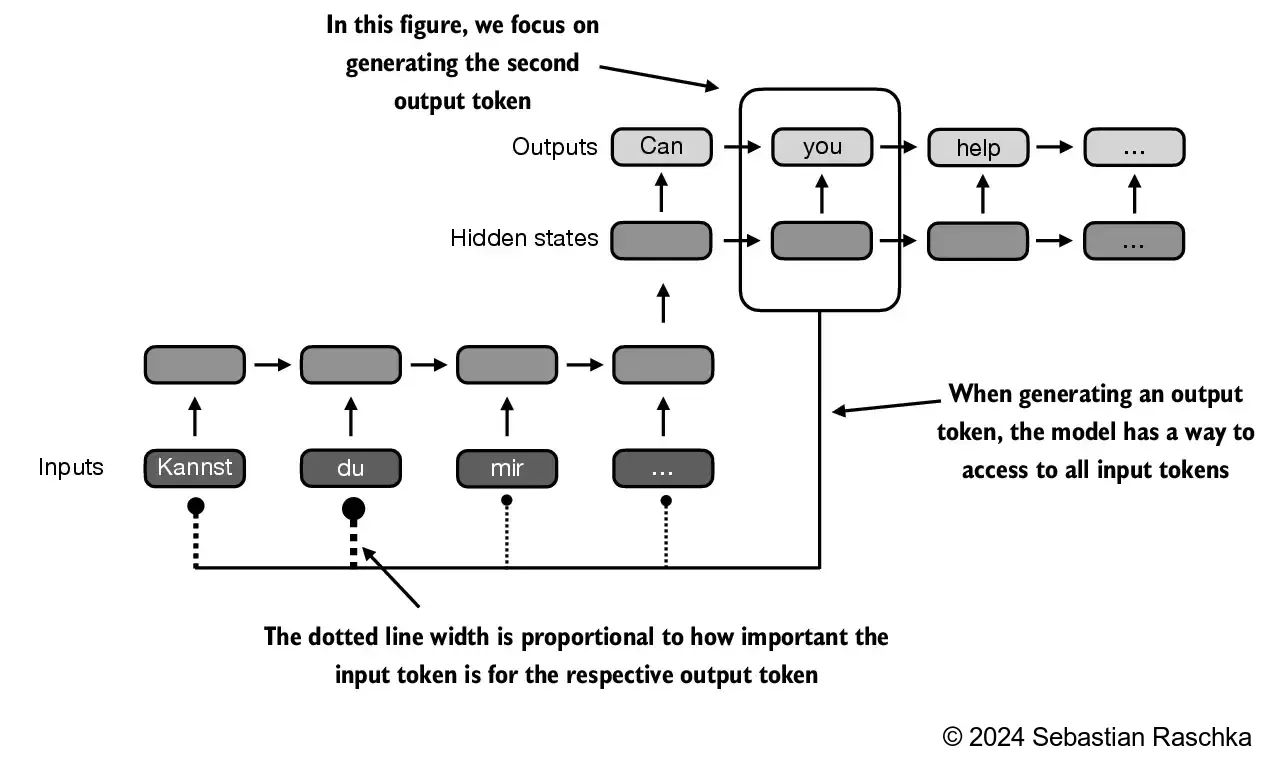
- Self-attention in transformers is a technique designed to enhance input representations by enabling each position in a sequence to engage with and determine the relevance of every other position within the same sequence
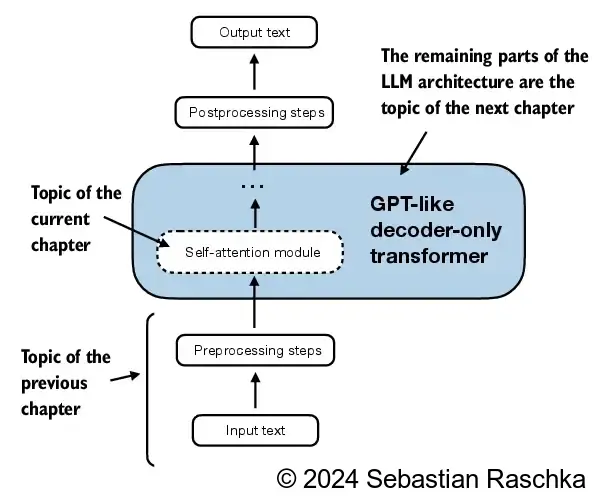
3.3 Attending to different parts of the input with self-attention
3.3.1 A simple self-attention mechanism without trainable weights
- This section explains a very simplified variant of self-attention, which does not contain any trainable weights
- This is purely for illustration purposes and NOT the attention mechanism that is used in transformers
- The next section, section 3.3.2, will extend this simple attention mechanism to implement the real self-attention mechanism
- Suppose we are given an input sequence \(x^{(1)}\) to \(x^{(T)}\)
- The input is a text (for example, a sentence like “Your journey starts with one step”) that has already been converted into token embeddings as described in chapter 2
- For instance, \(x^{(1)}\) is a d-dimensional vector representing the word “Your”, and so forth
- Goal: compute context vectors \(z^{(i)}\) for each input sequence element \(x^{(i)}\) in \(x^{(1)}\) to \(x^{(T)}\) (where \(z\) and \(x\) have the same dimension)
- A context vector \(z^{(i)}\) is a weighted sum over the inputs \(x^{(1)}\) to \(x^{(T)}\)
- The context vector is “context”-specific to a certain input
- Instead of \(x^{(i)}\) as a placeholder for an arbitrary input token, let’s consider the second input, \(x^{(2)}\)
- And to continue with a concrete example, instead of the placeholder \(z^{(i)}\), we consider the second output context vector, \(z^{(2)}\)
- The second context vector, \(z^{(2)}\), is a weighted sum over all inputs \(x^{(1)}\) to \(x^{(T)}\) weighted with respect to the second input element, \(x^{(2)}\)
- The attention weights are the weights that determine how much each of the input elements contributes to the weighted sum when computing \(z^{(2)}\)
- In short, think of \(z^{(2)}\) as a modified version of \(x^{(2)}\) that also incorporates information about all other input elements that are relevant to a given task at hand
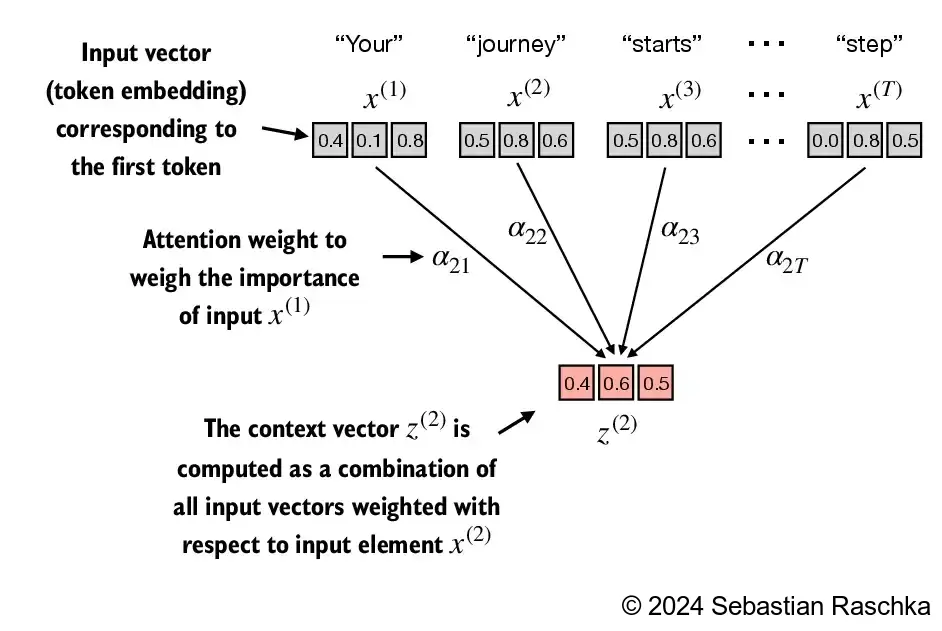
(Please note that the numbers in this figure are truncated to one digit after the decimal point to reduce visual clutter; similarly, other figures may also contain truncated values)
By convention, the unnormalized attention weights are referred to as “attention scores” whereas the normalized attention scores, which sum to 1, are referred to as “attention weights”
The code below walks through the figure above step by step
Step 1: compute unnormalized attention scores \(\omega\)
Suppose we use the second input token as the query, that is, \(q^{(2)} = x^{(2)}\), we compute the unnormalized attention scores via dot products:
- \(\omega_{21} = x^{(1)} q^{(2)\top}\)
- \(\omega_{22} = x^{(2)} q^{(2)\top}\)
- \(\omega_{23} = x^{(3)} q^{(2)\top}\)
- …
- \(\omega_{2T} = x^{(T)} q^{(2)\top}\)
Above, \(\omega\) is the Greek letter “omega” used to symbolize the unnormalized attention scores
- The subscript “21” in \(\omega_{21}\) means that input sequence element 2 was used as a query against input sequence element 1
Suppose we have the following input sentence that is already embedded in 3-dimensional vectors as described in chapter 3 (we use a very small embedding dimension here for illustration purposes, so that it fits onto the page without line breaks):
(In this book, we follow the common machine learning and deep learning convention where training examples are represented as rows and feature values as columns; in the case of the tensor shown above, each row represents a word, and each column represents an embedding dimension)
The primary objective of this section is to demonstrate how the context vector \(z^{(2)}\) is calculated using the second input sequence, \(x^{(2)}\), as a query
The figure depicts the initial step in this process, which involves calculating the attention scores ω between \(x^{(2)}\) and all other input elements through a dot product operation
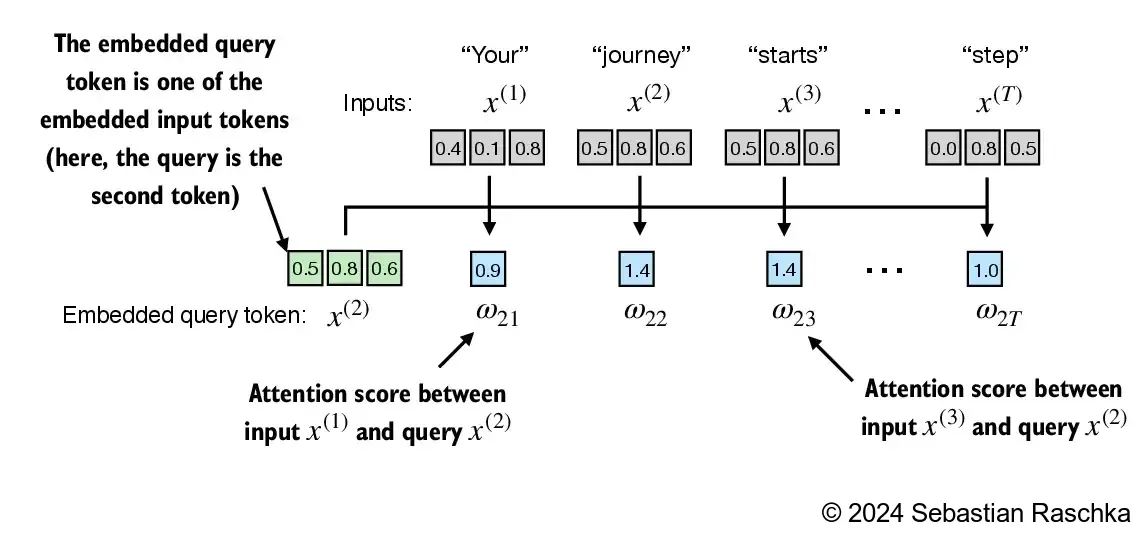
- We use input sequence element 2, \(x^{(2)}\), as an example to compute context vector \(z^{(2)}\); later in this section, we will generalize this to compute all context vectors.
- The first step is to compute the unnormalized attention scores by computing the dot product between the query \(x^{(2)}\) and all other input tokens:
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])- Side note: a dot product is essentially a shorthand for multiplying two vectors elements-wise and summing the resulting products:
tensor(0.9544)
tensor(0.9544)- Step 2: normalize the unnormalized attention scores (“omegas”, \(\omega\)) so that they sum up to 1
- Here is a simple way to normalize the unnormalized attention scores to sum up to 1 (a convention, useful for interpretation, and important for training stability):
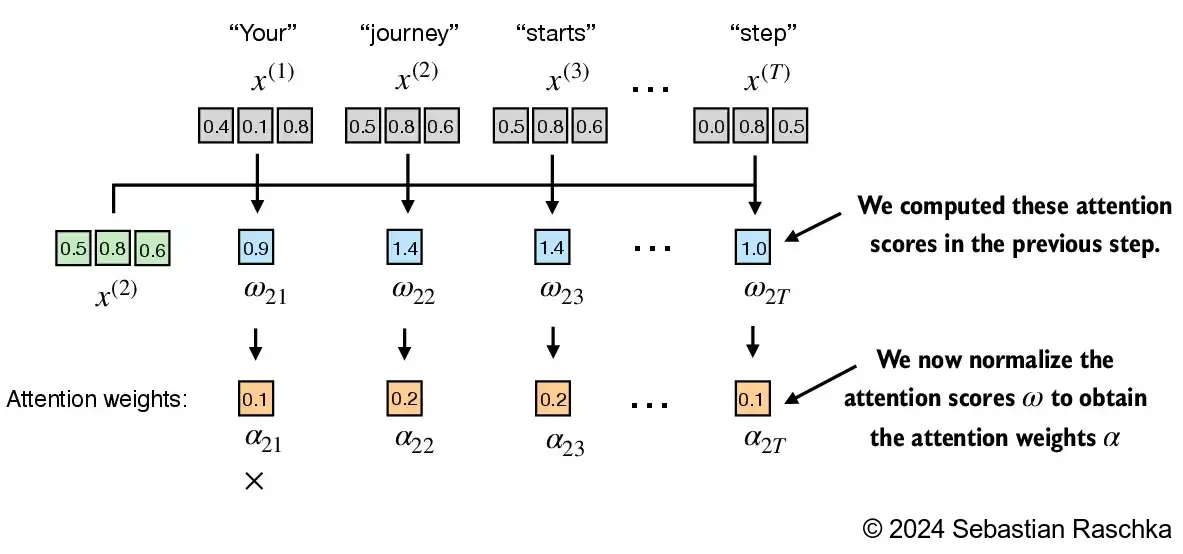
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)- However, in practice, using the softmax function for normalization, which is better at handling extreme values and has more desirable gradient properties during training, is common and recommended.
- Here’s a naive implementation of a softmax function for scaling, which also normalizes the vector elements such that they sum up to 1:
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)- The naive implementation above can suffer from numerical instability issues for large or small input values due to overflow and underflow issues
- Hence, in practice, it’s recommended to use the PyTorch implementation of softmax instead, which has been highly optimized for performance:
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)- Step 3: compute the context vector \(z^{(2)}\) by multiplying the embedded input tokens, \(x^{(i)}\) with the attention weights and sum the resulting vectors:
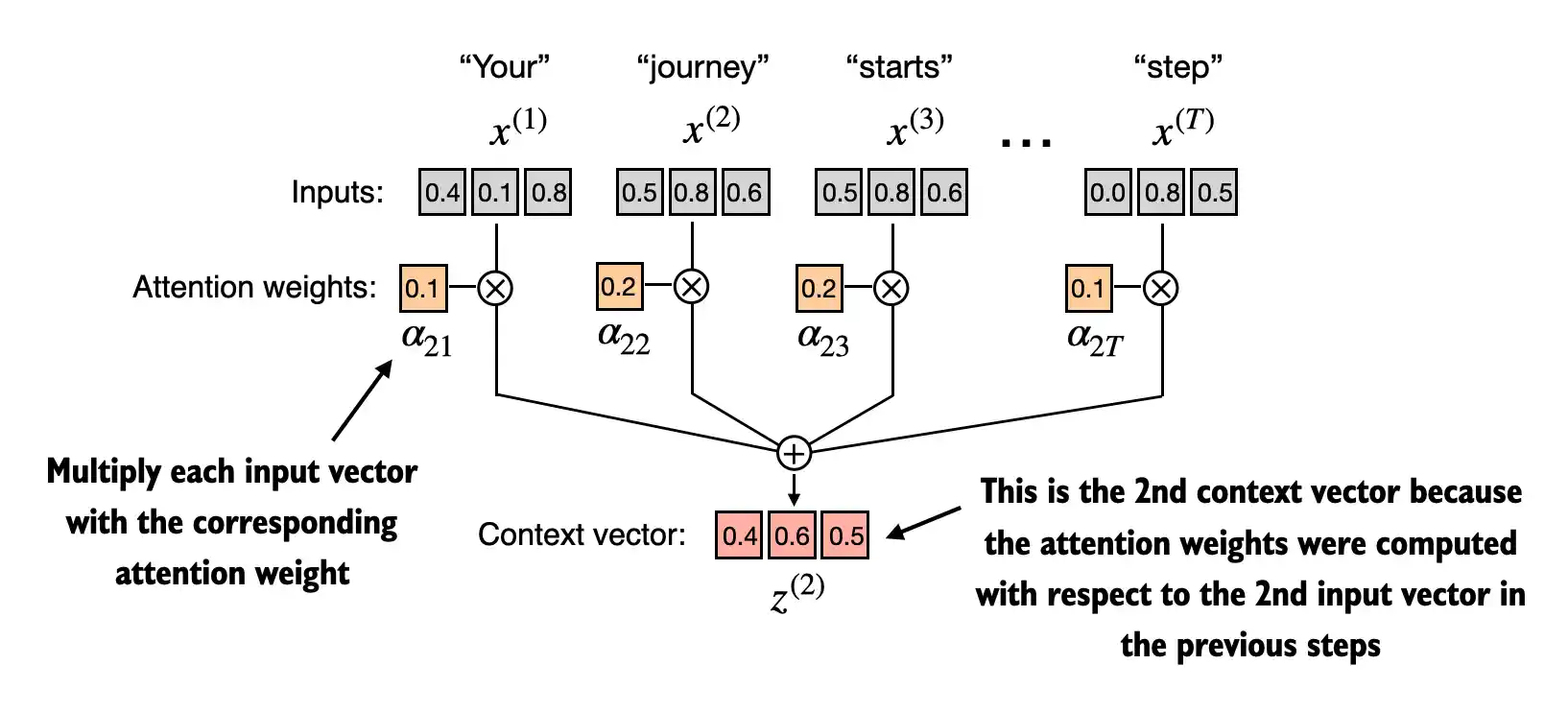
tensor([0.4419, 0.6515, 0.5683])3.3.2 Computing attention weights for all input tokens
Generalize to all input sequence tokens:
- Above, we computed the attention weights and context vector for input 2 (as illustrated in the highlighted row in the figure below)
- Next, we are generalizing this computation to compute all attention weights and context vectors
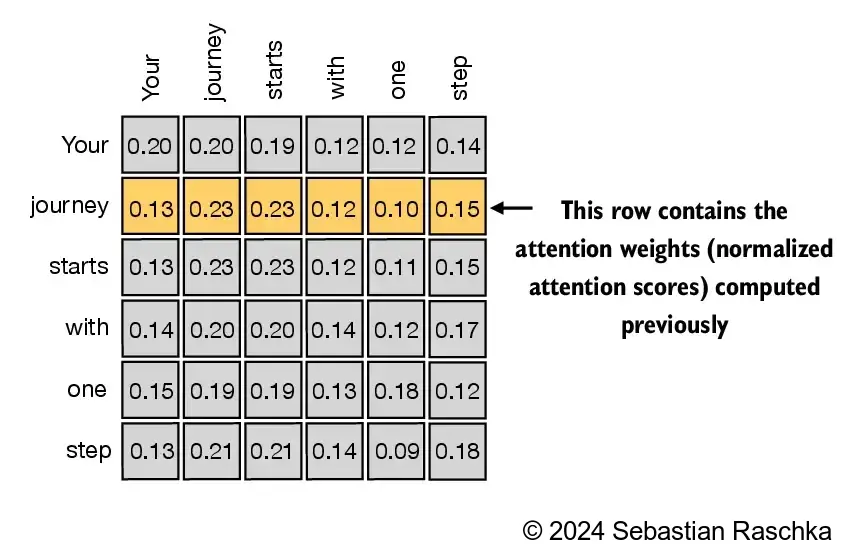
(Please note that the numbers in this figure are truncated to two digits after the decimal point to reduce visual clutter; the values in each row should add up to 1.0 or 100%; similarly, digits in other figures are truncated)
In self-attention, the process starts with the calculation of attention scores, which are subsequently normalized to derive attention weights that total 1
These attention weights are then utilized to generate the context vectors through a weighted summation of the inputs
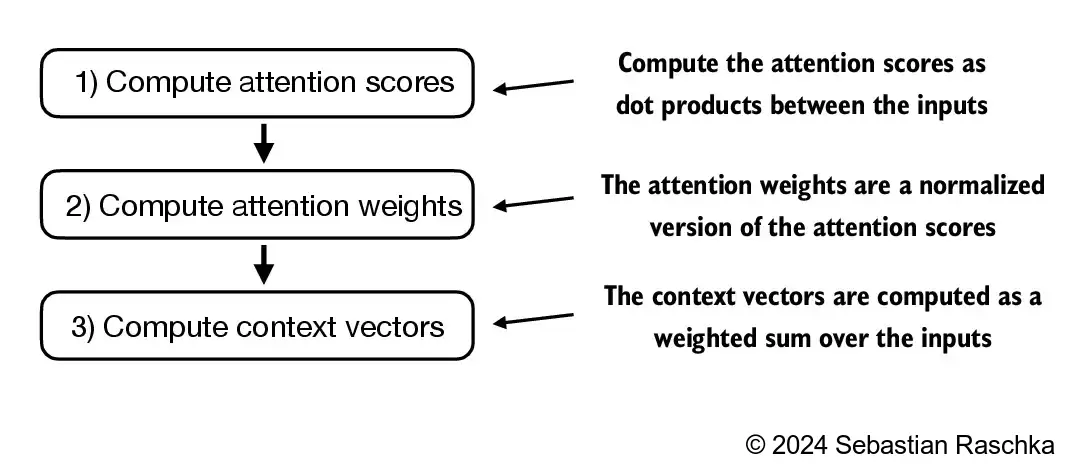
- Apply previous step 1 to all pairwise elements to compute the unnormalized attention score matrix:
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])- We can achieve the same as above more efficiently via matrix multiplication:
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])- Similar to step 2 previously, we normalize each row so that the values in each row sum to 1:
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])- Quick verification that the values in each row indeed sum to 1:
Row 2 sum: 1.0
All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])- Apply previous step 3 to compute all context vectors:
tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])- As a sanity check, the previously computed context vector \(z^{(2)} = [0.4419, 0.6515, 0.5683]\) can be found in the 2nd row in above:
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])3.4 Implementing self-attention with trainable weights
- A conceptual framework illustrating how the self-attention mechanism developed in this section integrates into the overall narrative and structure of this book and chapter
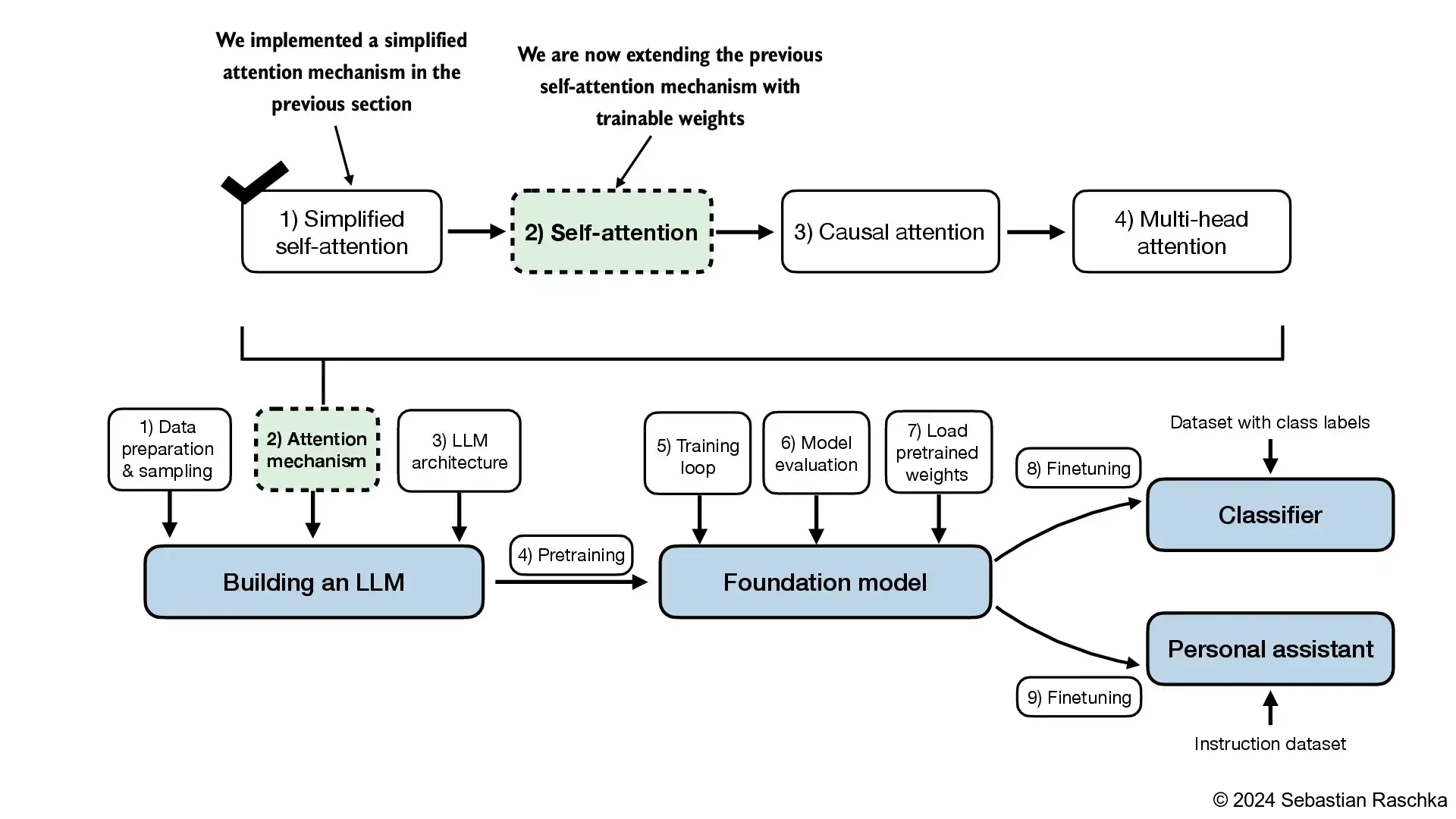
3.4.1 Computing the attention weights step by step
- In this section, we are implementing the self-attention mechanism that is used in the original transformer architecture, the GPT models, and most other popular LLMs
- This self-attention mechanism is also called “scaled dot-product attention”
- The overall idea is similar to before:
- We want to compute context vectors as weighted sums over the input vectors specific to a certain input element
- For the above, we need attention weights
- As you will see, there are only slight differences compared to the basic attention mechanism introduced earlier:
- The most notable difference is the introduction of weight matrices that are updated during model training
- These trainable weight matrices are crucial so that the model (specifically, the attention module inside the model) can learn to produce “good” context vectors
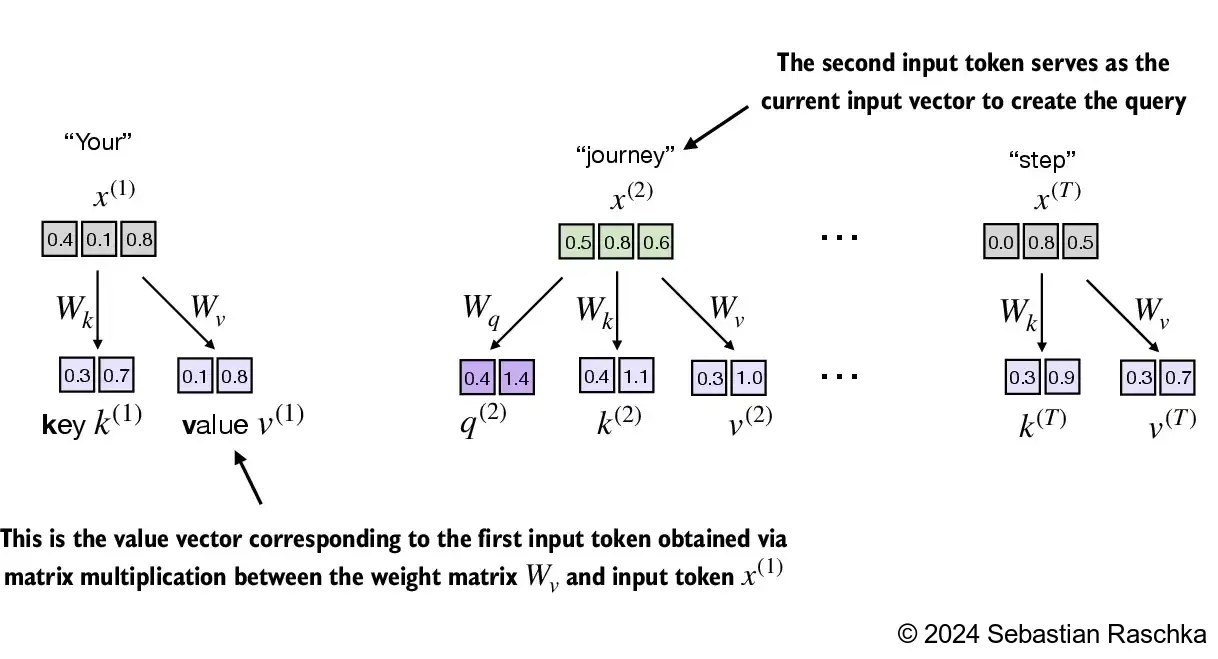
Implementing the self-attention mechanism step by step, we will start by introducing the three training weight matrices \(W_q\), \(W_k\), and \(W_v\)
These three matrices are used to project the embedded input tokens, \(x^{(i)}\), into query, key, and value vectors via matrix multiplication:
- Query vector: $q^{(i)} = x^{(i)},W_q $
- Key vector: $k^{(i)} = x^{(i)},W_k $
- Value vector: $v^{(i)} = x^{(i)},W_v $
The embedding dimensions of the input \(x\) and the query vector \(q\) can be the same or different, depending on the model’s design and specific implementation
In GPT models, the input and output dimensions are usually the same, but for illustration purposes, to better follow the computation, we choose different input and output dimensions here:
Below, we initialize the three weight matrices; note that we are setting
requires_grad=Falseto reduce clutter in the outputs for illustration purposes, but if we were to use the weight matrices for model training, we would setrequires_grad=Trueto update these matrices during model trainingNext we compute the query, key, and value vectors:
tensor([0.4306, 1.4551])- As we can see below, we successfully projected the 6 input tokens from a 3D onto a 2D embedding space:
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])- In the next step, step 2, we compute the unnormalized attention scores by computing the dot product between the query and each key vector:
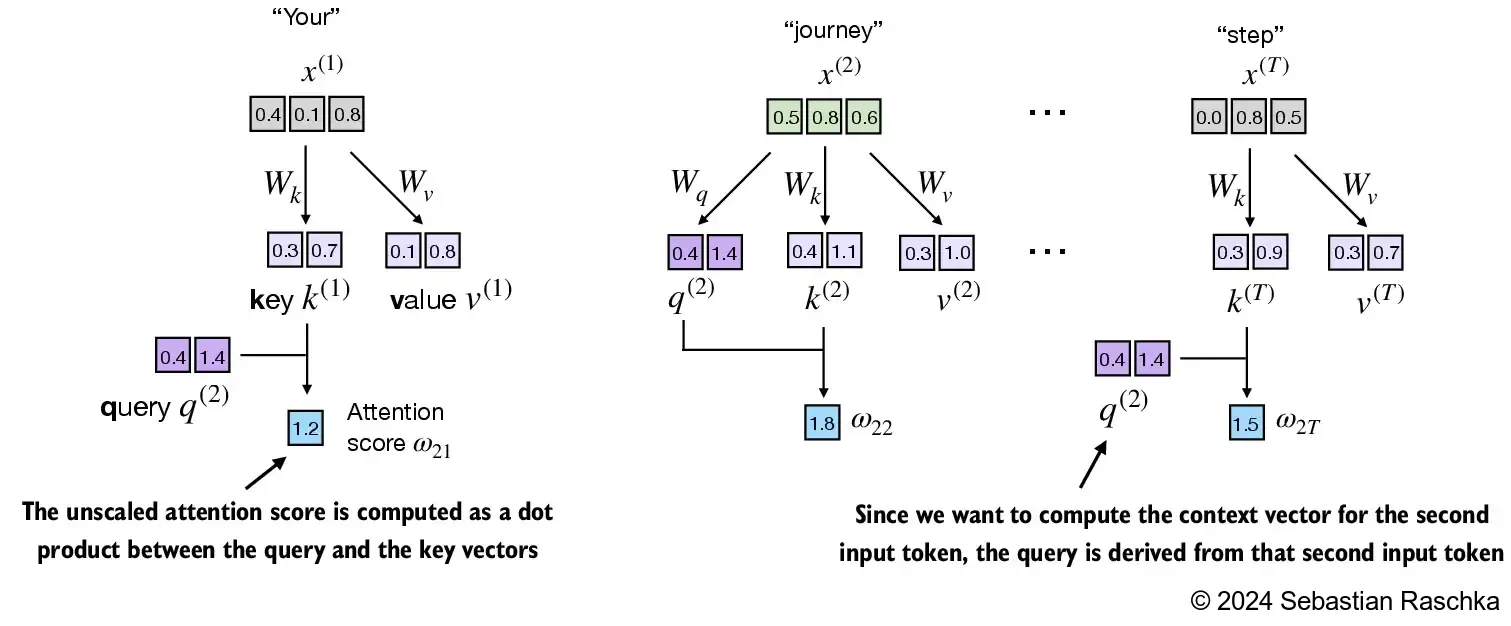
tensor(1.8524)- Since we have 6 inputs, we have 6 attention scores for the given query vector:
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])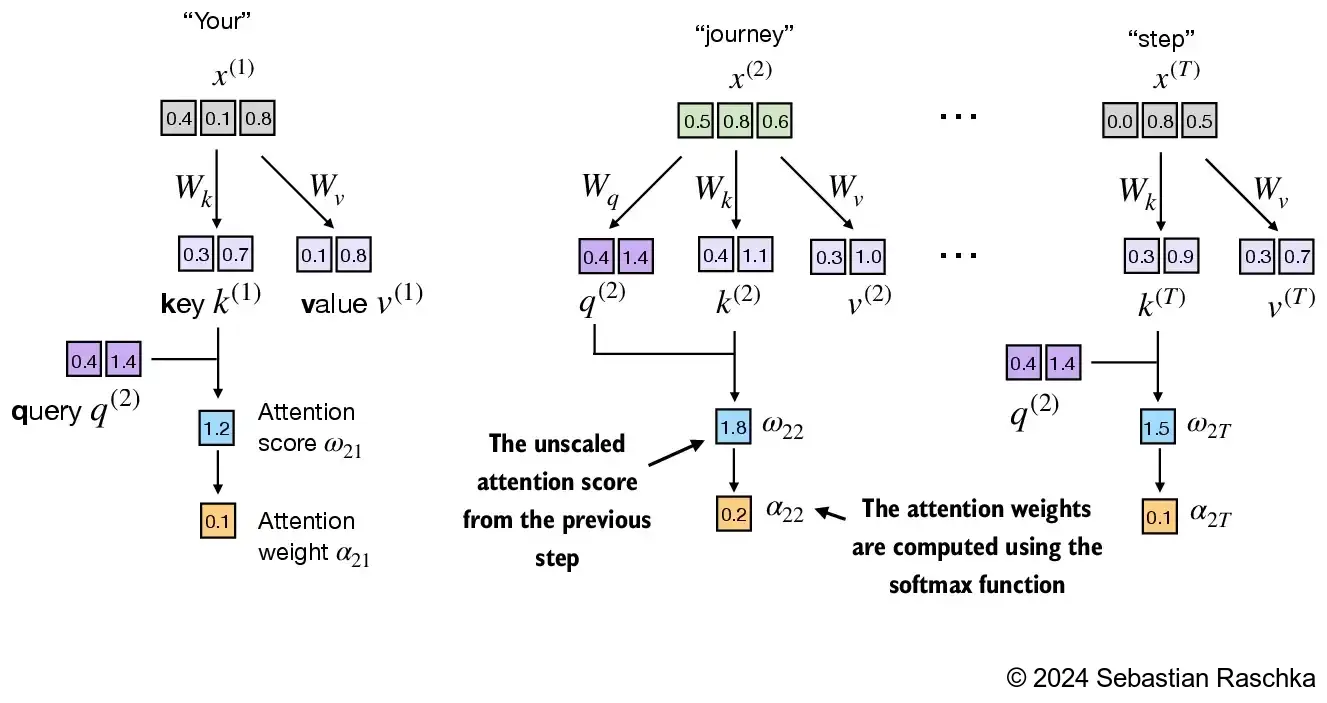
- Next, in step 3, we compute the attention weights (normalized attention scores that sum up to 1) using the softmax function we used earlier
- The difference to earlier is that we now scale the attention scores by dividing them by the square root of the embedding dimension, \(\sqrt{d_k}\) (i.e.,
d_k**0.5):
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])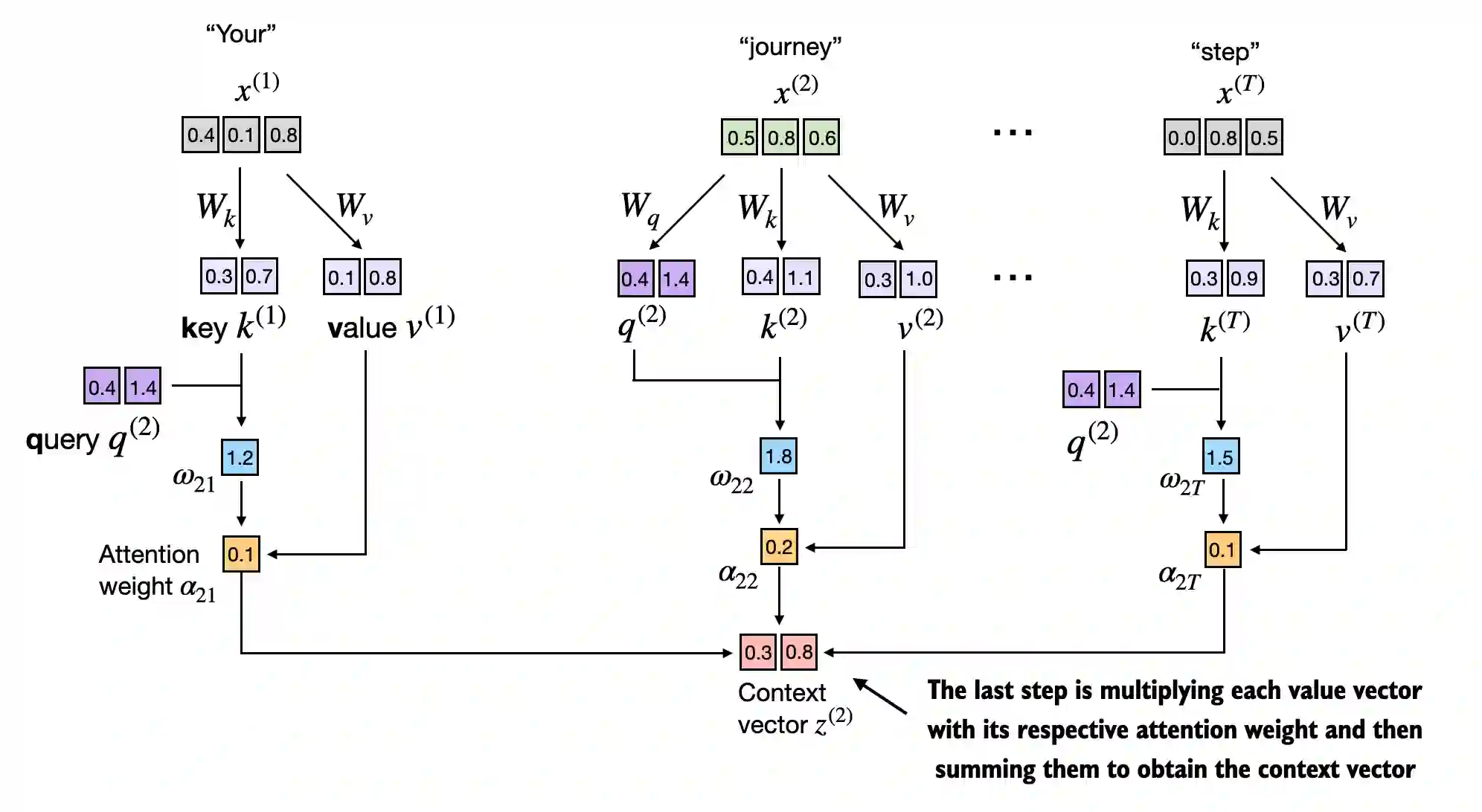
- In step 4, we now compute the context vector for input query vector 2:
tensor([0.3061, 0.8210])3.4.2 Implementing a compact SelfAttention class
- Putting it all together, we can implement the self-attention mechanism as follows:
tensor([[0.2996, 0.8053],
[0.3061, 0.8210],
[0.3058, 0.8203],
[0.2948, 0.7939],
[0.2927, 0.7891],
[0.2990, 0.8040]], grad_fn=<MmBackward0>)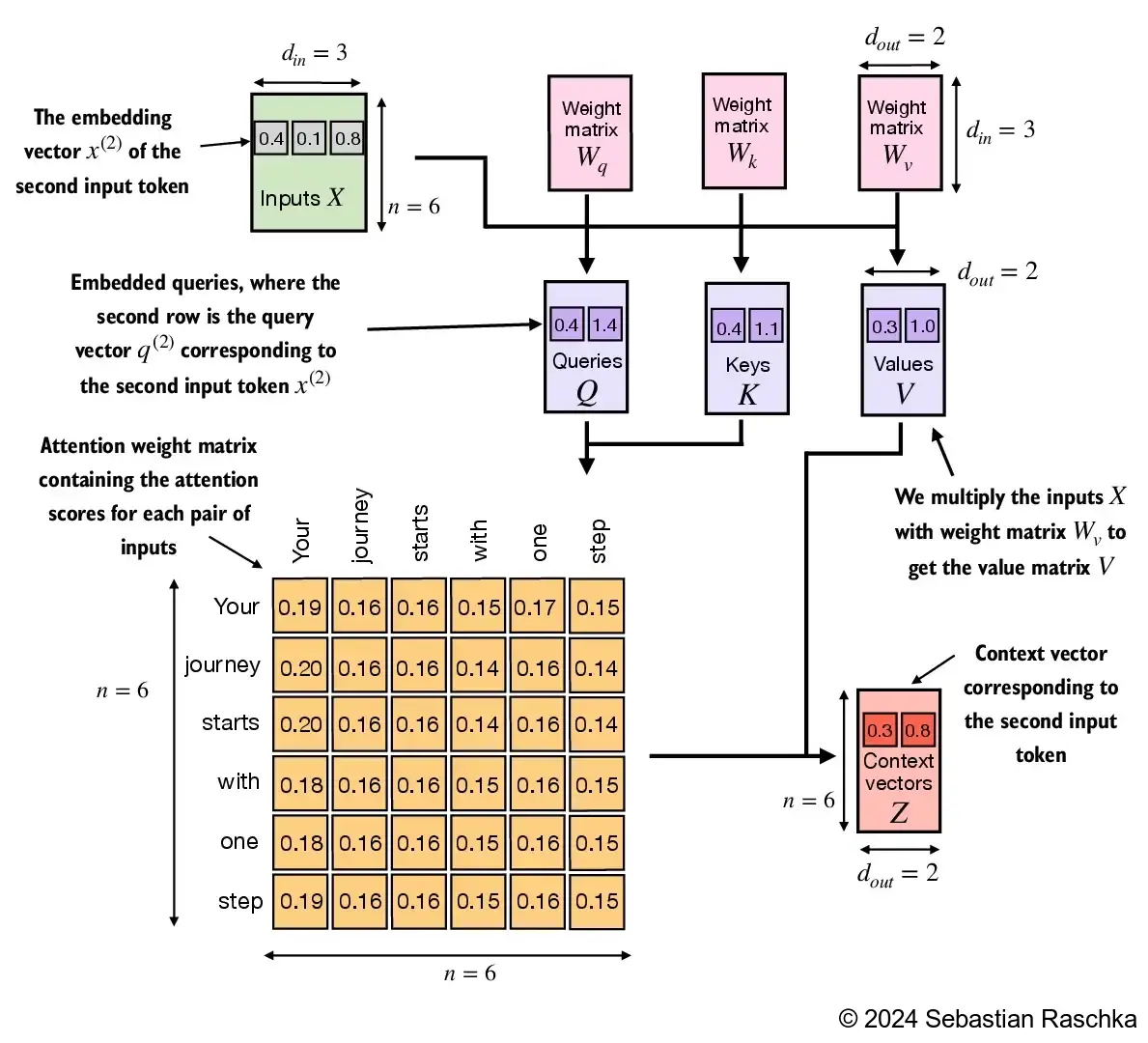
- We can streamline the implementation above using PyTorch’s Linear layers, which are equivalent to a matrix multiplication if we disable the bias units
- Another big advantage of using
nn.Linearover our manualnn.Parameter(torch.rand(...)approach is thatnn.Linearhas a preferred weight initialization scheme, which leads to more stable model training
tensor([[-0.0739, 0.0713],
[-0.0748, 0.0703],
[-0.0749, 0.0702],
[-0.0760, 0.0685],
[-0.0763, 0.0679],
[-0.0754, 0.0693]], grad_fn=<MmBackward0>)- Note that
SelfAttention_v1andSelfAttention_v2give different outputs because they use different initial weights for the weight matrices
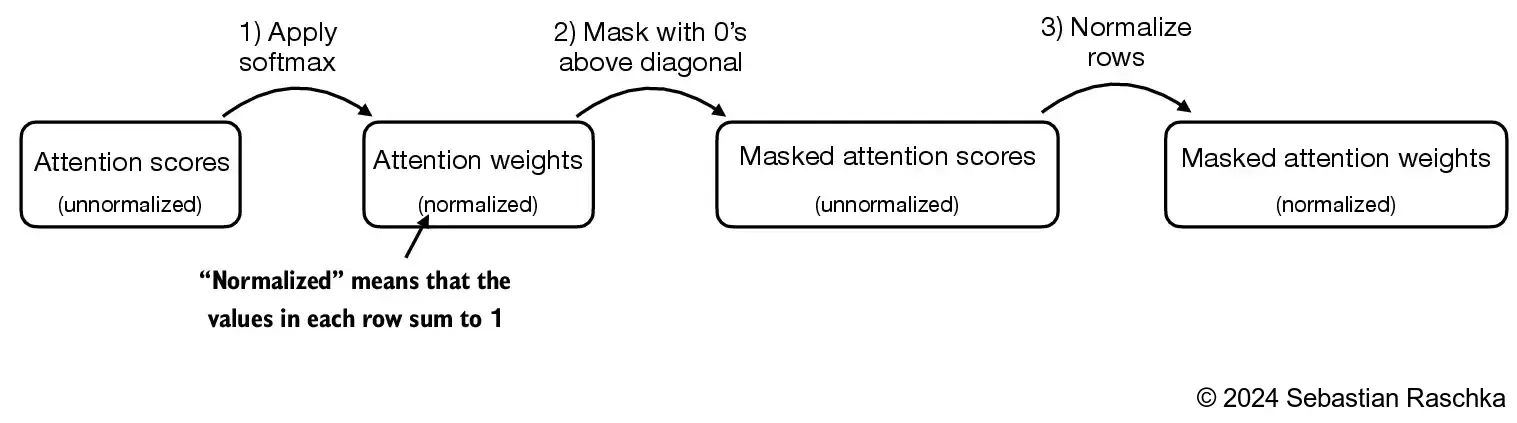
3.5 Hiding future words with causal attention
- In causal attention, the attention weights above the diagonal are masked, ensuring that for any given input, the LLM is unable to utilize future tokens while calculating the context vectors with the attention weight

3.5.1 Applying a causal attention mask
- In this section, we are converting the previous self-attention mechanism into a causal self-attention mechanism
- Causal self-attention ensures that the model’s prediction for a certain position in a sequence is only dependent on the known outputs at previous positions, not on future positions
- In simpler words, this ensures that each next word prediction should only depend on the preceding words
- To achieve this, for each given token, we mask out the future tokens (the ones that come after the current token in the input text):
- To illustrate and implement causal self-attention, let’s work with the attention scores and weights from the previous section:
tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],
[0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],
[0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],
[0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],
[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<SoftmaxBackward0>)- The simplest way to mask out future attention weights is by creating a mask via PyTorch’s tril function with elements below the main diagonal (including the diagonal itself) set to 1 and above the main diagonal set to 0:
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])- Then, we can multiply the attention weights with this mask to zero out the attention scores above the diagonal:
tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],
[0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],
[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<MulBackward0>)However, if the mask were applied after softmax, like above, it would disrupt the probability distribution created by softmax
Softmax ensures that all output values sum to 1
Masking after softmax would require re-normalizing the outputs to sum to 1 again, which complicates the process and might lead to unintended effects
To make sure that the rows sum to 1, we can normalize the attention weights as follows:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<DivBackward0>)- While we are technically done with coding the causal attention mechanism now, let’s briefly look at a more efficient approach to achieve the same as above
- So, instead of zeroing out attention weights above the diagonal and renormalizing the results, we can mask the unnormalized attention scores above the diagonal with negative infinity before they enter the softmax function:
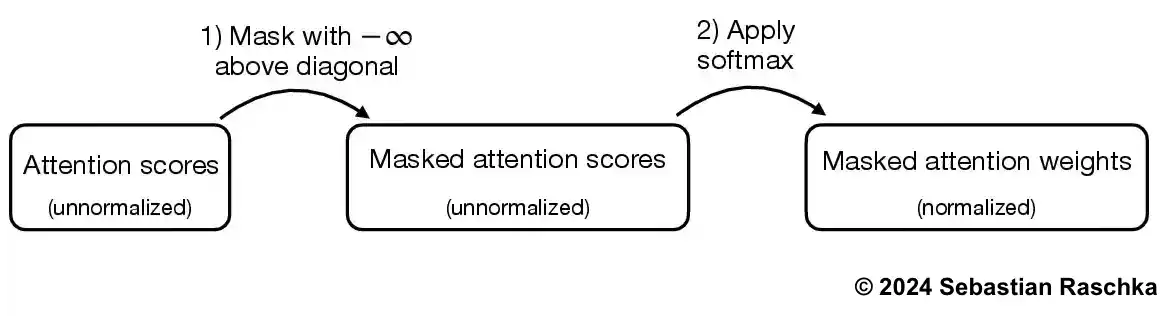
tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],
[0.4656, 0.1723, -inf, -inf, -inf, -inf],
[0.4594, 0.1703, 0.1731, -inf, -inf, -inf],
[0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],
[0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],
[0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],
grad_fn=<MaskedFillBackward0>)- As we can see below, now the attention weights in each row correctly sum to 1 again:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<SoftmaxBackward0>)3.5.2 Masking additional attention weights with dropout
In addition, we also apply dropout to reduce overfitting during training
Dropout can be applied in several places:
- for example, after computing the attention weights;
- or after multiplying the attention weights with the value vectors
Here, we will apply the dropout mask after computing the attention weights because it’s more common
Furthermore, in this specific example, we use a dropout rate of 50%, which means randomly masking out half of the attention weights. (When we train the GPT model later, we will use a lower dropout rate, such as 0.1 or 0.2
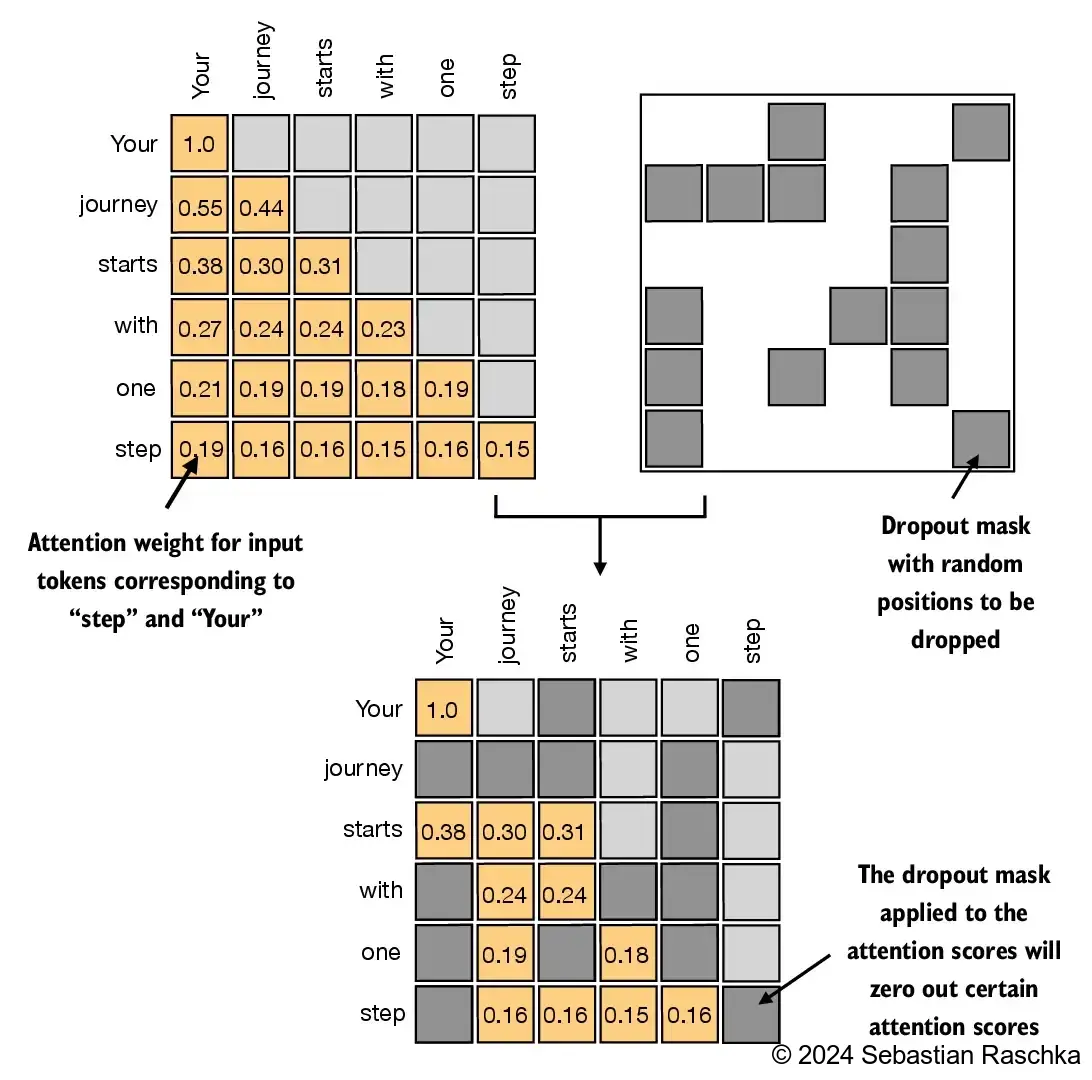
- If we apply a dropout rate of 0.5 (50%), the non-dropped values will be scaled accordingly by a factor of 1/0.5 = 2
- The scaling is calculated by the formula 1 / (1 -
dropout_rate)
tensor([[2., 2., 0., 2., 2., 0.],
[0., 0., 0., 2., 0., 2.],
[2., 2., 2., 2., 0., 2.],
[0., 2., 2., 0., 0., 2.],
[0., 2., 0., 2., 0., 2.],
[0., 2., 2., 2., 2., 0.]])tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],
[0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],
[0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],
[0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],
grad_fn=<MulBackward0>)- Note that the resulting dropout outputs may look different depending on your operating system; you can read more about this inconsistency here on the PyTorch issue tracker
3.5.3 Implementing a compact causal self-attention class
- Now, we are ready to implement a working implementation of self-attention, including the causal and dropout masks
- One more thing is to implement the code to handle batches consisting of more than one input so that our
CausalAttentionclass supports the batch outputs produced by the data loader we implemented in chapter 2 - For simplicity, to simulate such batch input, we duplicate the input text example:
torch.Size([2, 6, 3])tensor([[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]],
[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])- Note that dropout is only applied during training, not during inference
3.6 Extending single-head attention to multi-head attention
3.6.1 Stacking multiple single-head attention layers
Below is a summary of the self-attention implemented previously (causal and dropout masks not shown for simplicity)
This is also called single-head attention:
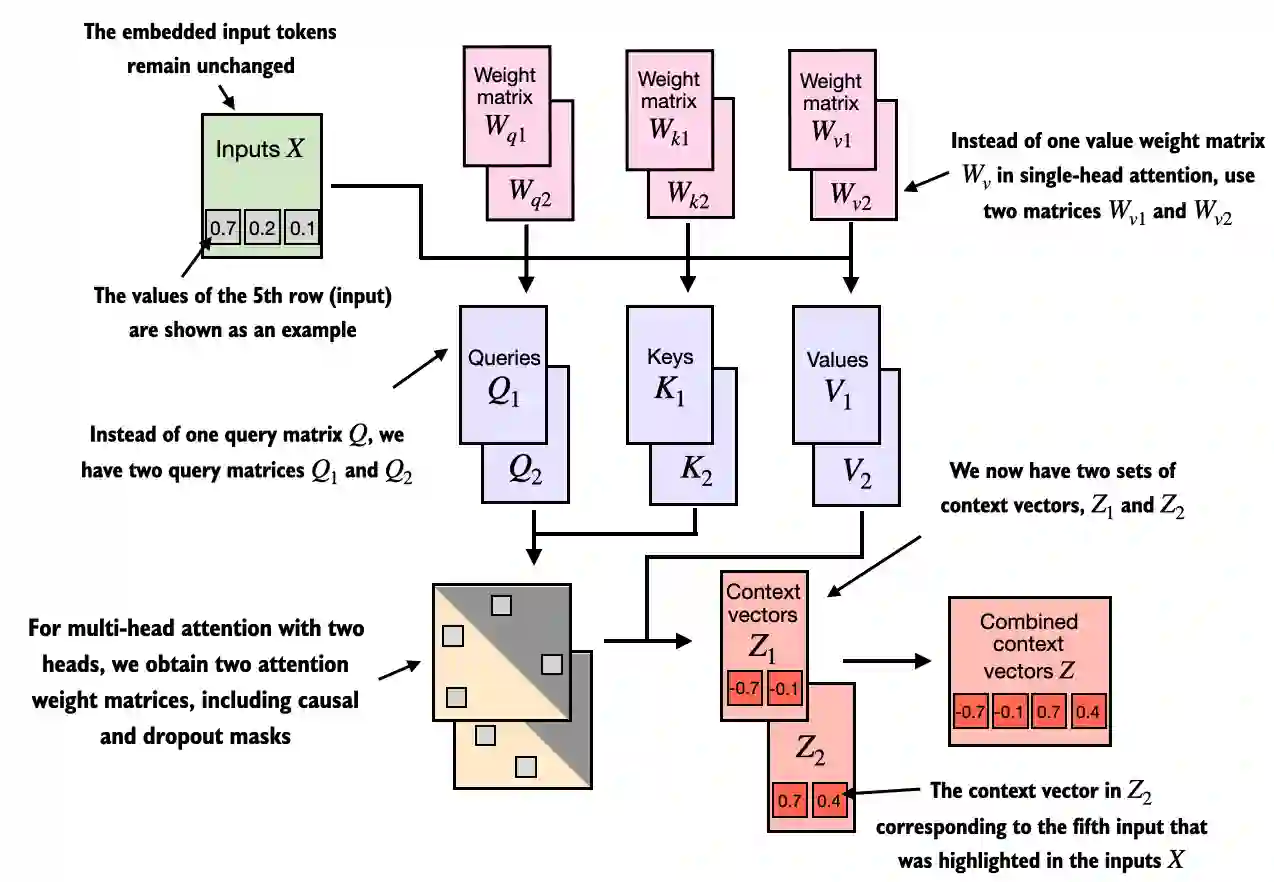
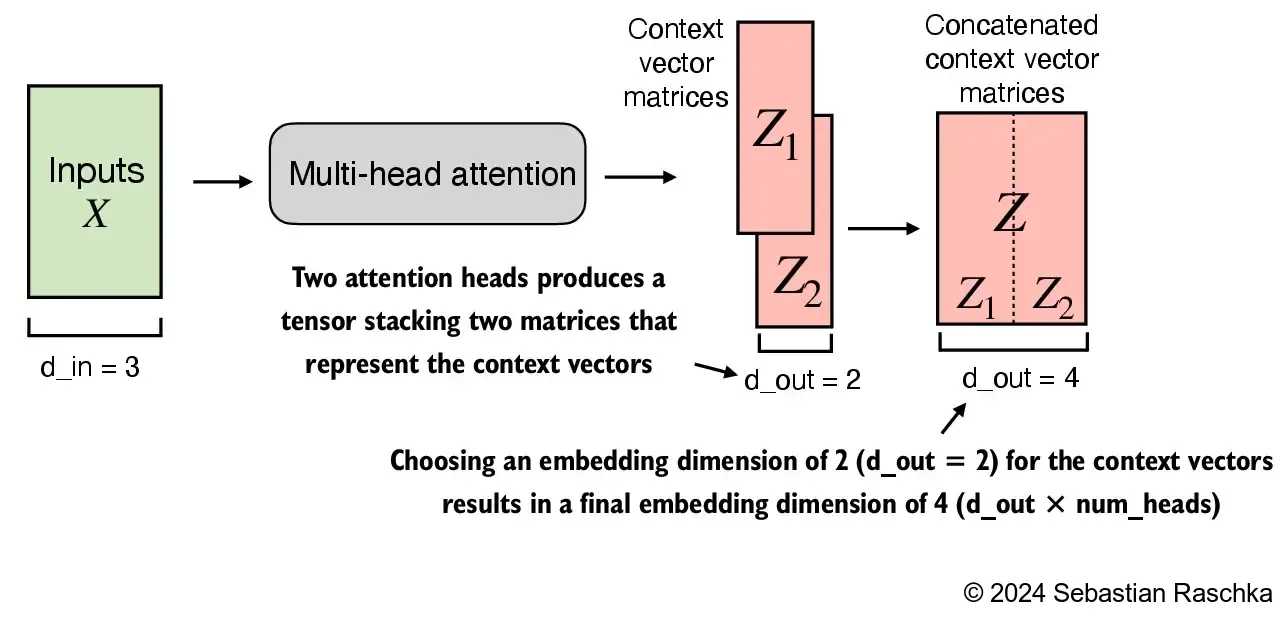
- We simply stack multiple single-head attention modules to obtain a multi-head attention module:
- The main idea behind multi-head attention is to run the attention mechanism multiple times (in parallel) with different, learned linear projections. This allows the model to jointly attend to information from different representation subspaces at different positions.
tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]],
[[-0.4519, 0.2216, 0.4772, 0.1063],
[-0.5874, 0.0058, 0.5891, 0.3257],
[-0.6300, -0.0632, 0.6202, 0.3860],
[-0.5675, -0.0843, 0.5478, 0.3589],
[-0.5526, -0.0981, 0.5321, 0.3428],
[-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=<CatBackward0>)
context_vecs.shape: torch.Size([2, 6, 4])- In the implementation above, the embedding dimension is 4, because we
d_out=2as the embedding dimension for the key, query, and value vectors as well as the context vector. And since we have 2 attention heads, we have the output embedding dimension 2*2=4
3.6.2 Implementing multi-head attention with weight splits
While the above is an intuitive and fully functional implementation of multi-head attention (wrapping the single-head attention
CausalAttentionimplementation from earlier), we can write a stand-alone class calledMultiHeadAttentionto achieve the sameWe don’t concatenate single attention heads for this stand-alone
MultiHeadAttentionclassInstead, we create single W_query, W_key, and W_value weight matrices and then split those into individual matrices for each attention head:
tensor([[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]],
[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])- Note that the above is essentially a rewritten version of
MultiHeadAttentionWrapperthat is more efficient - The resulting output looks a bit different since the random weight initializations differ, but both are fully functional implementations that can be used in the GPT class we will implement in the upcoming chapters
- Note that in addition, we added a linear projection layer (
self.out_proj) to theMultiHeadAttentionclass above. This is simply a linear transformation that doesn’t change the dimensions. It’s a standard convention to use such a projection layer in LLM implementation, but it’s not strictly necessary (recent research has shown that it can be removed without affecting the modeling performance; see the further reading section at the end of this chapter)
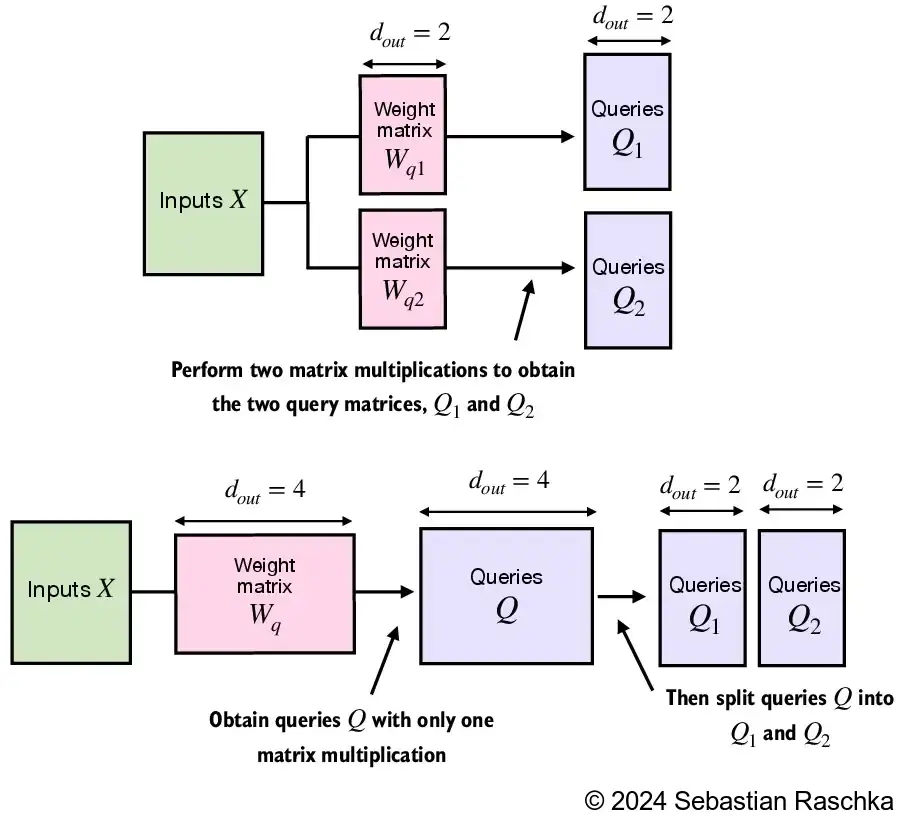
Note that if you are interested in a compact and efficient implementation of the above, you can also consider the
torch.nn.MultiheadAttentionclass in PyTorchSince the above implementation may look a bit complex at first glance, let’s look at what happens when executing
attn_scores = queries @ keys.transpose(2, 3):
tensor([[[[1.3208, 1.1631, 1.2879],
[1.1631, 2.2150, 1.8424],
[1.2879, 1.8424, 2.0402]],
[[0.4391, 0.7003, 0.5903],
[0.7003, 1.3737, 1.0620],
[0.5903, 1.0620, 0.9912]]]])In this case, the matrix multiplication implementation in PyTorch will handle the 4-dimensional input tensor so that the matrix multiplication is carried out between the 2 last dimensions (num_tokens, head_dim) and then repeated for the individual heads
For instance, the following becomes a more compact way to compute the matrix multiplication for each head separately:
First head:
tensor([[1.3208, 1.1631, 1.2879],
[1.1631, 2.2150, 1.8424],
[1.2879, 1.8424, 2.0402]])
Second head:
tensor([[0.4391, 0.7003, 0.5903],
[0.7003, 1.3737, 1.0620],
[0.5903, 1.0620, 0.9912]])Summary and takeaways
- See the ./multihead-attention.ipynb code notebook, which is a concise version of the data loader (chapter 2) plus the multi-head attention class that we implemented in this chapter and will need for training the GPT model in upcoming chapters
- You can find the exercise solutions in ./exercise-solutions.ipynb
4. Implementing a GPT model from Scratch To Generate Text
matplotlib version: 3.10.0
torch version: 2.6.0
tiktoken version: 0.9.0- In this chapter, we implement a GPT-like LLM architecture; the next chapter will focus on training this LLM
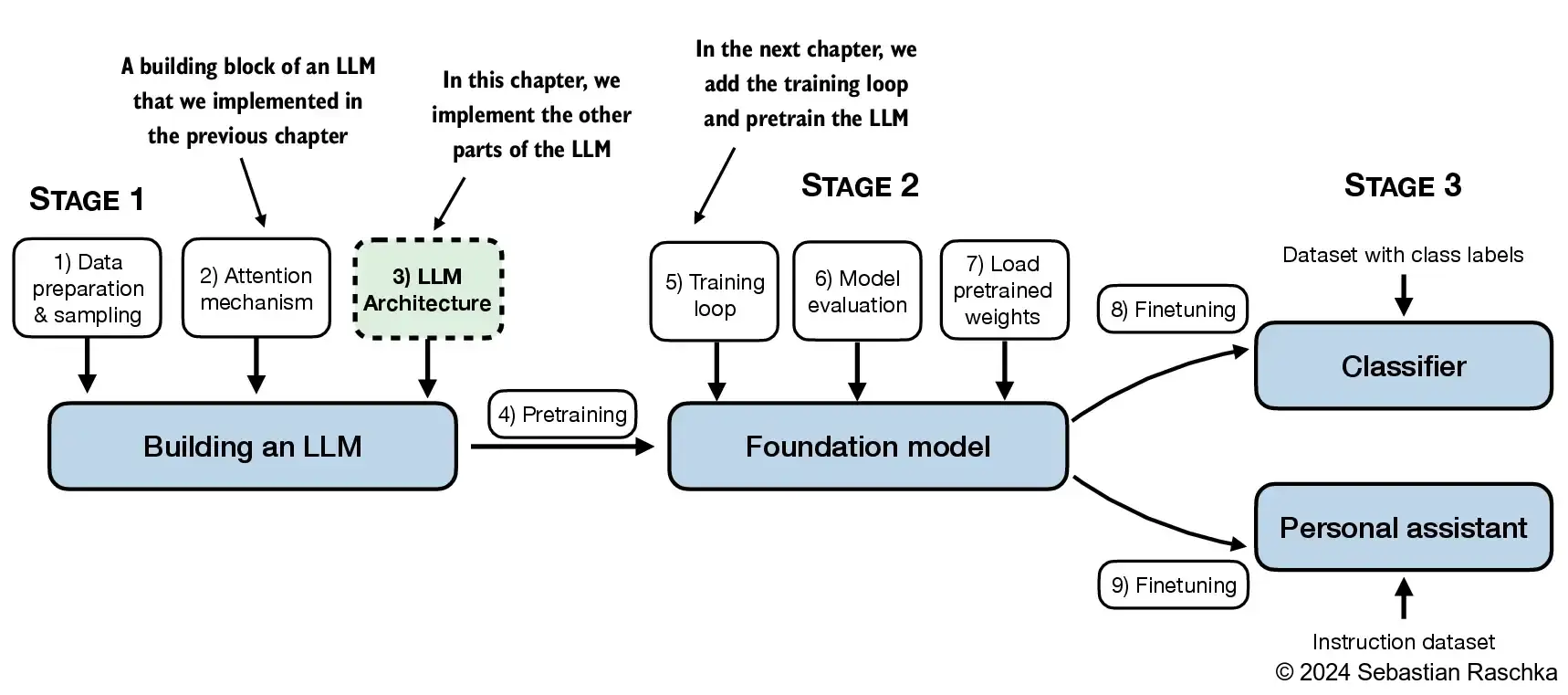
4.1 Coding an LLM architecture
- Chapter 1 discussed models like GPT and Llama, which generate words sequentially and are based on the decoder part of the original transformer architecture
- Therefore, these LLMs are often referred to as “decoder-like” LLMs
- Compared to conventional deep learning models, LLMs are larger, mainly due to their vast number of parameters, not the amount of code
- We’ll see that many elements are repeated in an LLM’s architecture
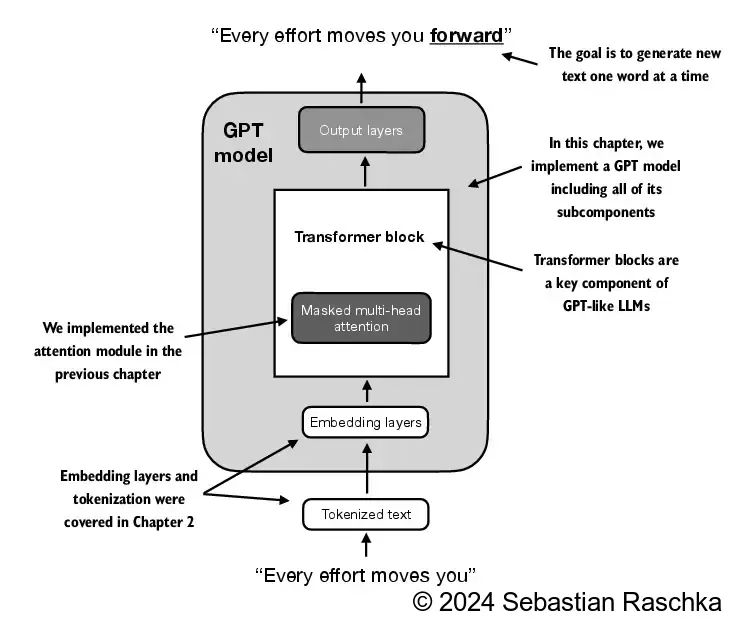
In previous chapters, we used small embedding dimensions for token inputs and outputs for ease of illustration, ensuring they fit on a single page
In this chapter, we consider embedding and model sizes akin to a small GPT-2 model
We’ll specifically code the architecture of the smallest GPT-2 model (124 million parameters), as outlined in Radford et al.’s Language Models are Unsupervised Multitask Learners (note that the initial report lists it as 117M parameters, but this was later corrected in the model weight repository)
Chapter 6 will show how to load pretrained weights into our implementation, which will be compatible with model sizes of 345, 762, and 1542 million parameters
Configuration details for the 124 million parameter GPT-2 model include:
We use short variable names to avoid long lines of code later
"vocab_size"indicates a vocabulary size of 50,257 words, supported by the BPE tokenizer discussed in Chapter 2"context_length"represents the model’s maximum input token count, as enabled by positional embeddings covered in Chapter 2"emb_dim"is the embedding size for token inputs, converting each input token into a 768-dimensional vector"n_heads"is the number of attention heads in the multi-head attention mechanism implemented in Chapter 3"n_layers"is the number of transformer blocks within the model, which we’ll implement in upcoming sections"drop_rate"is the dropout mechanism’s intensity, discussed in Chapter 3; 0.1 means dropping 10% of hidden units during training to mitigate overfitting"qkv_bias"decides if theLinearlayers in the multi-head attention mechanism (from Chapter 3) should include a bias vector when computing query (Q), key (K), and value (V) tensors; we’ll disable this option, which is standard practice in modern LLMs; however, we’ll revisit this later when loading pretrained GPT-2 weights from OpenAI into our reimplementation in chapter 5
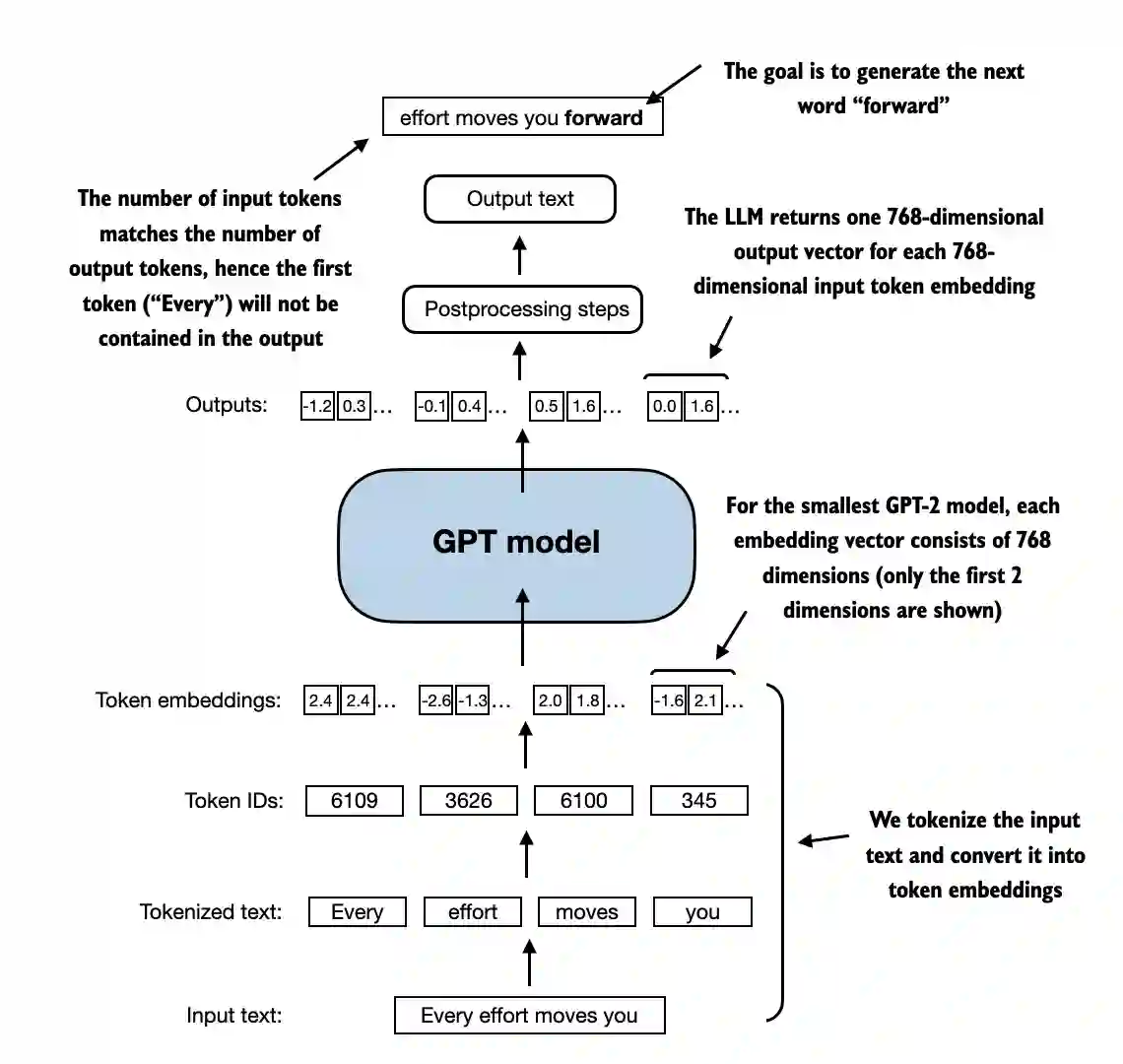
tensor([[6109, 3626, 6100, 345],
[6109, 1110, 6622, 257]])Output shape: torch.Size([2, 4, 50257])
tensor([[[-1.2034, 0.3201, -0.7130, ..., -1.5548, -0.2390, -0.4667],
[-0.1192, 0.4539, -0.4432, ..., 0.2392, 1.3469, 1.2430],
[ 0.5307, 1.6720, -0.4695, ..., 1.1966, 0.0111, 0.5835],
[ 0.0139, 1.6754, -0.3388, ..., 1.1586, -0.0435, -1.0400]],
[[-1.0908, 0.1798, -0.9484, ..., -1.6047, 0.2439, -0.4530],
[-0.7860, 0.5581, -0.0610, ..., 0.4835, -0.0077, 1.6621],
[ 0.3567, 1.2698, -0.6398, ..., -0.0162, -0.1296, 0.3717],
[-0.2407, -0.7349, -0.5102, ..., 2.0057, -0.3694, 0.1814]]],
grad_fn=<UnsafeViewBackward0>)Note
- If you are running this code on Windows or Linux, the resulting values above may look like as follows:
Output shape: torch.Size([2, 4, 50257])
tensor([[[-0.9289, 0.2748, -0.7557, ..., -1.6070, 0.2702, -0.5888],
[-0.4476, 0.1726, 0.5354, ..., -0.3932, 1.5285, 0.8557],
[ 0.5680, 1.6053, -0.2155, ..., 1.1624, 0.1380, 0.7425],
[ 0.0447, 2.4787, -0.8843, ..., 1.3219, -0.0864, -0.5856]],
[[-1.5474, -0.0542, -1.0571, ..., -1.8061, -0.4494, -0.6747],
[-0.8422, 0.8243, -0.1098, ..., -0.1434, 0.2079, 1.2046],
[ 0.1355, 1.1858, -0.1453, ..., 0.0869, -0.1590, 0.1552],
[ 0.1666, -0.8138, 0.2307, ..., 2.5035, -0.3055, -0.3083]]],
grad_fn=<UnsafeViewBackward0>)- Since these are just random numbers, this is not a reason for concern, and you can proceed with the remainder of the chapter without issues
- One possible reason for this discrepancy is the differing behavior of
nn.Dropoutacross operating systems, depending on how PyTorch was compiled, as discussed here on the PyTorch issue tracker
4.2 Normalizing activations with layer normalization
- Layer normalization, also known as LayerNorm (Ba et al. 2016), centers the activations of a neural network layer around a mean of 0 and normalizes their variance to 1
- This stabilizes training and enables faster convergence to effective weights
- Layer normalization is applied both before and after the multi-head attention module within the transformer block, which we will implement later; it’s also applied before the final output layer
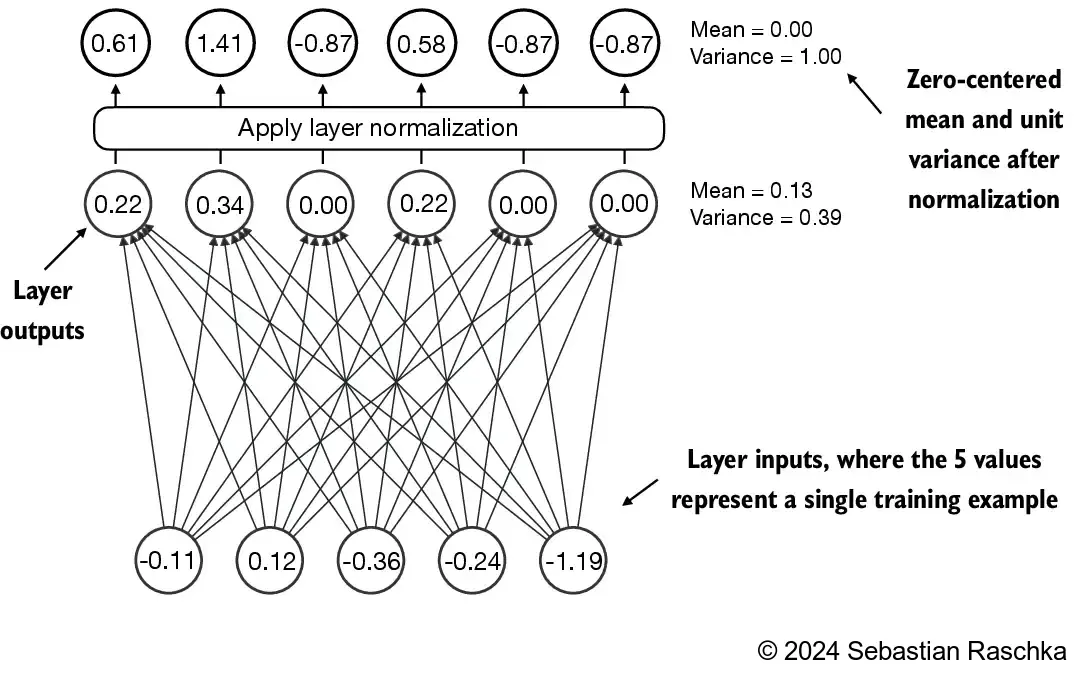
- Let’s see how layer normalization works by passing a small input sample through a simple neural network layer:
tensor([[0.2260, 0.3470, 0.0000, 0.2216, 0.0000, 0.0000],
[0.2133, 0.2394, 0.0000, 0.5198, 0.3297, 0.0000]],
grad_fn=<ReluBackward0>)- Let’s compute the mean and variance for each of the 2 inputs above:
Mean:
tensor([[0.1324],
[0.2170]], grad_fn=<MeanBackward1>)
Variance:
tensor([[0.0231],
[0.0398]], grad_fn=<VarBackward0>)- The normalization is applied to each of the two inputs (rows) independently; using dim=-1 applies the calculation across the last dimension (in this case, the feature dimension) instead of the row dimension
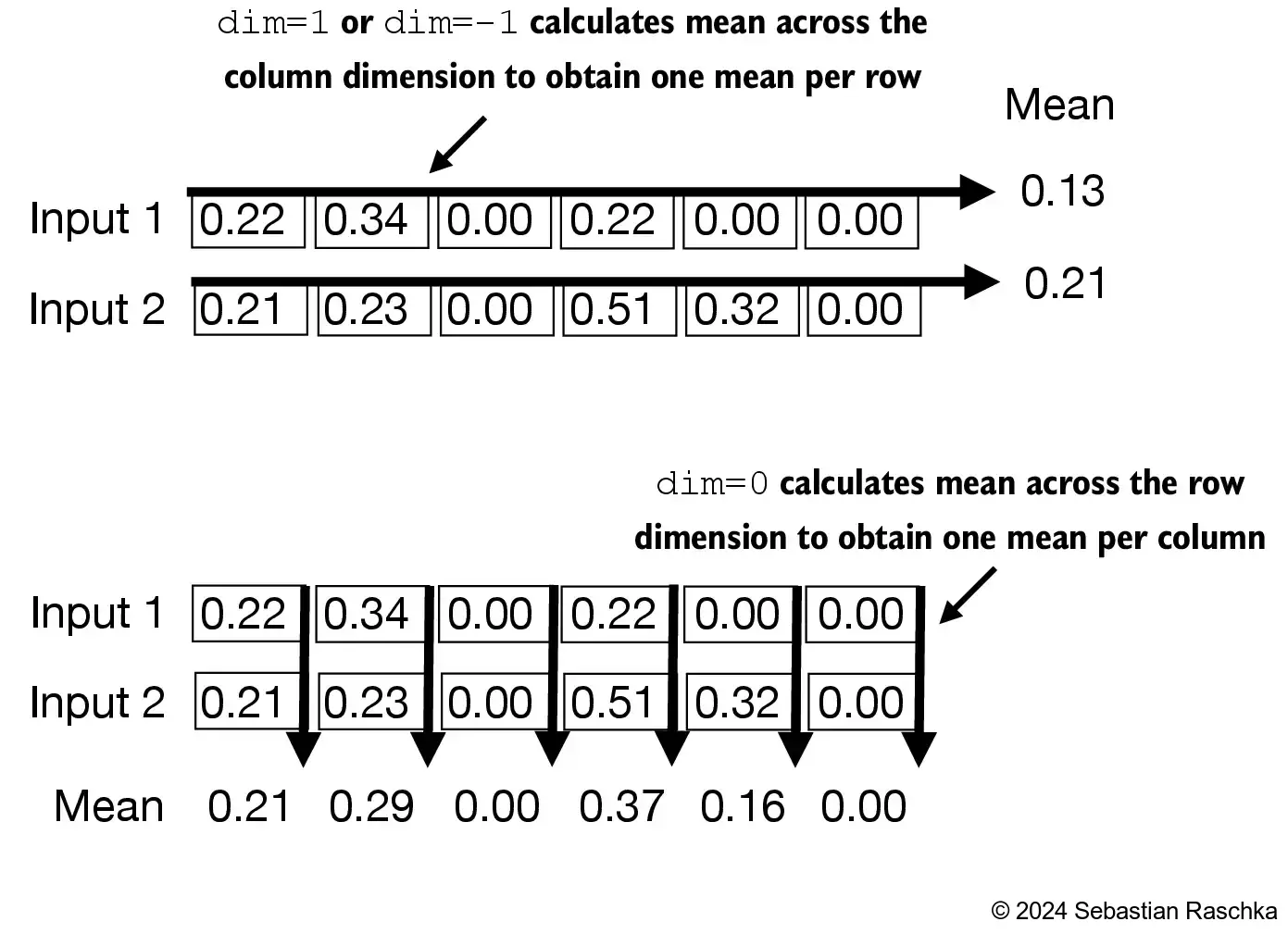
- Subtracting the mean and dividing by the square-root of the variance (standard deviation) centers the inputs to have a mean of 0 and a variance of 1 across the column (feature) dimension:
Normalized layer outputs:
tensor([[ 0.6159, 1.4126, -0.8719, 0.5872, -0.8719, -0.8719],
[-0.0189, 0.1121, -1.0876, 1.5173, 0.5647, -1.0876]],
grad_fn=<DivBackward0>)
Mean:
tensor([[-5.9605e-08],
[ 1.9868e-08]], grad_fn=<MeanBackward1>)
Variance:
tensor([[1.0000],
[1.0000]], grad_fn=<VarBackward0>)- Each input is centered at 0 and has a unit variance of 1; to improve readability, we can disable PyTorch’s scientific notation:
Mean:
tensor([[ -0.0000],
[ 0.0000]], grad_fn=<MeanBackward1>)
Variance:
tensor([[1.0000],
[1.0000]], grad_fn=<VarBackward0>)- Above, we normalized the features of each input
- Now, using the same idea, we can implement a
LayerNormclass:
Scale and shift
- Note that in addition to performing the normalization by subtracting the mean and dividing by the variance, we added two trainable parameters, a
scaleand ashiftparameter - The initial
scale(multiplying by 1) andshift(adding 0) values don’t have any effect; however,scaleandshiftare trainable parameters that the LLM automatically adjusts during training if it is determined that doing so would improve the model’s performance on its training task - This allows the model to learn appropriate scaling and shifting that best suit the data it is processing
- Note that we also add a smaller value (
eps) before computing the square root of the variance; this is to avoid division-by-zero errors if the variance is 0
Biased variance - In the variance calculation above, setting unbiased=False means using the formula \(\frac{\sum_i (x_i - \bar{x})^2}{n}\) to compute the variance where n is the sample size (here, the number of features or columns); this formula does not include Bessel’s correction (which uses n-1 in the denominator), thus providing a biased estimate of the variance - For LLMs, where the embedding dimension n is very large, the difference between using n and n-1 is negligible - However, GPT-2 was trained with a biased variance in the normalization layers, which is why we also adopted this setting for compatibility reasons with the pretrained weights that we will load in later chapters
- Let’s now try out
LayerNormin practice:
Mean:
tensor([[ -0.0000],
[ 0.0000]], grad_fn=<MeanBackward1>)
Variance:
tensor([[1.0000],
[1.0000]], grad_fn=<VarBackward0>)
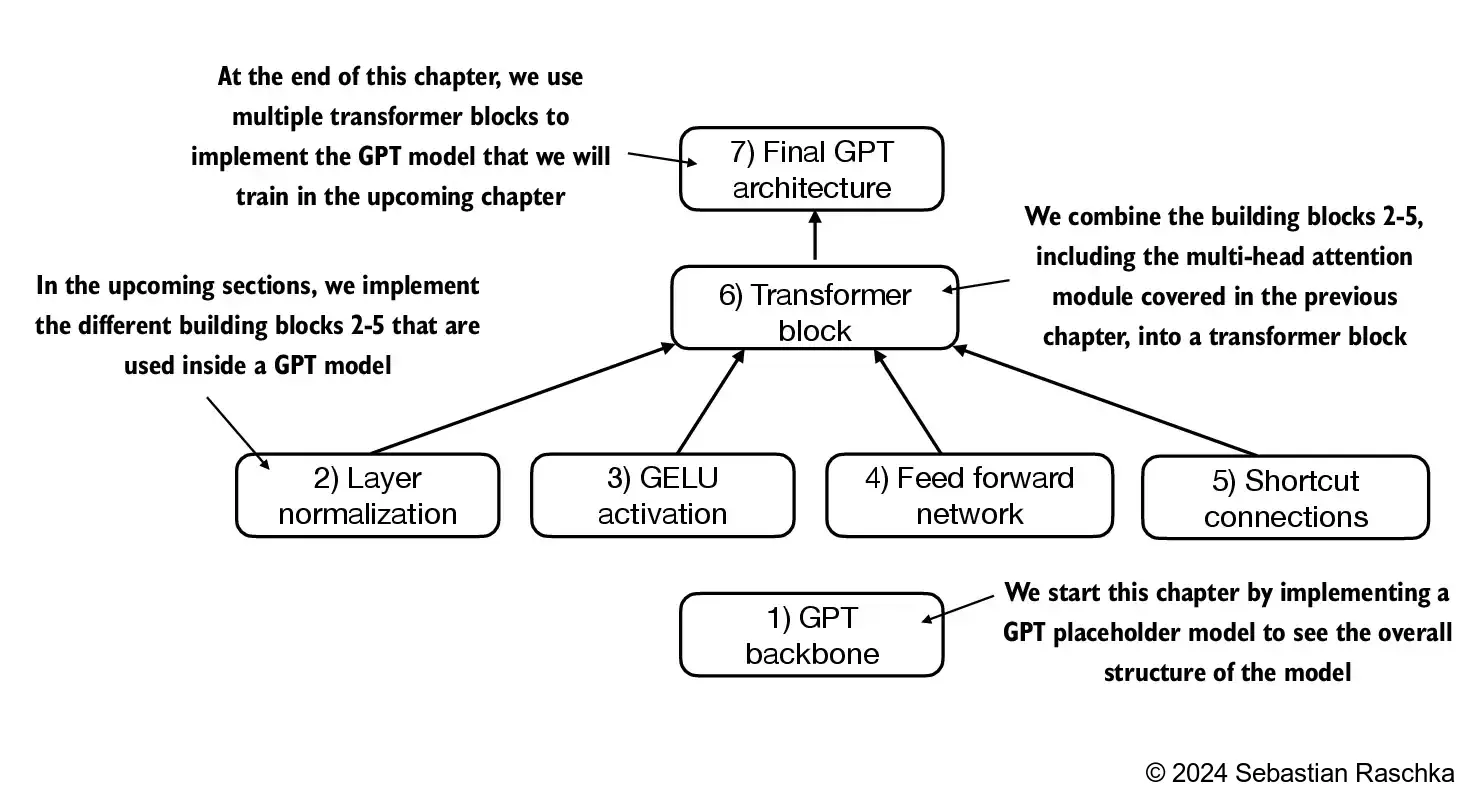
4.3 Implementing a feed forward network with GELU activations
In this section, we implement a small neural network submodule that is used as part of the transformer block in LLMs
We start with the activation function
In deep learning, ReLU (Rectified Linear Unit) activation functions are commonly used due to their simplicity and effectiveness in various neural network architectures
In LLMs, various other types of activation functions are used beyond the traditional ReLU; two notable examples are GELU (Gaussian Error Linear Unit) and SwiGLU (Swish-Gated Linear Unit)
GELU and SwiGLU are more complex, smooth activation functions incorporating Gaussian and sigmoid-gated linear units, respectively, offering better performance for deep learning models, unlike the simpler, piecewise linear function of ReLU
GELU (Hendrycks and Gimpel 2016) can be implemented in several ways; the exact version is defined as GELU(x)=x⋅Φ(x), where Φ(x) is the cumulative distribution function of the standard Gaussian distribution.
In practice, it’s common to implement a computationally cheaper approximation: \(\text{GELU}(x) \approx 0.5 \cdot x \cdot \left(1 + \tanh\left[\sqrt{\frac{2}{\pi}} \cdot \left(x + 0.044715 \cdot x^3\right)\right]\right)\) (the original GPT-2 model was also trained with this approximation)
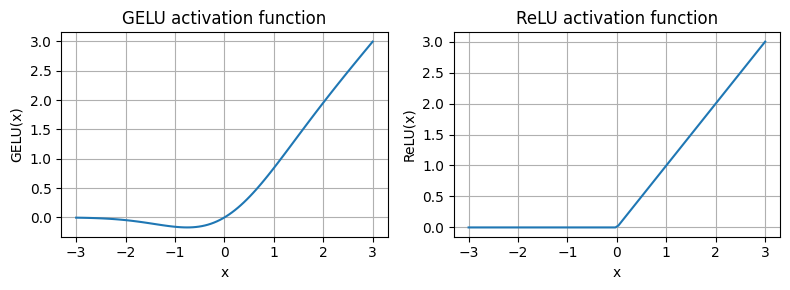
As we can see, ReLU is a piecewise linear function that outputs the input directly if it is positive; otherwise, it outputs zero
GELU is a smooth, non-linear function that approximates ReLU but with a non-zero gradient for negative values (except at approximately -0.75)
Next, let’s implement the small neural network module,
FeedForward, that we will be using in the LLM’s transformer block later:
768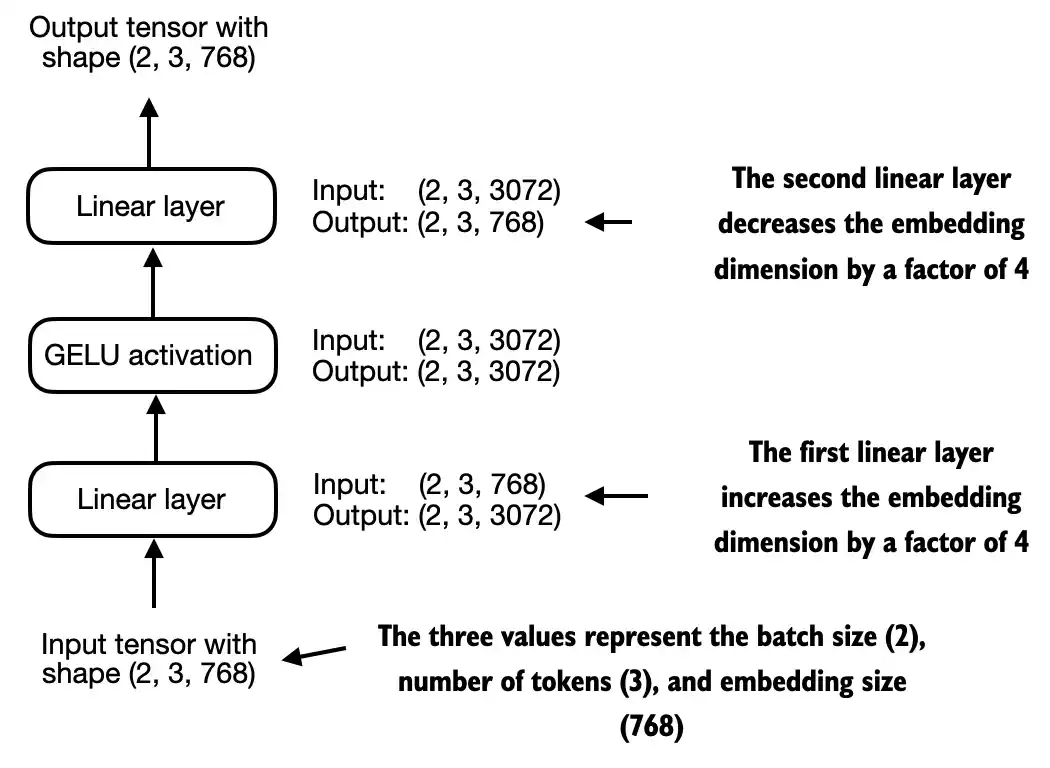
torch.Size([2, 3, 768])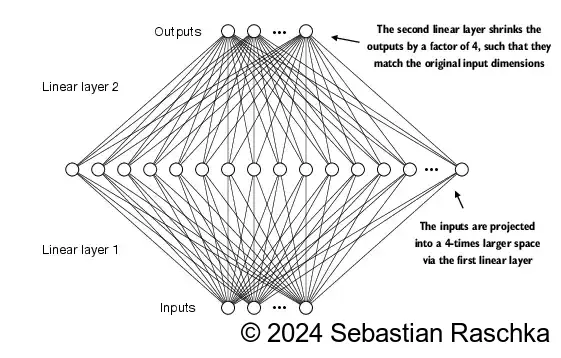
4.4 Adding shortcut connections
- Next, let’s talk about the concept behind shortcut connections, also called skip or residual connections
- Originally, shortcut connections were proposed in deep networks for computer vision (residual networks) to mitigate vanishing gradient problems
- A shortcut connection creates an alternative shorter path for the gradient to flow through the network
- This is achieved by adding the output of one layer to the output of a later layer, usually skipping one or more layers in between
- Let’s illustrate this idea with a small example network:
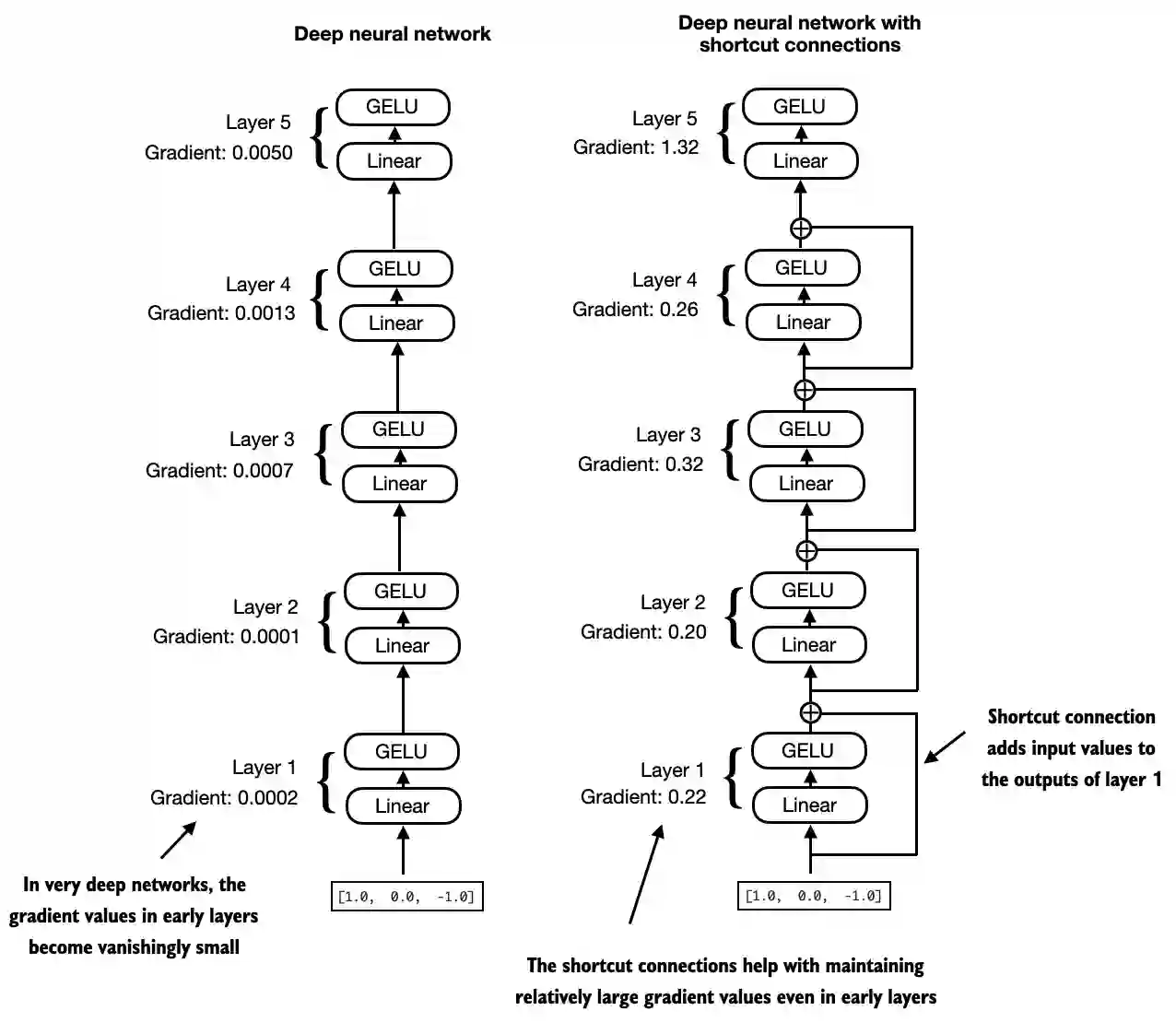
In code, it looks like this:
Let’s print the gradient values first without shortcut connections:
layers.0.0.weight has gradient mean of 0.00020173587836325169
layers.1.0.weight has gradient mean of 0.00012011159560643137
layers.2.0.weight has gradient mean of 0.0007152039906941354
layers.3.0.weight has gradient mean of 0.0013988736318424344
layers.4.0.weight has gradient mean of 0.005049645435065031- Next, let’s print the gradient values with shortcut connections:
layers.0.0.weight has gradient mean of 0.22169792652130127
layers.1.0.weight has gradient mean of 0.20694106817245483
layers.2.0.weight has gradient mean of 0.32896995544433594
layers.3.0.weight has gradient mean of 0.2665732204914093
layers.4.0.weight has gradient mean of 1.3258540630340576- As we can see based on the output above, shortcut connections prevent the gradients from vanishing in the early layers (towards
layer.0) - We will use this concept of a shortcut connection next when we implement a transformer block
4.5 Connecting attention and linear layers in a transformer block
- In this section, we now combine the previous concepts into a so-called transformer block
- A transformer block combines the causal multi-head attention module from the previous chapter with the linear layers, the feed forward neural network we implemented in an earlier section
- In addition, the transformer block also uses dropout and shortcut connections
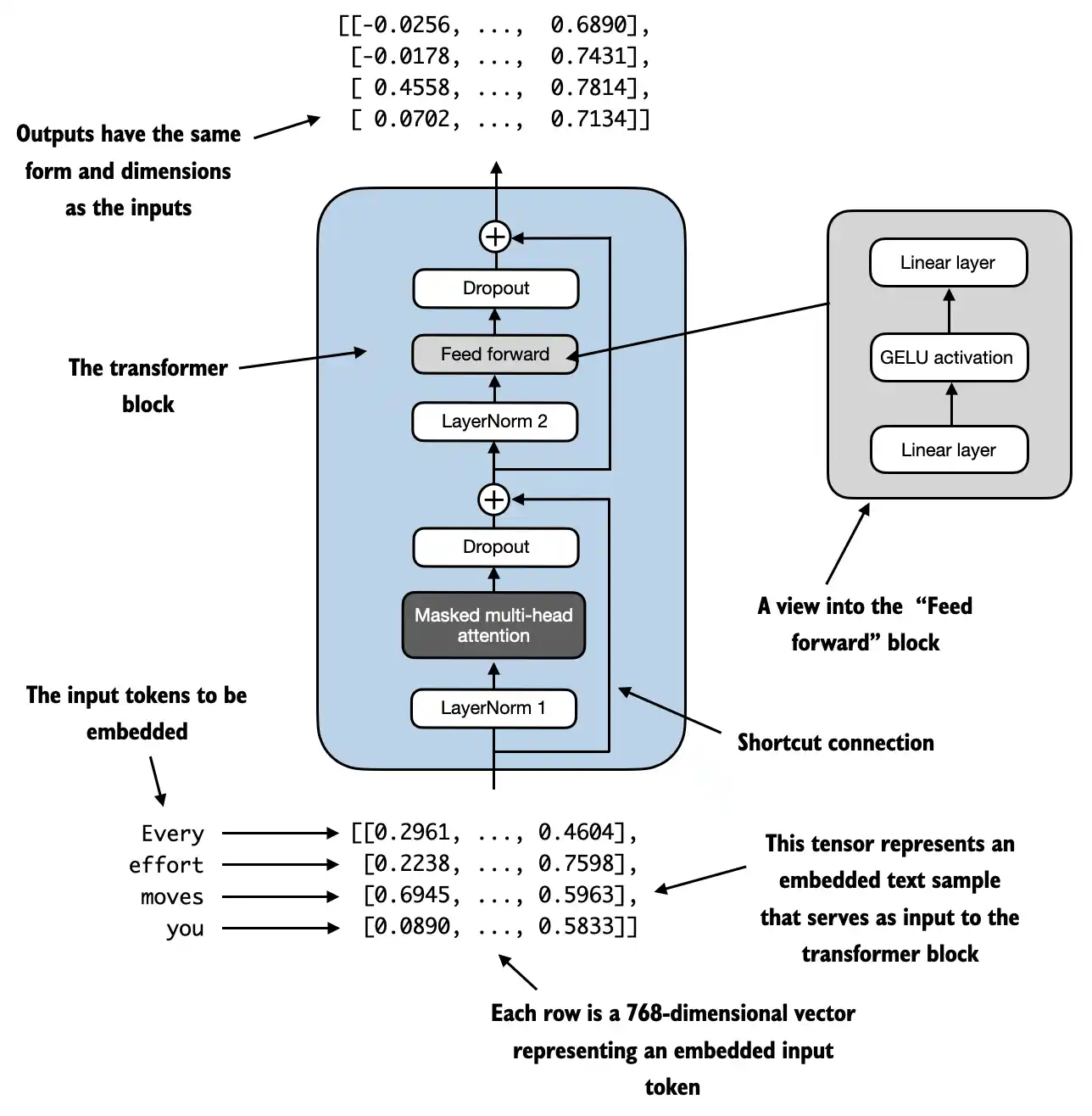
- Suppose we have 2 input samples with 6 tokens each, where each token is a 768-dimensional embedding vector; then this transformer block applies self-attention, followed by linear layers, to produce an output of similar size
- You can think of the output as an augmented version of the context vectors we discussed in the previous chapter
Input shape: torch.Size([2, 4, 768])
Output shape: torch.Size([2, 4, 768])
4.6 Coding the GPT model
- We are almost there: now let’s plug in the transformer block into the architecture we coded at the very beginning of this chapter so that we obtain a usable GPT architecture
- Note that the transformer block is repeated multiple times; in the case of the smallest 124M GPT-2 model, we repeat it 12 times:

The corresponding code implementation, where
cfg["n_layers"] = 12:Using the configuration of the 124M parameter model, we can now instantiate this GPT model with random initial weights as follows:
Input batch:
tensor([[6109, 3626, 6100, 345],
[6109, 1110, 6622, 257]])
Output shape: torch.Size([2, 4, 50257])
tensor([[[ 0.3613, 0.4222, -0.0711, ..., 0.3483, 0.4661, -0.2838],
[-0.1792, -0.5660, -0.9485, ..., 0.0477, 0.5181, -0.3168],
[ 0.7120, 0.0332, 0.1085, ..., 0.1018, -0.4327, -0.2553],
[-1.0076, 0.3418, -0.1190, ..., 0.7195, 0.4023, 0.0532]],
[[-0.2564, 0.0900, 0.0335, ..., 0.2659, 0.4454, -0.6806],
[ 0.1230, 0.3653, -0.2074, ..., 0.7705, 0.2710, 0.2246],
[ 1.0558, 1.0318, -0.2800, ..., 0.6936, 0.3205, -0.3178],
[-0.1565, 0.3926, 0.3288, ..., 1.2630, -0.1858, 0.0388]]],
grad_fn=<UnsafeViewBackward0>)- We will train this model in the next chapter
- However, a quick note about its size: we previously referred to it as a 124M parameter model; we can double check this number as follows:
Total number of parameters: 163,009,536- As we see above, this model has 163M, not 124M parameters; why?
- In the original GPT-2 paper, the researchers applied weight tying, which means that they reused the token embedding layer (
tok_emb) as the output layer, which means settingself.out_head.weight = self.tok_emb.weight - The token embedding layer projects the 50,257-dimensional one-hot encoded input tokens to a 768-dimensional embedding representation
- The output layer projects 768-dimensional embeddings back into a 50,257-dimensional representation so that we can convert these back into words (more about that in the next section)
- So, the embedding and output layer have the same number of weight parameters, as we can see based on the shape of their weight matrices
- However, a quick note about its size: we previously referred to it as a 124M parameter model; we can double check this number as follows:
Token embedding layer shape: torch.Size([50257, 768])
Output layer shape: torch.Size([50257, 768])- In the original GPT-2 paper, the researchers reused the token embedding matrix as an output matrix
- Correspondingly, if we subtracted the number of parameters of the output layer, we’d get a 124M parameter model:
Number of trainable parameters considering weight tying: 124,412,160- In practice, I found it easier to train the model without weight-tying, which is why we didn’t implement it here
- However, we will revisit and apply this weight-tying idea later when we load the pretrained weights in chapter 5
- Lastly, we can compute the memory requirements of the model as follows, which can be a helpful reference point:
Total size of the model: 621.83 MBExercise: you can try the following other configurations, which are referenced in the GPT-2 paper, as well.
- GPT2-small (the 124M configuration we already implemented):
- “emb_dim” = 768
- “n_layers” = 12
- “n_heads” = 12
- GPT2-medium:
- “emb_dim” = 1024
- “n_layers” = 24
- “n_heads” = 16
- GPT2-large:
- “emb_dim” = 1280
- “n_layers” = 36
- “n_heads” = 20
- GPT2-XL:
- “emb_dim” = 1600
- “n_layers” = 48
- “n_heads” = 25
- GPT2-small (the 124M configuration we already implemented):
4.7 Generating text
- LLMs like the GPT model we implemented above are used to generate one word at a time
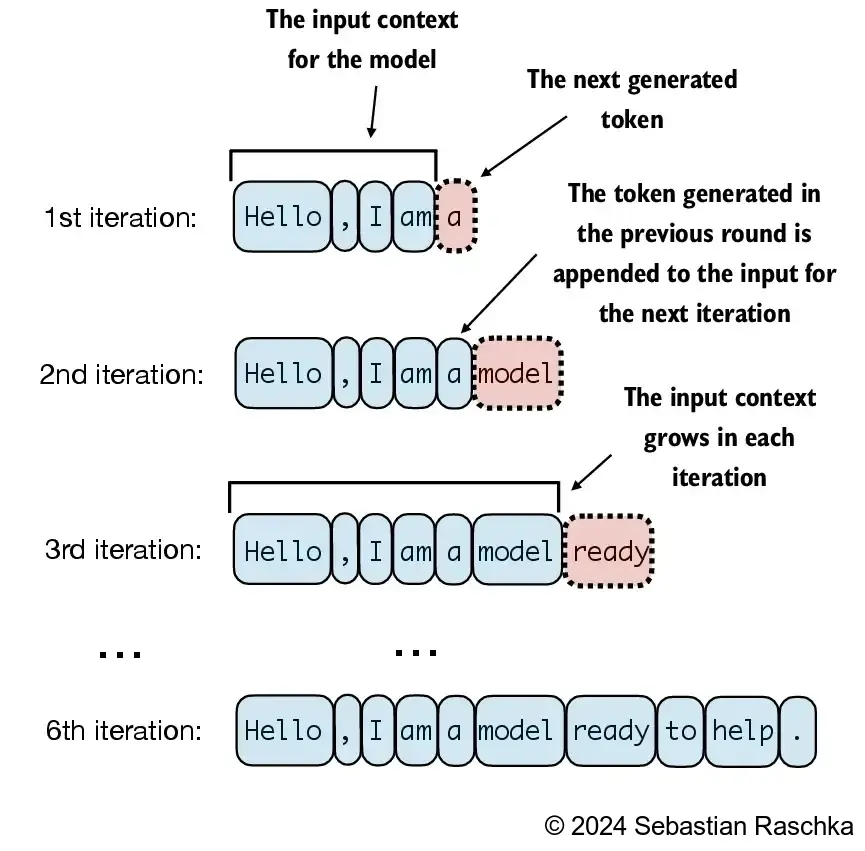
- The following
generate_text_simplefunction implements greedy decoding, which is a simple and fast method to generate text - In greedy decoding, at each step, the model chooses the word (or token) with the highest probability as its next output (the highest logit corresponds to the highest probability, so we technically wouldn’t even have to compute the softmax function explicitly)
- In the next chapter, we will implement a more advanced
generate_textfunction - The figure below depicts how the GPT model, given an input context, generates the next word token
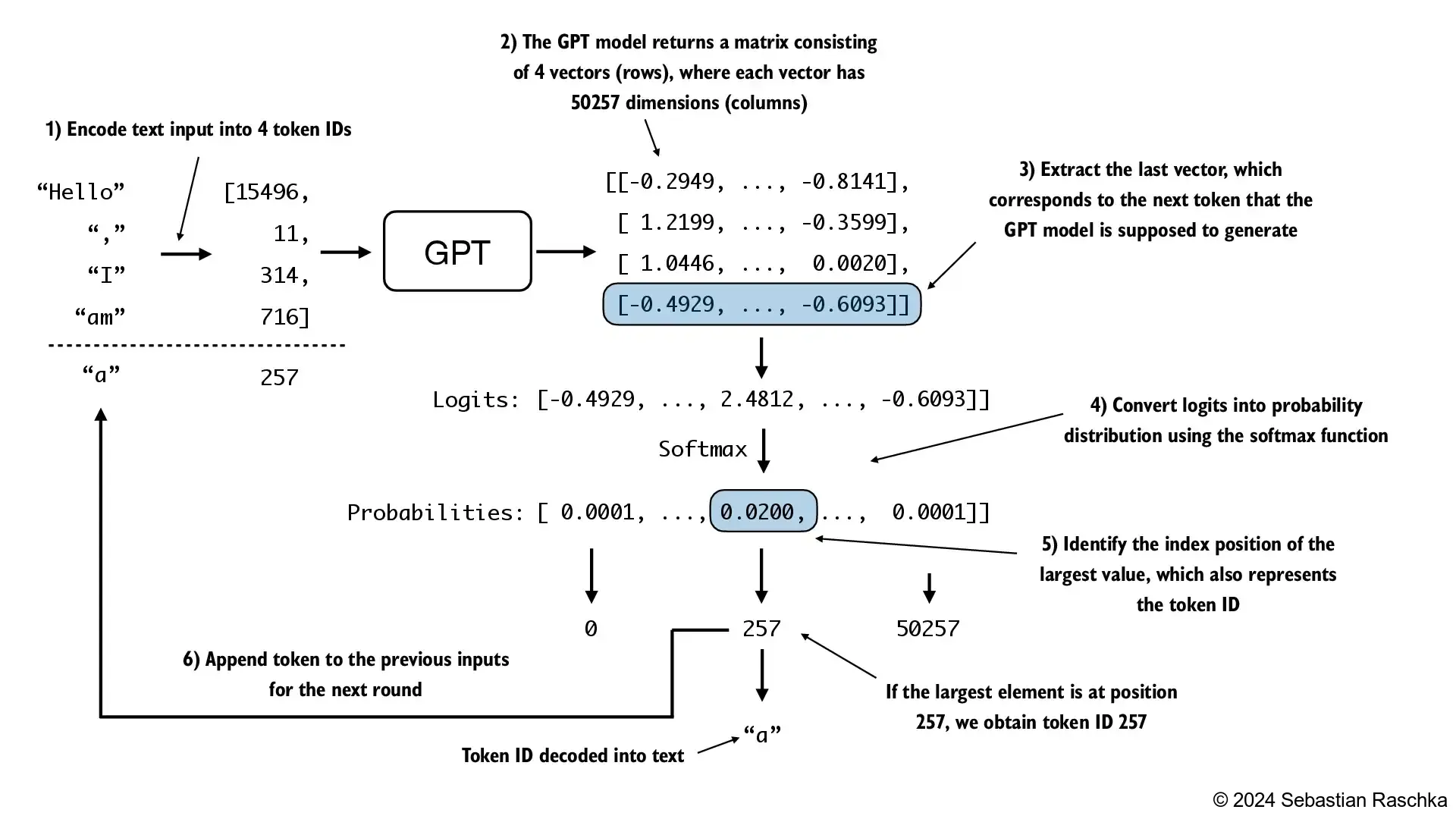
- The
generate_text_simpleabove implements an iterative process, where it creates one token at a time
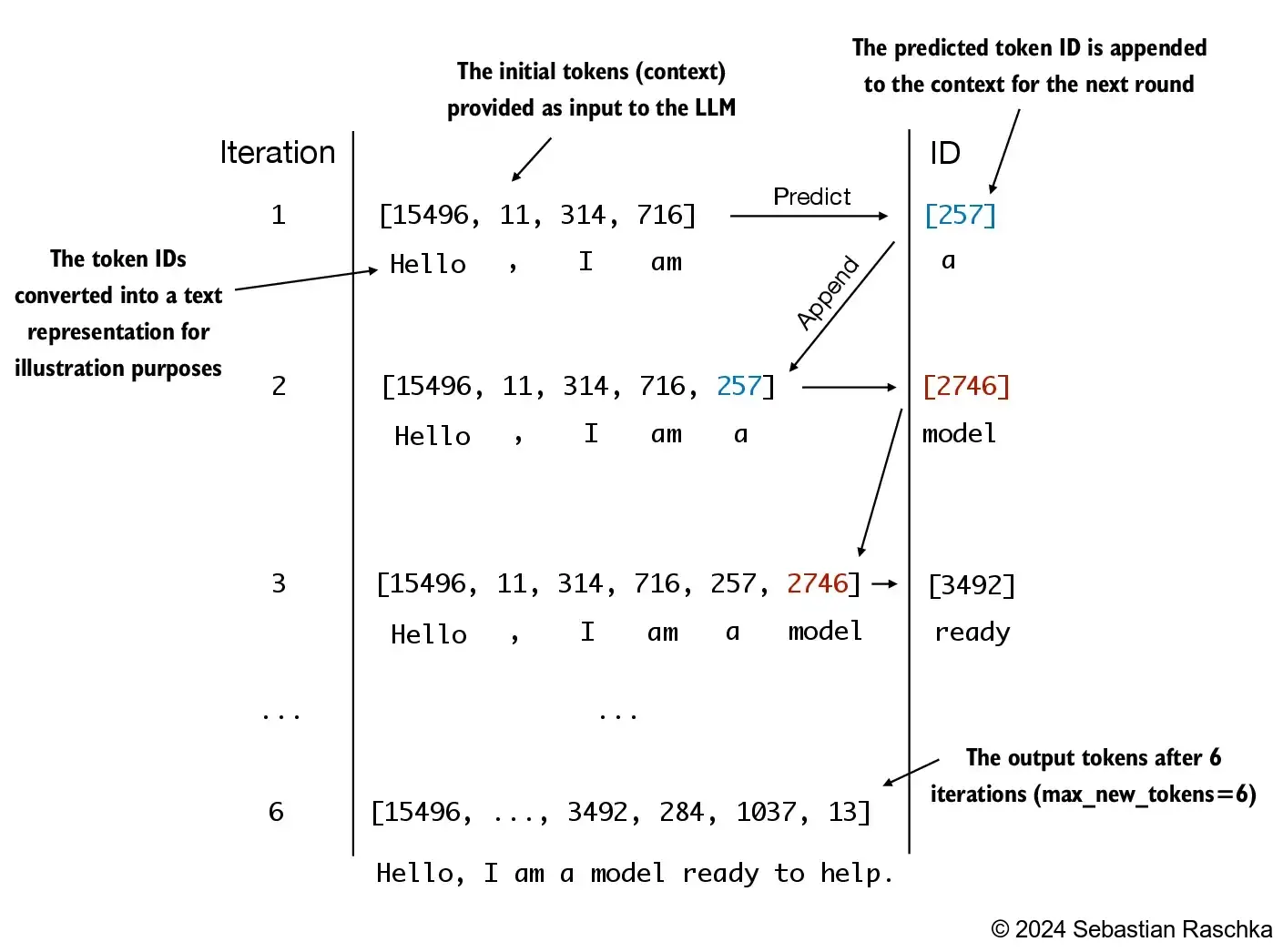
- Let’s prepare an input example:
encoded: [15496, 11, 314, 716]
encoded_tensor.shape: torch.Size([1, 4])Output: tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])
Output length: 10- Remove batch dimension and convert back into text:
Hello, I am Featureiman Byeswickattribute argue- Note that the model is untrained; hence the random output texts above
- We will train the model in the next chapter
Summary and takeaways
- See the ./gpt.py script, a self-contained script containing the GPT model we implement in this Jupyter notebook
- You can find the exercise solutions in ./exercise-solutions.ipynb
5. Pretraining on Unlabeled Data
Chapter 5: Pretraining on Unlabeled Data
from importlib.metadata import version
pkgs = ["matplotlib",
"numpy",
"tiktoken",
"torch",
"tensorflow" # For OpenAI's pretrained weights
]
for p in pkgs:
print(f"{p} version: {version(p)}")matplotlib version: 3.10.1
numpy version: 2.0.2
tiktoken version: 0.9.0
torch version: 2.6.0
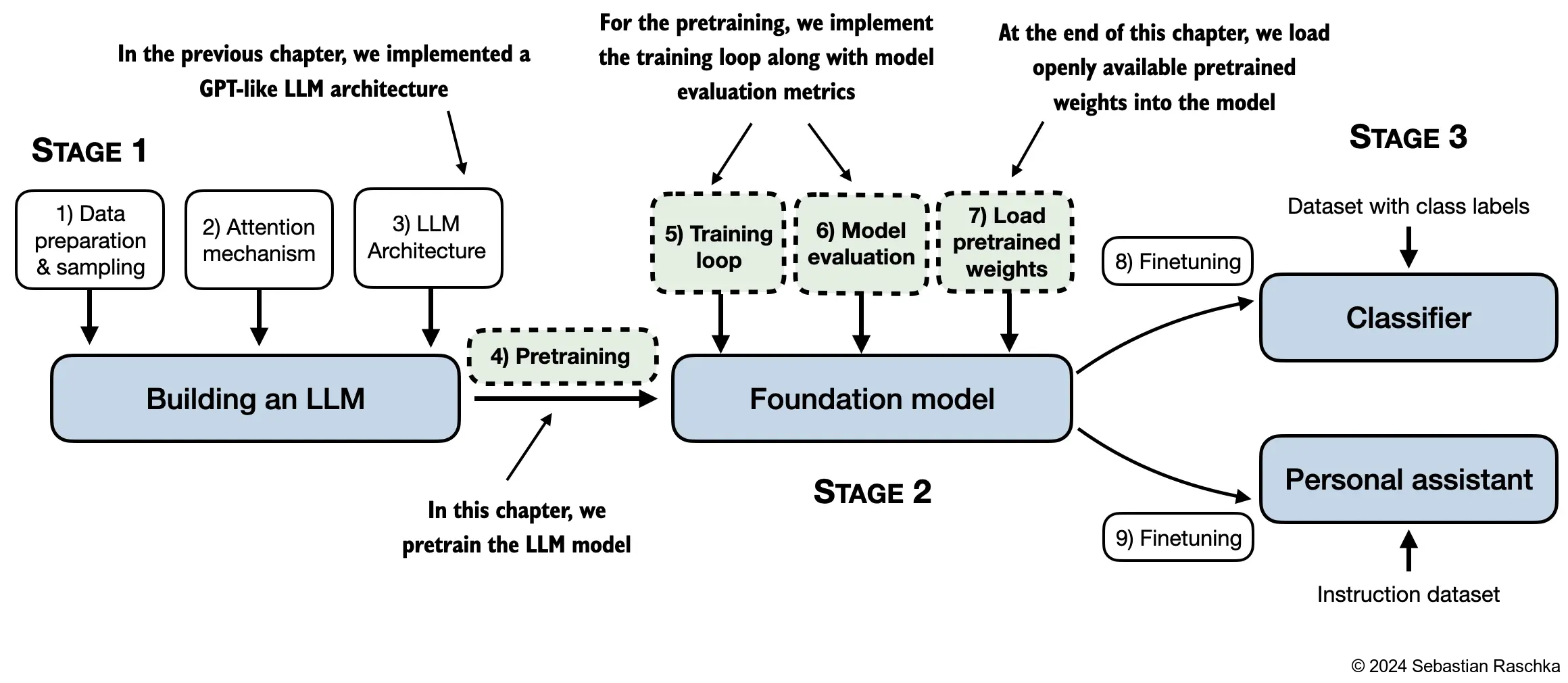
tensorflow version: 2.18.0- In this chapter, we implement the training loop and code for basic model evaluation to pretrain an LLM
- At the end of this chapter, we also load openly available pretrained weights from OpenAI into our model
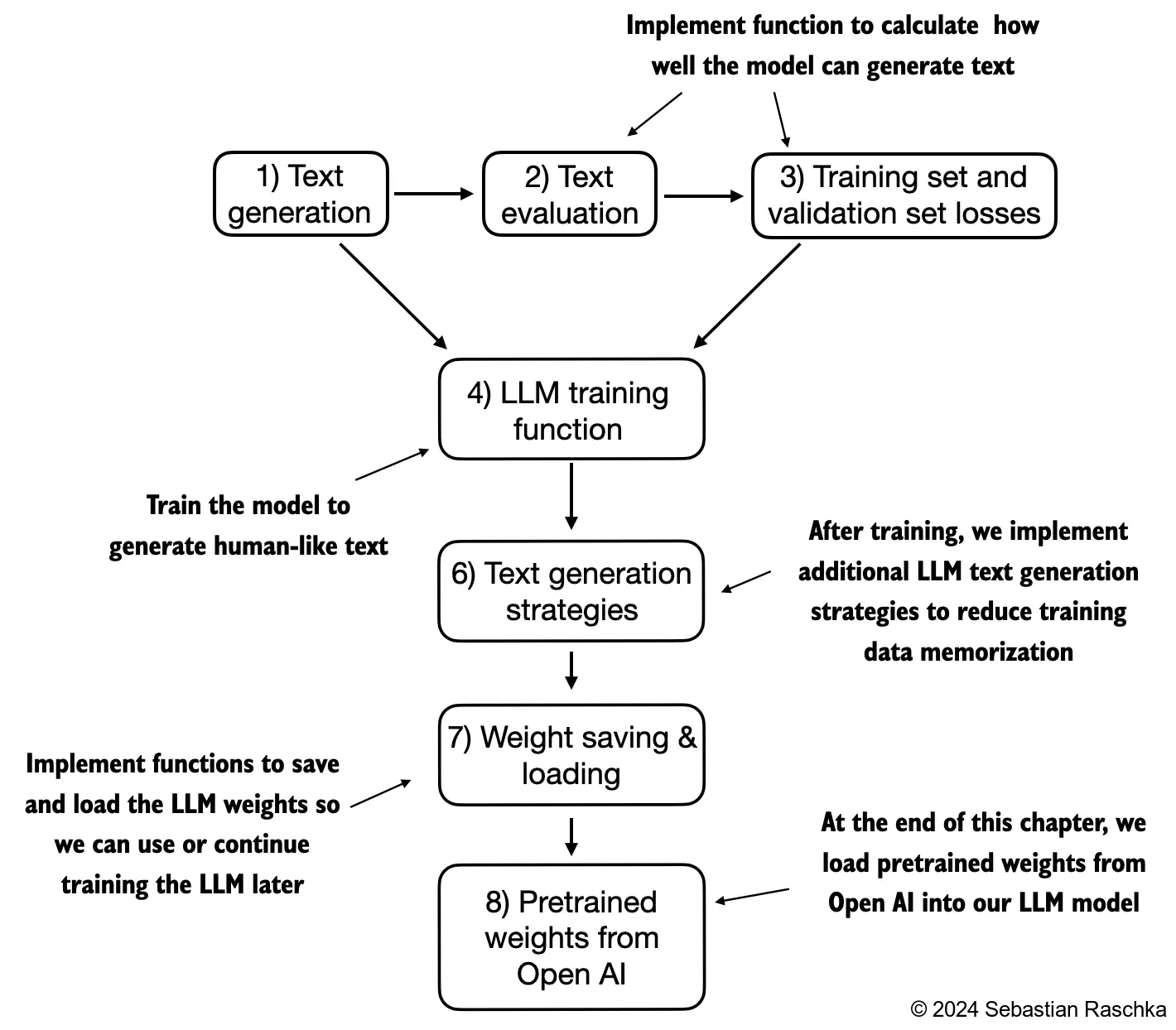
- The topics covered in this chapter are shown below
5.1 Evaluating generative text models
- We start this section with a brief recap of initializing a GPT model using the code from the previous chapter
- Then, we discuss basic evaluation metrics for LLMs
- Lastly, in this section, we apply these evaluation metrics to a training and validation dataset
5.1.1 Using GPT to generate text
- We initialize a GPT model using the code from the previous chapter
import torch
from previous_chapters import GPTModel
# If the `previous_chapters.py` file is not available locally,
# you can import it from the `llms-from-scratch` PyPI package.
# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg
# E.g.,
# from llms_from_scratch.ch04 import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval(); # Disable dropout during inference- We use dropout of 0.1 above, but it’s relatively common to train LLMs without dropout nowadays
- Modern LLMs also don’t use bias vectors in the
nn.Linearlayers for the query, key, and value matrices (unlike earlier GPT models), which is achieved by setting"qkv_bias": False - We reduce the context length (
context_length) of only 256 tokens to reduce the computational resource requirements for training the model, whereas the original 124 million parameter GPT-2 model used 1024 tokens- This is so that more readers will be able to follow and execute the code examples on their laptop computer
- However, please feel free to increase the
context_lengthto 1024 tokens (this would not require any code changes) - We will also load a model with a 1024
context_lengthlater from pretrained weights
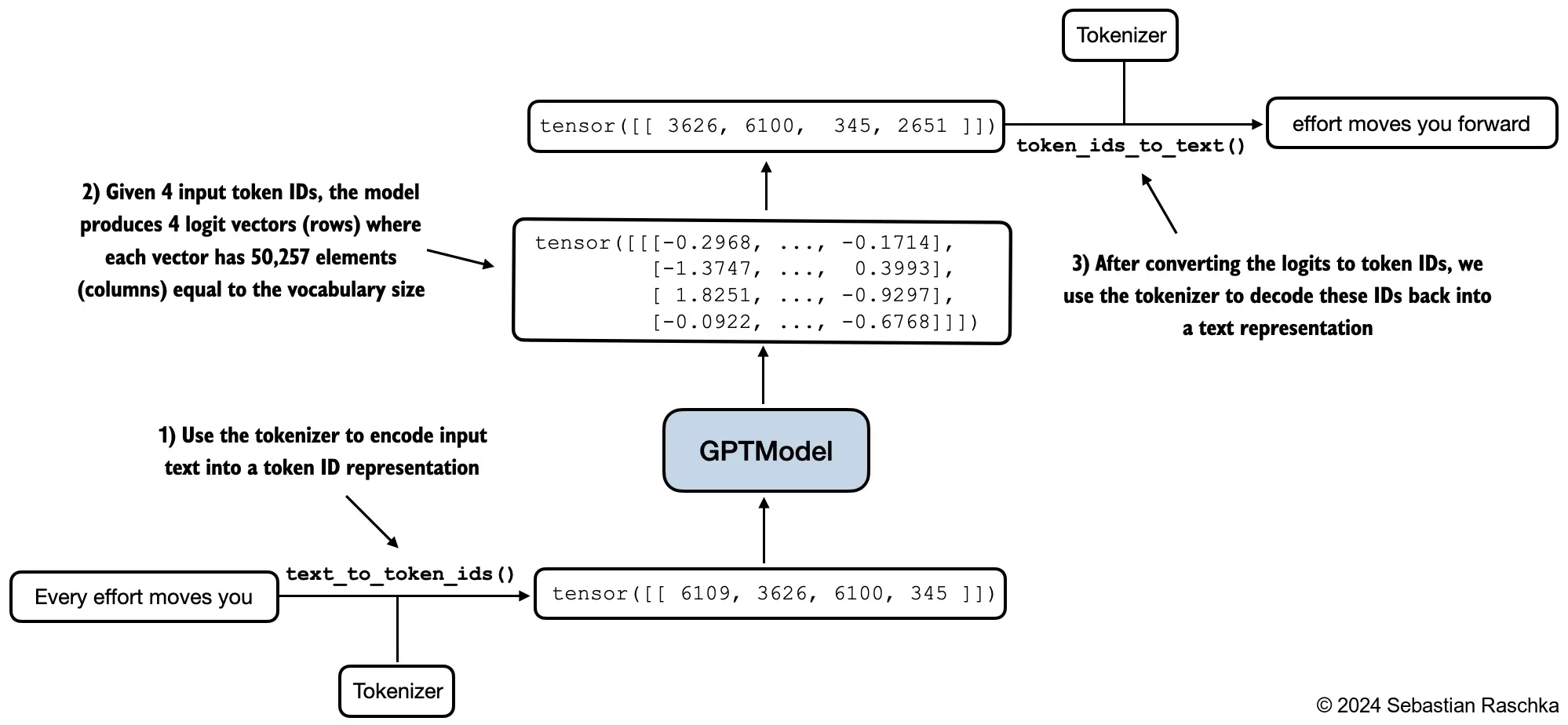
- Next, we use the
generate_text_simplefunction from the previous chapter to generate text - In addition, we define two convenience functions,
text_to_token_idsandtoken_ids_to_text, for converting between token and text representations that we use throughout this chapter
import tiktoken
from previous_chapters import generate_text_simple
# Alternatively:
# from llms_from_scratch.ch04 import generate_text_simple
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # remove batch dimension
return tokenizer.decode(flat.tolist())
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:
Every effort moves you rentingetic wasnم refres RexMeCHicular stren- As we can see above, the model does not produce good text because it has not been trained yet
- How do we measure or capture what “good text” is, in a numeric form, to track it during training?
- The next subsection introduces metrics to calculate a loss metric for the generated outputs that we can use to measure the training progress
- The next chapters on finetuning LLMs will also introduce additional ways to measure model quality
5.1.2 Calculating the text generation loss: cross-entropy and perplexity
- Suppose we have an
inputstensor containing the token IDs for 2 training examples (rows) - Corresponding to the
inputs, thetargetscontain the desired token IDs that we want the model to generate - Notice that the
targetsare theinputsshifted by 1 position, as explained in chapter 2 when we implemented the data loader
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[1107, 588, 11311]]) # " really like chocolate"]- Feeding the
inputsto the model, we obtain the logits vector for the 2 input examples that consist of 3 tokens each - Each of the tokens is a 50,257-dimensional vector corresponding to the size of the vocabulary
- Applying the softmax function, we can turn the logits tensor into a tensor of the same dimension containing probability scores
with torch.no_grad():
logits = model(inputs)
probas = torch.softmax(logits, dim=-1) # Probability of each token in vocabulary
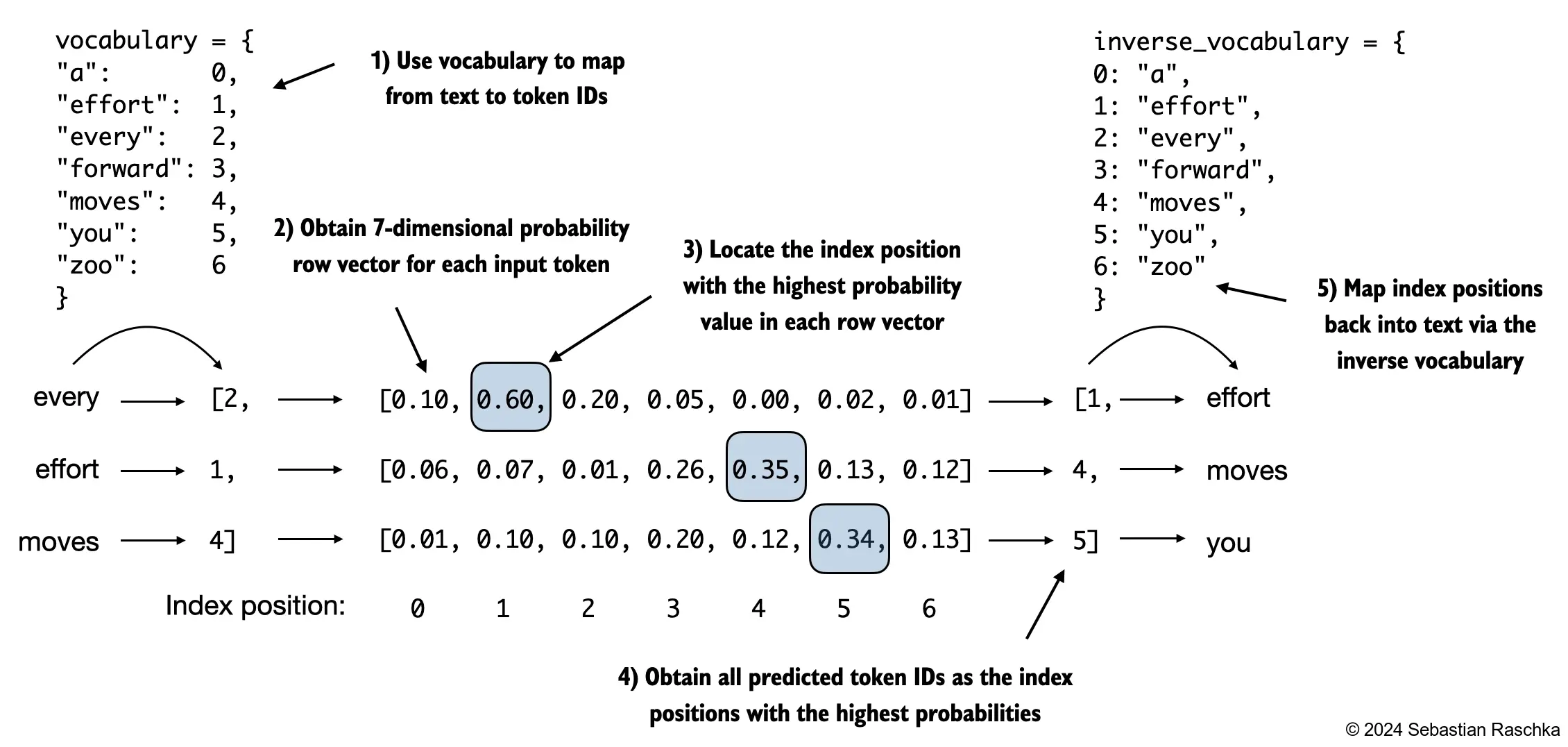
print(probas.shape) # Shape: (batch_size, num_tokens, vocab_size)torch.Size([2, 3, 50257])- The figure below, using a very small vocabulary for illustration purposes, outlines how we convert the probability scores back into text, which we discussed at the end of the previous chapter
As discussed in the previous chapter, we can apply the
argmaxfunction to convert the probability scores into predicted token IDsThe softmax function above produced a 50,257-dimensional vector for each token; the
argmaxfunction returns the position of the highest probability score in this vector, which is the predicted token ID for the given tokenSince we have 2 input batches with 3 tokens each, we obtain 2 by 3 predicted token IDs:
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
print("Token IDs:\n", token_ids)Token IDs:
tensor([[[16657],
[ 339],
[42826]],
[[49906],
[29669],
[41751]]])- If we decode these tokens, we find that these are quite different from the tokens we want the model to predict, namely the target tokens:
print(f"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")Targets batch 1: effort moves you
Outputs batch 1: Armed heNetflix- That’s because the model wasn’t trained yet
- To train the model, we need to know how far it is away from the correct predictions (targets)
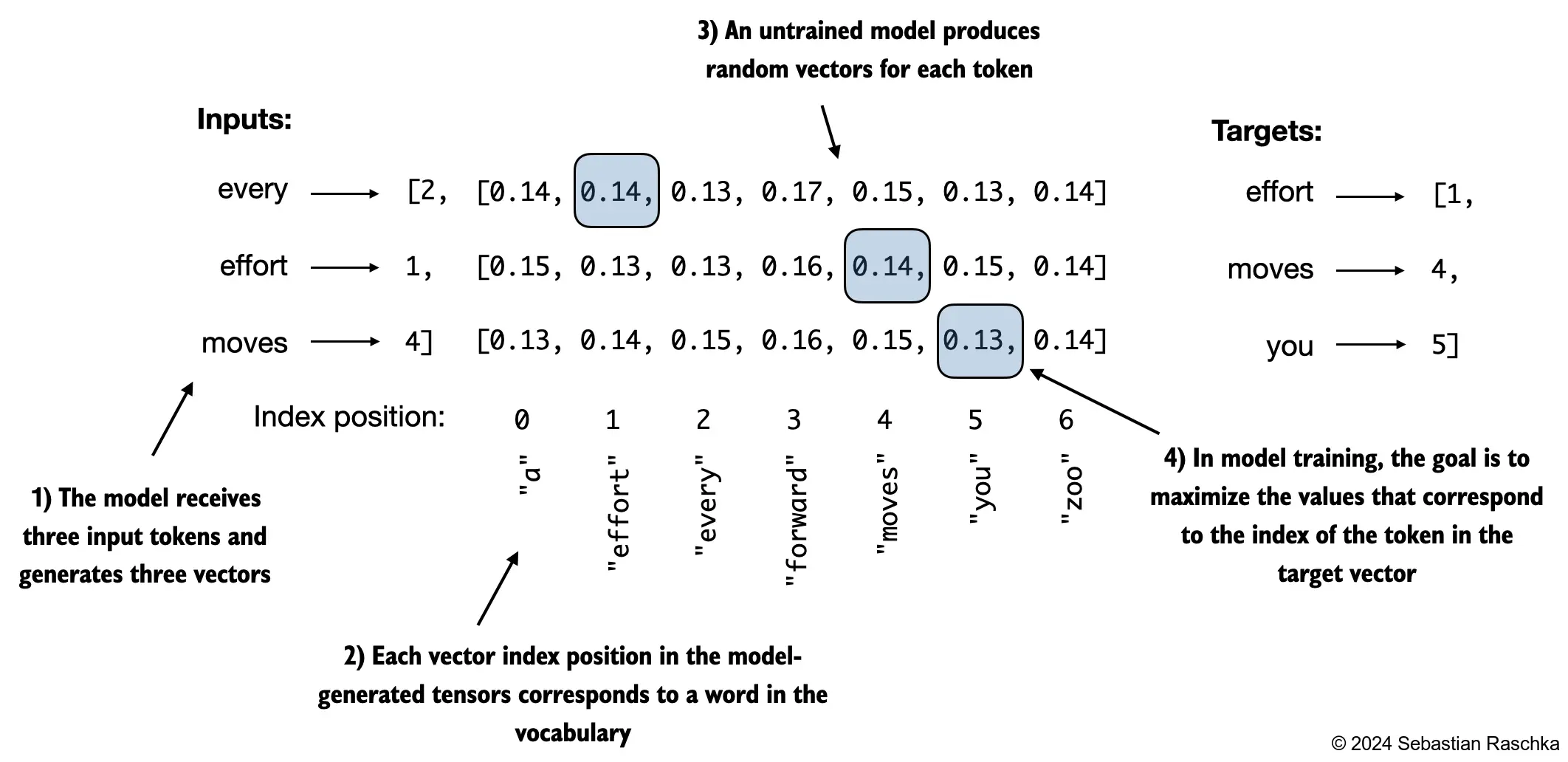
- The token probabilities corresponding to the target indices are as follows:
text_idx = 0
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 2:", target_probas_2)Text 1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])
Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])- We want to maximize all these values, bringing them close to a probability of 1
- In mathematical optimization, it is easier to maximize the logarithm of the probability score than the probability score itself; this is out of the scope of this book, but I have recorded a lecture with more details here: L8.2 Logistic Regression Loss Function
# Compute logarithm of all token probabilities
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
print(log_probas)tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])- Next, we compute the average log probability:
# Calculate the average probability for each token
avg_log_probas = torch.mean(log_probas)
print(avg_log_probas)tensor(-10.7940)The goal is to make this average log probability as large as possible by optimizing the model weights
Due to the log, the largest possible value is 0, and we are currently far away from 0
In deep learning, instead of maximizing the average log-probability, it’s a standard convention to minimize the negative average log-probability value; in our case, instead of maximizing -10.7722 so that it approaches 0, in deep learning, we would minimize 10.7722 so that it approaches 0
The value negative of -10.7722, i.e., 10.7722, is also called cross-entropy loss in deep learning
neg_avg_log_probas = avg_log_probas * -1
print(neg_avg_log_probas)tensor(10.7940)- PyTorch already implements a
cross_entropyfunction that carries out the previous steps

- Before we apply the
cross_entropyfunction, let’s check the shape of the logits and targets
# Logits have shape (batch_size, num_tokens, vocab_size)
print("Logits shape:", logits.shape)
# Targets have shape (batch_size, num_tokens)
print("Targets shape:", targets.shape)Logits shape: torch.Size([2, 3, 50257])
Targets shape: torch.Size([2, 3])- For the
cross_entropyfunction in PyTorch, we want to flatten these tensors by combining them over the batch dimension:
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
print("Flattened logits:", logits_flat.shape)
print("Flattened targets:", targets_flat.shape)Flattened logits: torch.Size([6, 50257])
Flattened targets: torch.Size([6])- Note that the targets are the token IDs, which also represent the index positions in the logits tensors that we want to maximize
- The
cross_entropyfunction in PyTorch will automatically take care of applying the softmax and log-probability computation internally over those token indices in the logits that are to be maximized
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
print(loss)tensor(10.7940)- A concept related to the cross-entropy loss is the perplexity of an LLM
- The perplexity is simply the exponential of the cross-entropy loss
perplexity = torch.exp(loss)
print(perplexity)tensor(48725.8203)- The perplexity is often considered more interpretable because it can be understood as the effective vocabulary size that the model is uncertain about at each step (in the example above, that’d be 48,725 words or tokens)
- In other words, perplexity provides a measure of how well the probability distribution predicted by the model matches the actual distribution of the words in the dataset
- Similar to the loss, a lower perplexity indicates that the model predictions are closer to the actual distribution
5.1.3 Calculating the training and validation set losses
- We use a relatively small dataset for training the LLM (in fact, only one short story)
- The reasons are:
- You can run the code examples in a few minutes on a laptop computer without a suitable GPU
- The training finishes relatively fast (minutes instead of weeks), which is good for educational purposes
- We use a text from the public domain, which can be included in this GitHub repository without violating any usage rights or bloating the repository size
- For example, Llama 2 7B required 184,320 GPU hours on A100 GPUs to be trained on 2 trillion tokens
- At the time of this writing, the hourly cost of an 8xA100 cloud server at AWS is approximately \$30
- So, via an off-the-envelope calculation, training this LLM would cost 184,320 / 8 * \$30 = \$690,000
- Below, we use the same dataset we used in chapter 2
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()- A quick check that the text loaded ok by printing the first and last 99 characters
# First 99 characters
print(text_data[:99])I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no # Last 99 characters
print(text_data[-99:])it for me! The Strouds stand alone, and happen once--but there's no exterminating our kind of art."total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)
print("Tokens:", total_tokens)Characters: 20479
Tokens: 5145With 5,145 tokens, the text is very short for training an LLM, but again, it’s for educational purposes (we will also load pretrained weights later)
Next, we divide the dataset into a training and a validation set and use the data loaders from chapter 2 to prepare the batches for LLM training
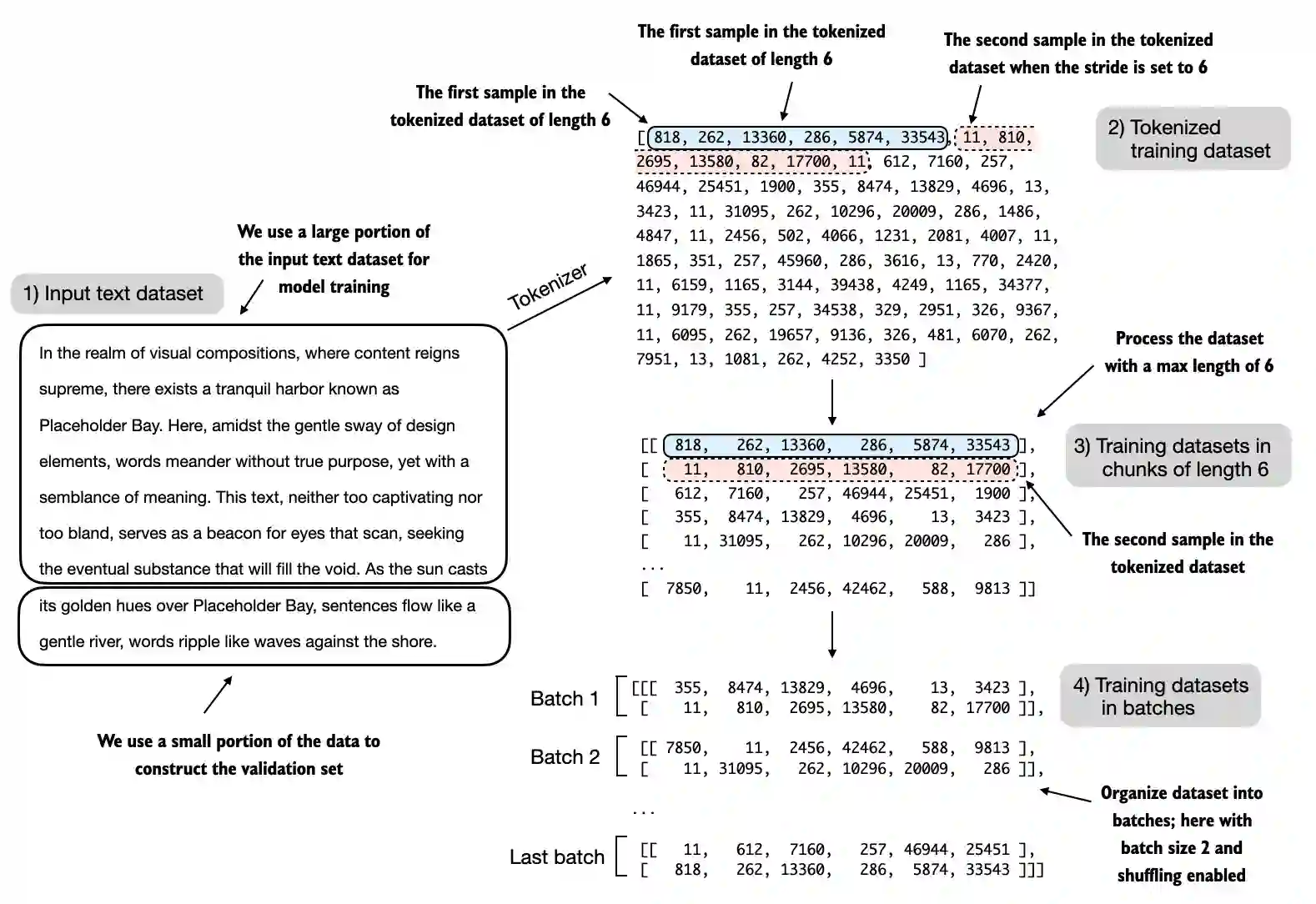
For visualization purposes, the figure below assumes a
max_length=6, but for the training loader, we set themax_lengthequal to the context length that the LLM supportsThe figure below only shows the input tokens for simplicity
- Since we train the LLM to predict the next word in the text, the targets look the same as these inputs, except that the targets are shifted by one position
from previous_chapters import create_dataloader_v1
# Alternatively:
# from llms_from_scratch.ch02 import create_dataloader_v1
# Train/validation ratio
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
torch.manual_seed(123)
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)# Sanity check
if total_tokens * (train_ratio) < GPT_CONFIG_124M["context_length"]:
print("Not enough tokens for the training loader. "
"Try to lower the `GPT_CONFIG_124M['context_length']` or "
"increase the `training_ratio`")
if total_tokens * (1-train_ratio) < GPT_CONFIG_124M["context_length"]:
print("Not enough tokens for the validation loader. "
"Try to lower the `GPT_CONFIG_124M['context_length']` or "
"decrease the `training_ratio`")We use a relatively small batch size to reduce the computational resource demand, and because the dataset is very small to begin with
Llama 2 7B was trained with a batch size of 1024, for example
An optional check that the data was loaded correctly:
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])- Another optional check that the token sizes are in the expected ballpark:
train_tokens = 0
for input_batch, target_batch in train_loader:
train_tokens += input_batch.numel()
val_tokens = 0
for input_batch, target_batch in val_loader:
val_tokens += input_batch.numel()
print("Training tokens:", train_tokens)
print("Validation tokens:", val_tokens)
print("All tokens:", train_tokens + val_tokens)Training tokens: 4608
Validation tokens: 512
All tokens: 5120- Next, we implement a utility function to calculate the cross-entropy loss of a given batch
- In addition, we implement a second utility function to compute the loss for a user-specified number of batches in a data loader
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches- If you have a machine with a CUDA-supported GPU, the LLM will train on the GPU without making any changes to the code
- Via the
devicesetting, we ensure that the data is loaded onto the same device as the LLM model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Note:
# Uncommenting the following lines will allow the code to run on Apple Silicon chips, if applicable,
# which is approximately 2x faster than on an Apple CPU (as measured on an M3 MacBook Air).
# However, the resulting loss values may be slightly different.
#if torch.cuda.is_available():
# device = torch.device("cuda")
#elif torch.backends.mps.is_available():
# device = torch.device("mps")
#else:
# device = torch.device("cpu")
#
# print(f"Using {device} device.")
model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes
torch.manual_seed(123) # For reproducibility due to the shuffling in the data loader
with torch.no_grad(): # Disable gradient tracking for efficiency because we are not training, yet
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)Training loss: 10.98758347829183
Validation loss: 10.98110580444336
5.2 Training an LLM
- In this section, we finally implement the code for training the LLM
- We focus on a simple training function (if you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to Appendix D)
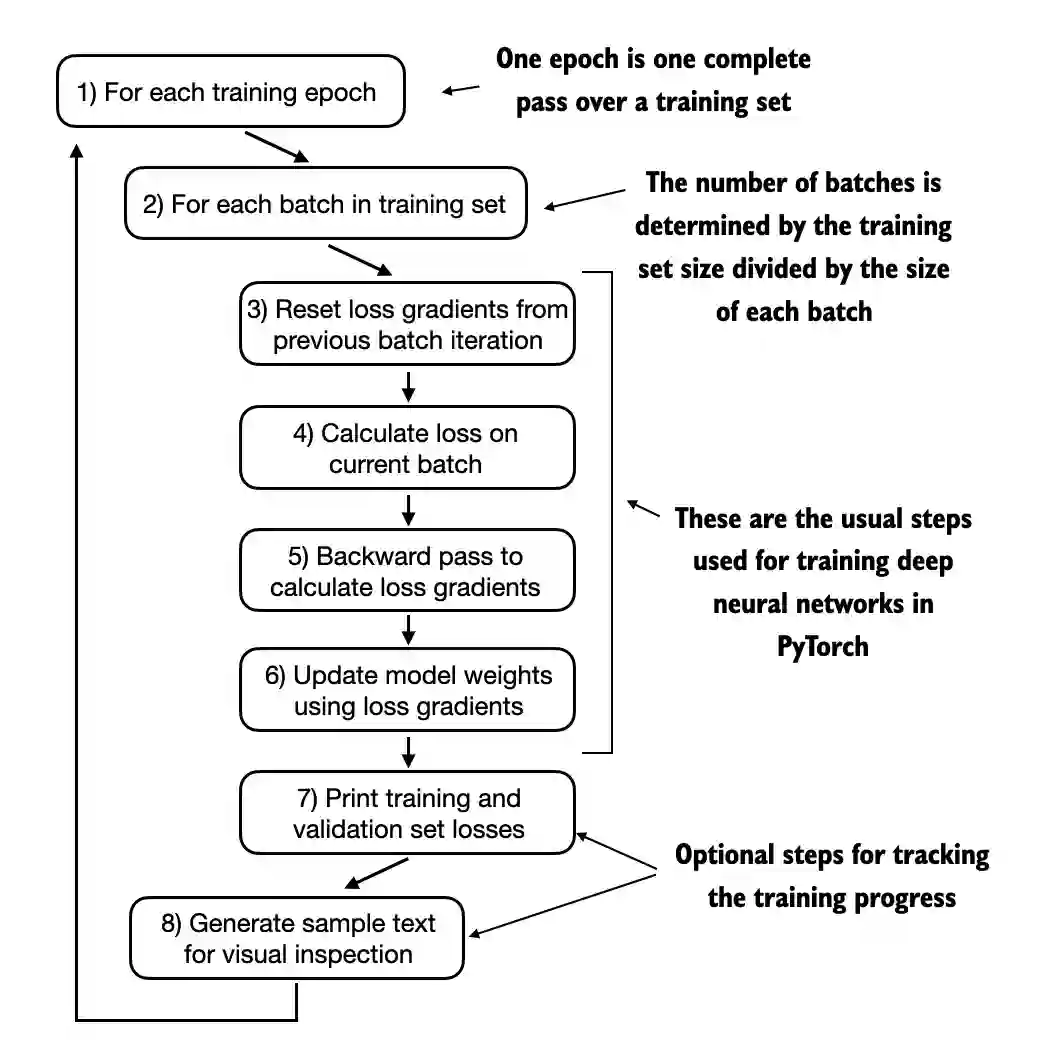
def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
# Initialize lists to track losses and tokens seen
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
model.train() # Set model to training mode
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
tokens_seen += input_batch.numel()
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Print a sample text after each epoch
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " ")) # Compact print format
model.train()- Now, let’s train the LLM using the training function defined above:
# Note:
# Uncomment the following code to calculate the execution time
# import time
# start_time = time.time()
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
# Note:
# Uncomment the following code to show the execution time
# end_time = time.time()
# execution_time_minutes = (end_time - start_time) / 60
# print(f"Training completed in {execution_time_minutes:.2f} minutes.")Ep 1 (Step 000000): Train loss 9.781, Val loss 9.933
Ep 1 (Step 000005): Train loss 8.111, Val loss 8.339
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.661, Val loss 7.048
Ep 2 (Step 000015): Train loss 5.961, Val loss 6.616
Every effort moves you, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and,, and, and,
Ep 3 (Step 000020): Train loss 5.726, Val loss 6.600
Ep 3 (Step 000025): Train loss 5.201, Val loss 6.348
Every effort moves you, and I had been.
Ep 4 (Step 000030): Train loss 4.417, Val loss 6.278
Ep 4 (Step 000035): Train loss 4.069, Val loss 6.226
Every effort moves you know the "I he had the donkey and I had the and I had the donkey and down the room, I had
Ep 5 (Step 000040): Train loss 3.732, Val loss 6.160
Every effort moves you know it was not that the picture--I had the fact by the last I had been--his, and in the "Oh, and he said, and down the room, and in
Ep 6 (Step 000045): Train loss 2.850, Val loss 6.179
Ep 6 (Step 000050): Train loss 2.427, Val loss 6.141
Every effort moves you know," was one of the picture. The--I had a little of a little: "Yes, and in fact, and in the picture was, and I had been at my elbow and as his pictures, and down the room, I had
Ep 7 (Step 000055): Train loss 2.104, Val loss 6.134
Ep 7 (Step 000060): Train loss 1.882, Val loss 6.233
Every effort moves you know," was one of the picture for nothing--I told Mrs. "I was no--as! The women had been, in the moment--as Jack himself, as once one had been the donkey, and were, and in his
Ep 8 (Step 000065): Train loss 1.320, Val loss 6.238
Ep 8 (Step 000070): Train loss 0.985, Val loss 6.242
Every effort moves you know," was one of the axioms he had been the tips of a self-confident moustache, I felt to see a smile behind his close grayish beard--as if he had the donkey. "strongest," as his
Ep 9 (Step 000075): Train loss 0.717, Val loss 6.293
Ep 9 (Step 000080): Train loss 0.541, Val loss 6.393
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" He laughed again, and threw back the window-curtains, I had the donkey. "There were days when I
Ep 10 (Step 000085): Train loss 0.391, Val loss 6.452
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed luncheon-table, when, on a later day, I had again run over from Monte Carlo; and Mrs. Gis- Note that you might get slightly different loss values on your computer, which is not a reason for concern if they are roughly similar (a training loss below 1 and a validation loss below 7)
- Small differences can often be due to different GPU hardware and CUDA versions or small changes in newer PyTorch versions
- Even if you are running the example on a CPU, you may observe slight differences; a possible reason for a discrepancy is the differing behavior of
nn.Dropoutacross operating systems, depending on how PyTorch was compiled, as discussed here on the PyTorch issue tracker
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
# Plot training and validation loss against epochs
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True)) # only show integer labels on x-axis
# Create a second x-axis for tokens seen
ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks
ax2.set_xlabel("Tokens seen")
fig.tight_layout() # Adjust layout to make room
plt.savefig("loss-plot.pdf")
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
- Looking at the results above, we can see that the model starts out generating incomprehensible strings of words, whereas towards the end, it’s able to produce grammatically more or less correct sentences
- However, based on the training and validation set losses, we can see that the model starts overfitting
- If we were to check a few passages it writes towards the end, we would find that they are contained in the training set verbatim – it simply memorizes the training data
- Later, we will cover decoding strategies that can mitigate this memorization by a certain degree
- Note that the overfitting here occurs because we have a very, very small training set, and we iterate over it so many times
- The LLM training here primarily serves educational purposes; we mainly want to see that the model can learn to produce coherent text
- Instead of spending weeks or months on training this model on vast amounts of expensive hardware, we load pretrained weights later
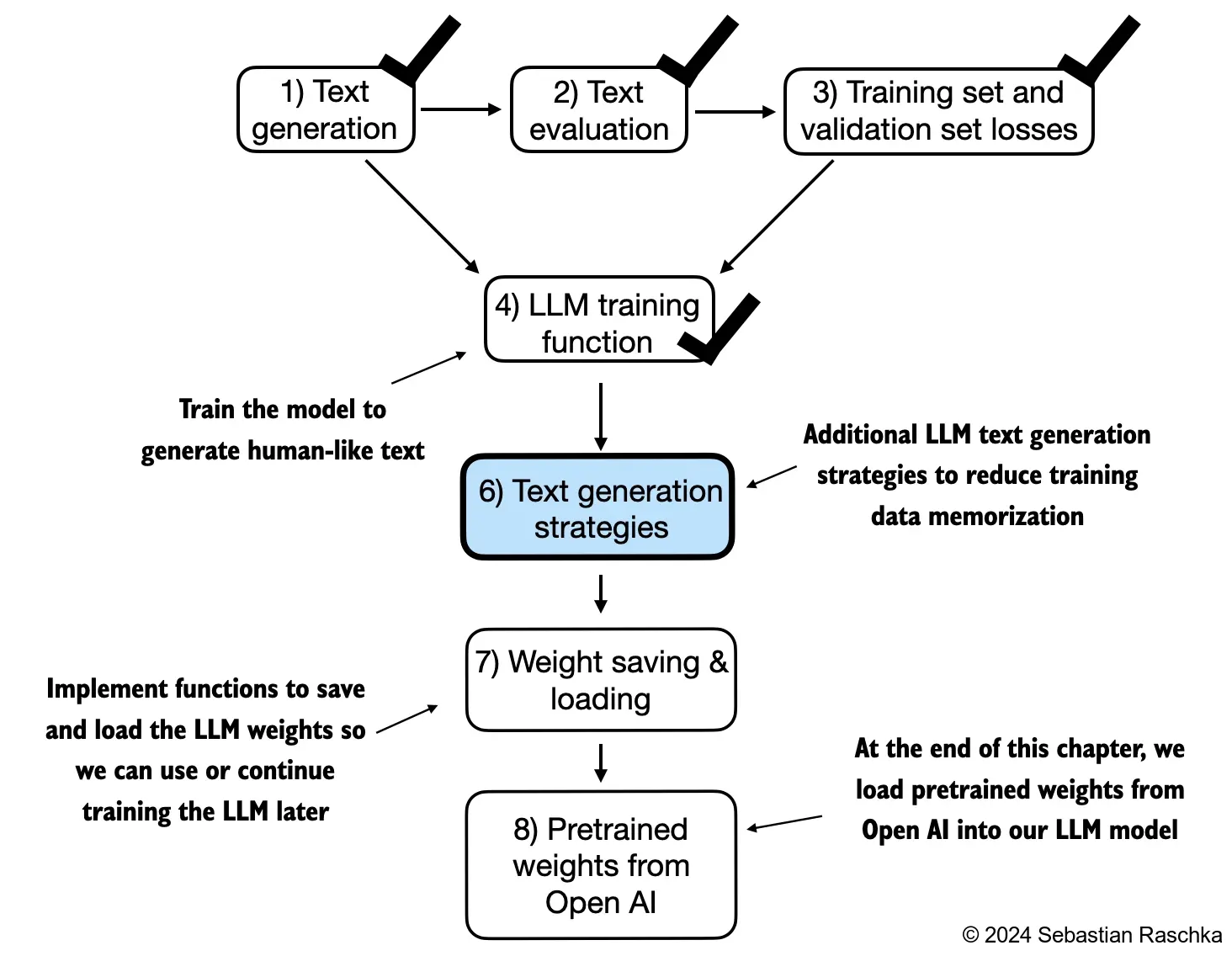
If you are interested in augmenting this training function with more advanced techniques, such as learning rate warmup, cosine annealing, and gradient clipping, please refer to Appendix D
If you are interested in a larger training dataset and longer training run, see ../03_bonus_pretraining_on_gutenberg
5.3 Decoding strategies to control randomness
- Inference is relatively cheap with a relatively small LLM as the GPT model we trained above, so there’s no need to use a GPU for it in case you used a GPU for training it above
- Using the
generate_text_simplefunction (from the previous chapter) that we used earlier inside the simple training function, we can generate new text one word (or token) at a time - As explained in section 5.1.2, the next generated token is the token corresponding to the largest probability score among all tokens in the vocabulary
model.to("cpu")
model.eval()
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=25,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed lun- Even if we execute the
generate_text_simplefunction above multiple times, the LLM will always generate the same outputs - We now introduce two concepts, so-called decoding strategies, to modify the
generate_text_simple: temperature scaling and top-k sampling - These will allow the model to control the randomness and diversity of the generated text
5.3.1 Temperature scaling
Previously, we always sampled the token with the highest probability as the next token using
torch.argmaxTo add variety, we can sample the next token using The
torch.multinomial(probs, num_samples=1), sampling from a probability distributionHere, each index’s chance of being picked corresponds to its probability in the input tensor
Here’s a little recap of generating the next token, assuming a very small vocabulary for illustration purposes:
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
# Suppose input is "every effort moves you", and the LLM
# returns the following logits for the next token:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
# The next generated token is then as follows:
print(inverse_vocab[next_token_id])forwardtorch.manual_seed(123)
next_token_id = torch.multinomial(probas, num_samples=1).item()
print(inverse_vocab[next_token_id])forward- Instead of determining the most likely token via
torch.argmax, we usetorch.multinomial(probas, num_samples=1)to determine the most likely token by sampling from the softmax distribution - For illustration purposes, let’s see what happens when we sample the next token 1,000 times using the original softmax probabilities:
def print_sampled_tokens(probas):
torch.manual_seed(123) # Manual seed for reproducibility
sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]
sampled_ids = torch.bincount(torch.tensor(sample), minlength=len(probas))
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {inverse_vocab[i]}")
print_sampled_tokens(probas)73 x closer
0 x every
0 x effort
582 x forward
2 x inches
0 x moves
0 x pizza
343 x toward
0 x youWe can control the distribution and selection process via a concept called temperature scaling
“Temperature scaling” is just a fancy word for dividing the logits by a number greater than 0
Temperatures greater than 1 will result in more uniformly distributed token probabilities after applying the softmax
Temperatures smaller than 1 will result in more confident (sharper or more peaky) distributions after applying the softmax
Note that the resulting dropout outputs may look different depending on your operating system; you can read more about this inconsistency here on the PyTorch issue tracker
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
# Temperature values
temperatures = [1, 0.1, 5] # Original, higher confidence, and lower confidence
# Calculate scaled probabilities
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]# Plotting
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots(figsize=(5, 3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i], bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.savefig("temperature-plot.pdf")
plt.show()
- We can see that the rescaling via temperature 0.1 results in a sharper distribution, approaching
torch.argmax, such that the most likely word is almost always selected:
print_sampled_tokens(scaled_probas[1])0 x closer
0 x every
0 x effort
985 x forward
0 x inches
0 x moves
0 x pizza
15 x toward
0 x you- The rescaled probabilities via temperature 5 are more uniformly distributed:
print_sampled_tokens(scaled_probas[2])165 x closer
75 x every
42 x effort
239 x forward
71 x inches
46 x moves
32 x pizza
227 x toward
103 x you- Assuming an LLM input “every effort moves you”, using the approach above can sometimes result in nonsensical texts, such as “every effort moves you pizza”, 3.2% of the time (32 out of 1000 times)
5.3.2 Top-k sampling
- To be able to use higher temperatures to increase output diversity and to reduce the probability of nonsensical sentences, we can restrict the sampled tokens to the top-k most likely tokens:

(Please note that the numbers in this figure are truncated to two digits after the decimal point to reduce visual clutter. The values in the Softmax row should add up to 1.0.)
In code, we can implement this as follows:
top_k = 3
top_logits, top_pos = torch.topk(next_token_logits, top_k)
print("Top logits:", top_logits)
print("Top positions:", top_pos)Top logits: tensor([6.7500, 6.2800, 4.5100])
Top positions: tensor([3, 7, 0])new_logits = torch.where(
condition=next_token_logits < top_logits[-1],
input=torch.tensor(float("-inf")),
other=next_token_logits
)
print(new_logits)tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])NOTE:
An alternative, slightly more efficient implementation of the previous code cell is the following:
new_logits = torch.full_like( # create tensor containing -inf values next_token_logits, -torch.inf ) new_logits[top_pos] = next_token_logits[top_pos] # copy top k values into the -inf tensor
For more details, see https://github.com/rasbt/LLMs-from-scratch/discussions/326
topk_probas = torch.softmax(new_logits, dim=0)
print(topk_probas)tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])5.3.3 Modifying the text generation function
- The previous two subsections introduced temperature sampling and top-k sampling
- Let’s use these two concepts to modify the
generate_simplefunction we used to generate text via the LLM earlier, creating a newgeneratefunction:
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
# For-loop is the same as before: Get logits, and only focus on last time step
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# New: Filter logits with top_k sampling
if top_k is not None:
# Keep only top_k values
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# New: Apply temperature scaling
if temperature > 0.0:
logits = logits / temperature
# Apply softmax to get probabilities
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# Sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Otherwise same as before: get idx of the vocab entry with the highest logits value
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified
break
# Same as before: append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idxtorch.manual_seed(123)
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:
Every effort moves you stand to work on surprise, a one of us had gone with random-5.4 Loading and saving model weights in PyTorch
- Training LLMs is computationally expensive, so it’s crucial to be able to save and load LLM weights
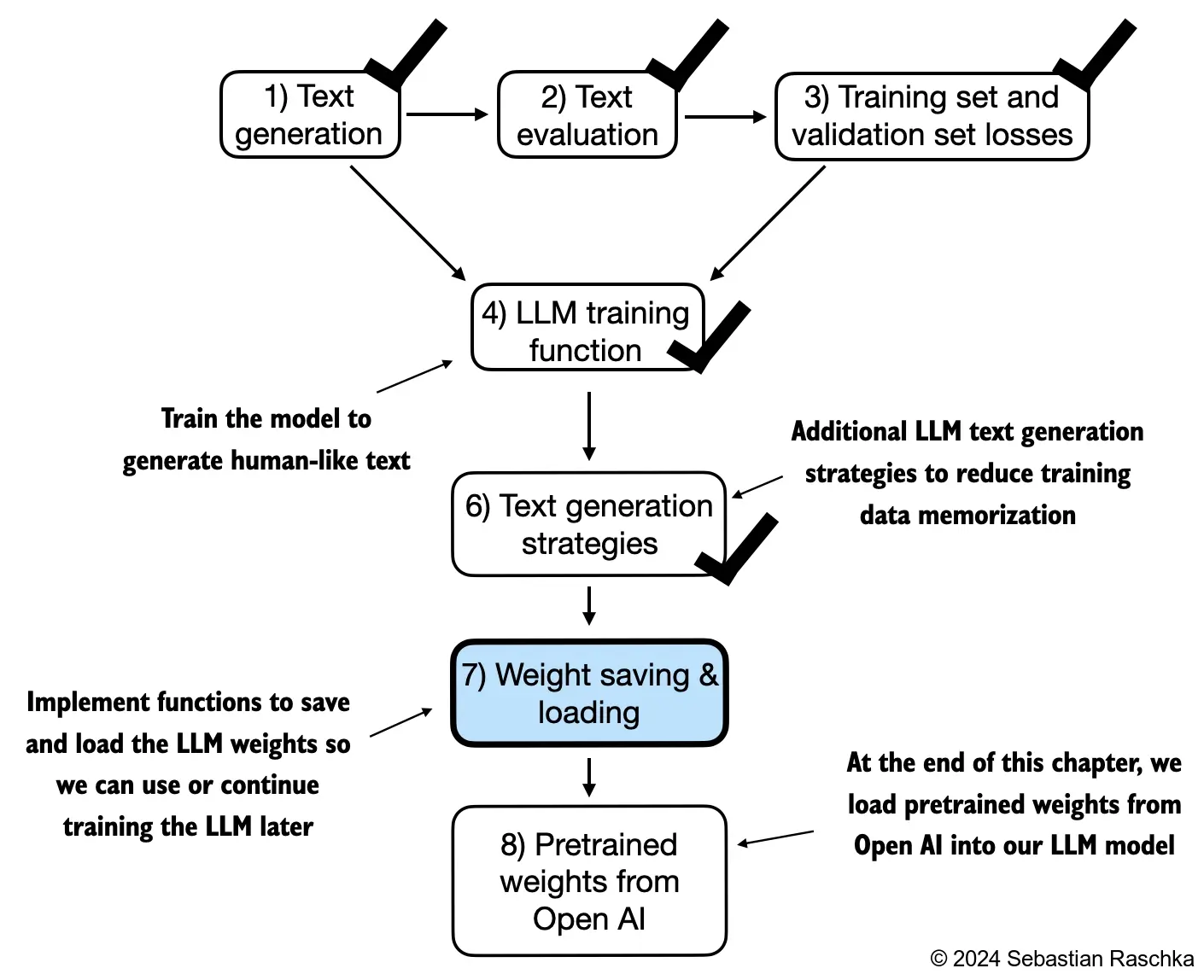
- The recommended way in PyTorch is to save the model weights, the so-called
state_dictvia by applying thetorch.savefunction to the.state_dict()method:
torch.save(model.state_dict(), "model.pth")- Then we can load the model weights into a new
GPTModelmodel instance as follows:
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load("model.pth", map_location=device, weights_only=True))
model.eval();- It’s common to train LLMs with adaptive optimizers like Adam or AdamW instead of regular SGD
- These adaptive optimizers store additional parameters for each model weight, so it makes sense to save them as well in case we plan to continue the pretraining later:
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth"
)checkpoint = torch.load("model_and_optimizer.pth", weights_only=True)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
model.train();5.5 Loading pretrained weights from OpenAI
- Previously, we only trained a small GPT-2 model using a very small short-story book for educational purposes
- Interested readers can also find a longer pretraining run on the complete Project Gutenberg book corpus in ../03_bonus_pretraining_on_gutenberg
- Fortunately, we don’t have to spend tens to hundreds of thousands of dollars to pretrain the model on a large pretraining corpus but can load the pretrained weights provided by OpenAI
⚠️ Note: Some users may encounter issues in this section due to TensorFlow compatibility problems, particularly on certain Windows systems. TensorFlow is required here only to load the original OpenAI GPT-2 weight files, which we then convert to PyTorch. If you’re running into TensorFlow-related issues, you can use the alternative code below instead of the remaining code in this section. This alternative is based on pre-converted PyTorch weights, created using the same conversion process described in the previous section. For details, refer to the notebook: ../02_alternative_weight_loading/weight-loading-pytorch.ipynb notebook.
file_name = "gpt2-small-124M.pth"
# file_name = "gpt2-medium-355M.pth"
# file_name = "gpt2-large-774M.pth"
# file_name = "gpt2-xl-1558M.pth"
url = f"https://huggingface.co/rasbt/gpt2-from-scratch-pytorch/resolve/main/{file_name}"
if not os.path.exists(file_name):
urllib.request.urlretrieve(url, file_name)
print(f"Downloaded to {file_name}")
gpt = GPTModel(BASE_CONFIG)
gpt.load_state_dict(torch.load(file_name, weights_only=True))
gpt.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gpt.to(device);
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))- First, some boilerplate code to download the files from OpenAI and load the weights into Python
- Since OpenAI used TensorFlow, we will have to install and use TensorFlow for loading the weights; tqdm is a progress bar library
- Uncomment and run the next cell to install the required libraries
# pip install tensorflow tqdmprint("TensorFlow version:", version("tensorflow"))
print("tqdm version:", version("tqdm"))TensorFlow version: 2.18.0
tqdm version: 4.67.1# Relative import from the gpt_download.py contained in this folder
from gpt_download import download_and_load_gpt2
# Alternatively:
# from llms_from_scratch.ch05 import download_and_load_gpt2Note
- In very rare cases, the code cell above may result in a
zsh: illegal hardware instruction pythonerror, which could be due to a TensorFlow installation issue on your machine - A reader found that installing TensorFlow via
condasolved the issue in this specific case, as mentioned here - You can find more instructions in this supplementary Python setup tutorial
- We can then download the model weights for the 124 million parameter model as follows:
settings, params = download_and_load_gpt2(model_size="124M", models_dir="gpt2")checkpoint: 100%|████████████████████████████████████████████████████████████████████████████████| 77.0/77.0 [00:00<00:00, 63.1kiB/s]
encoder.json: 100%|████████████████████████████████████████████████████████████████████████████| 1.04M/1.04M [00:00<00:00, 4.69MiB/s]
hparams.json: 100%|██████████████████████████████████████████████████████████████████████████████| 90.0/90.0 [00:00<00:00, 59.7kiB/s]
model.ckpt.data-00000-of-00001: 100%|████████████████████████████████████████████████████████████| 498M/498M [01:09<00:00, 7.15MiB/s]
model.ckpt.index: 100%|████████████████████████████████████████████████████████████████████████| 5.21k/5.21k [00:00<00:00, 2.32MiB/s]
model.ckpt.meta: 100%|███████████████████████████████████████████████████████████████████████████| 471k/471k [00:00<00:00, 2.19MiB/s]
vocab.bpe: 100%|█████████████████████████████████████████████████████████████████████████████████| 456k/456k [00:00<00:00, 3.47MiB/s]print("Settings:", settings)Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}print("Parameter dictionary keys:", params.keys())Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])print(params["wte"])
print("Token embedding weight tensor dimensions:", params["wte"].shape)[[-0.11010301 -0.03926672 0.03310751 ... -0.1363697 0.01506208
0.04531523]
[ 0.04034033 -0.04861503 0.04624869 ... 0.08605453 0.00253983
0.04318958]
[-0.12746179 0.04793796 0.18410145 ... 0.08991534 -0.12972379
-0.08785918]
...
[-0.04453601 -0.05483596 0.01225674 ... 0.10435229 0.09783269
-0.06952604]
[ 0.1860082 0.01665728 0.04611587 ... -0.09625227 0.07847701
-0.02245961]
[ 0.05135201 -0.02768905 0.0499369 ... 0.00704835 0.15519823
0.12067825]]
Token embedding weight tensor dimensions: (50257, 768)- Alternatively, “355M”, “774M”, and “1558M” are also supported
model_sizearguments - The difference between these differently sized models is summarized in the figure below:
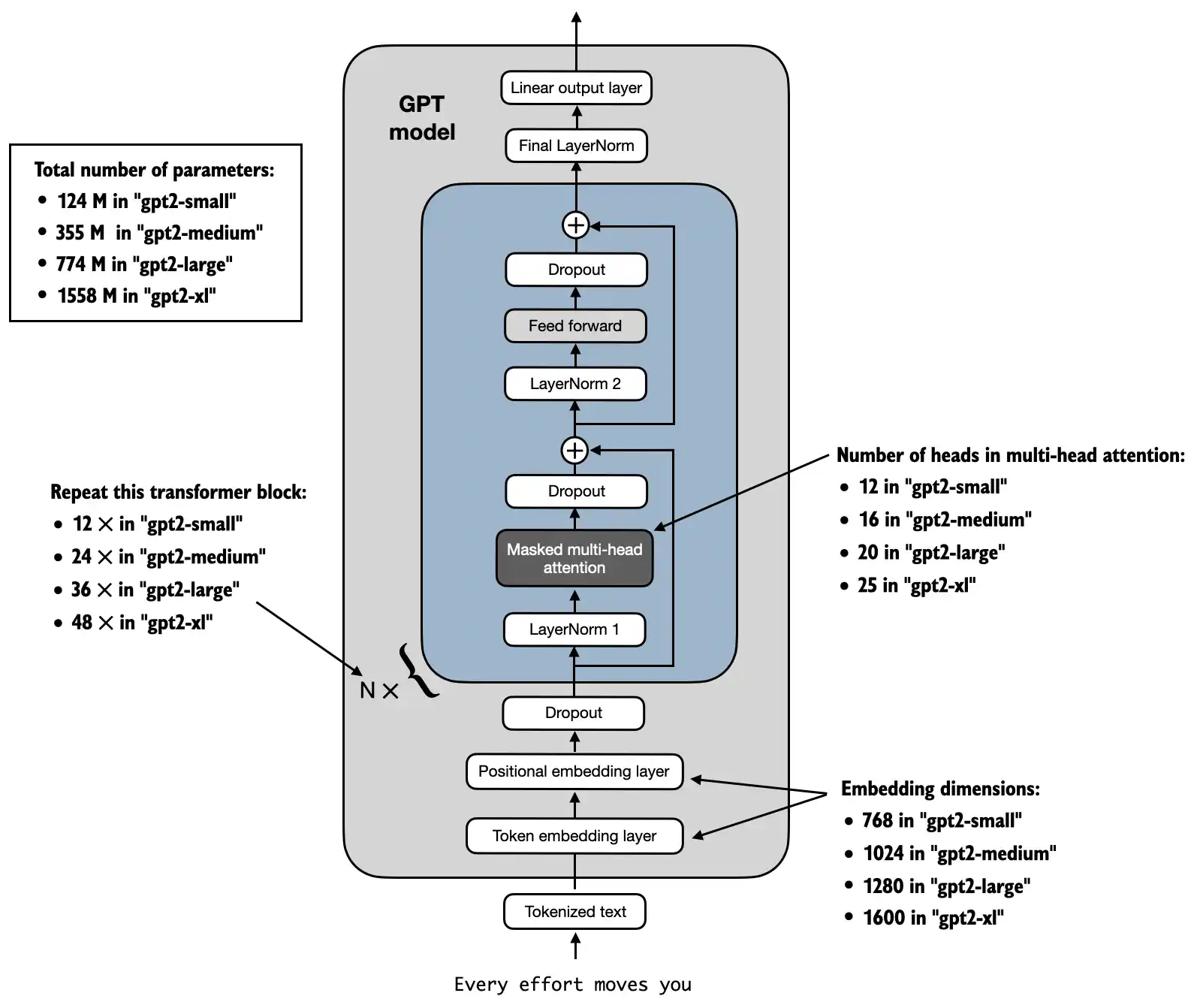
- Above, we loaded the 124M GPT-2 model weights into Python, however we still need to transfer them into our
GPTModelinstance - First, we initialize a new GPTModel instance
- Note that the original GPT model initialized the linear layers for the query, key, and value matrices in the multi-head attention module with bias vectors, which is not required or recommended; however, to be able to load the weights correctly, we have to enable these too by setting
qkv_biastoTruein our implementation, too - We are also using the
1024token context length that was used by the original GPT-2 model(s)
# Define model configurations in a dictionary for compactness
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
# Copy the base configuration and update with specific model settings
model_name = "gpt2-small (124M)" # Example model name
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024, "qkv_bias": True})
gpt = GPTModel(NEW_CONFIG)
gpt.eval();- The next task is to assign the OpenAI weights to the corresponding weight tensors in our
GPTModelinstance
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(torch.tensor(right))import numpy as np
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
load_weights_into_gpt(gpt, params)
gpt.to(device);- If the model is loaded correctly, we can use it to generate new text using our previous
generatefunction:
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))Output text:
Every effort moves you toward finding an ideal new way to practice something!
What makes us want to be on top of that?We know that we loaded the model weights correctly because the model can generate coherent text; if we made even a small mistake, the model would not be able to do that
For an alternative way to load the weights from the Hugging Face Hub, see ../02_alternative_weight_loading
If you are interested in seeing how the GPT architecture compares to the Llama architecture (a popular LLM developed by Meta AI), see the bonus content at ../07_gpt_to_llama
Summary and takeaways
- See the ./gpt_train.py script, a self-contained script for training
- The ./gpt_generate.py script loads pretrained weights from OpenAI and generates text based on a prompt
- You can find the exercise solutions in ./exercise-solutions.ipynb
6. Finetuning for Text Classification
matplotlib version: 3.10.0
numpy version: 2.0.2
tiktoken version: 0.9.0
torch version: 2.6.0
tensorflow version: 2.18.0
pandas version: 2.2.3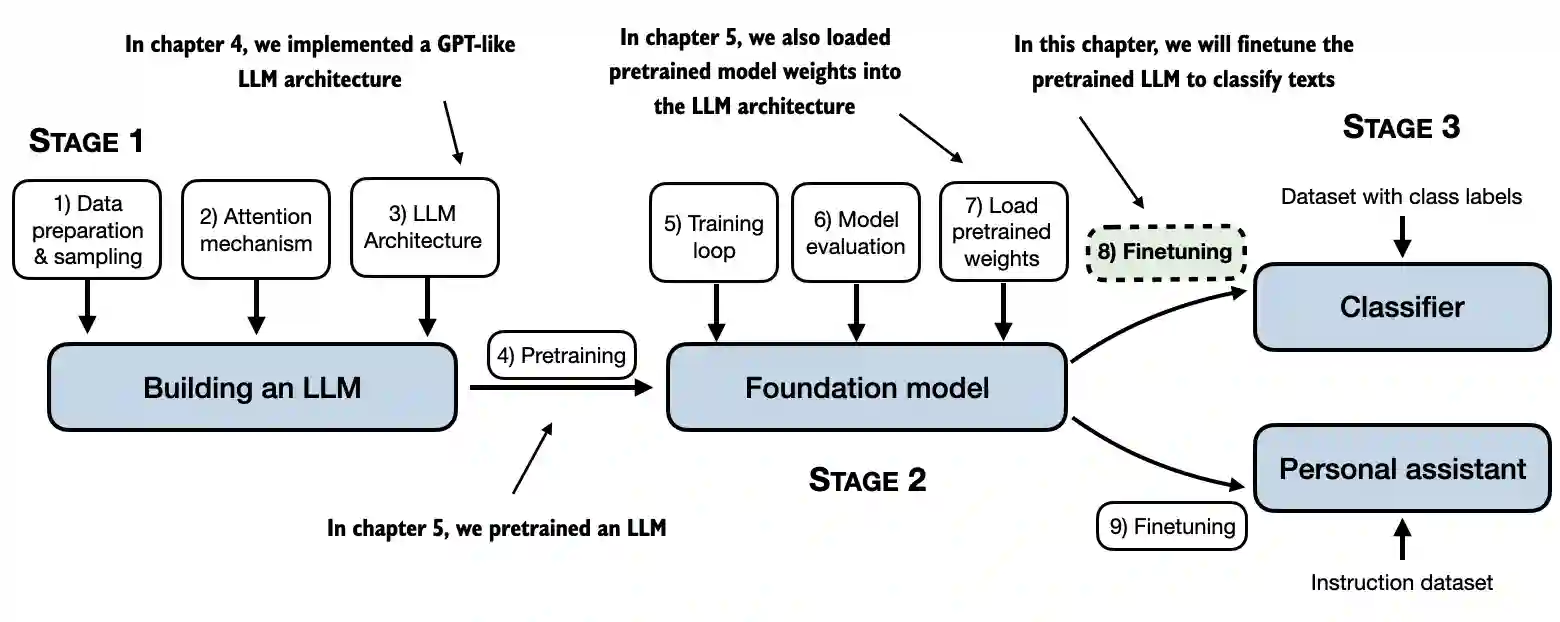
6.1 Different categories of finetuning
No code in this section
The most common ways to finetune language models are instruction-finetuning and classification finetuning
Instruction-finetuning, depicted below, is the topic of the next chapter

- Classification finetuning, the topic of this chapter, is a procedure you may already be familiar with if you have a background in machine learning – it’s similar to training a convolutional network to classify handwritten digits, for example
- In classification finetuning, we have a specific number of class labels (for example, “spam” and “not spam”) that the model can output
- A classification finetuned model can only predict classes it has seen during training (for example, “spam” or “not spam”), whereas an instruction-finetuned model can usually perform many tasks
- We can think of a classification-finetuned model as a very specialized model; in practice, it is much easier to create a specialized model than a generalist model that performs well on many different tasks
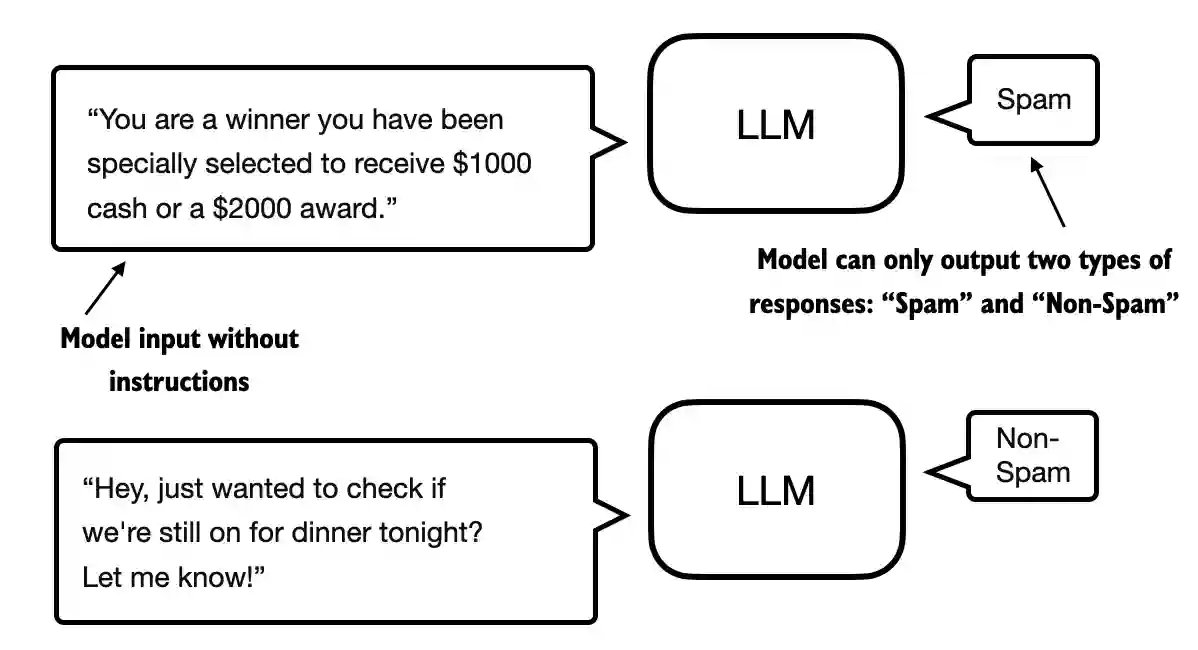
6.2 Preparing the dataset
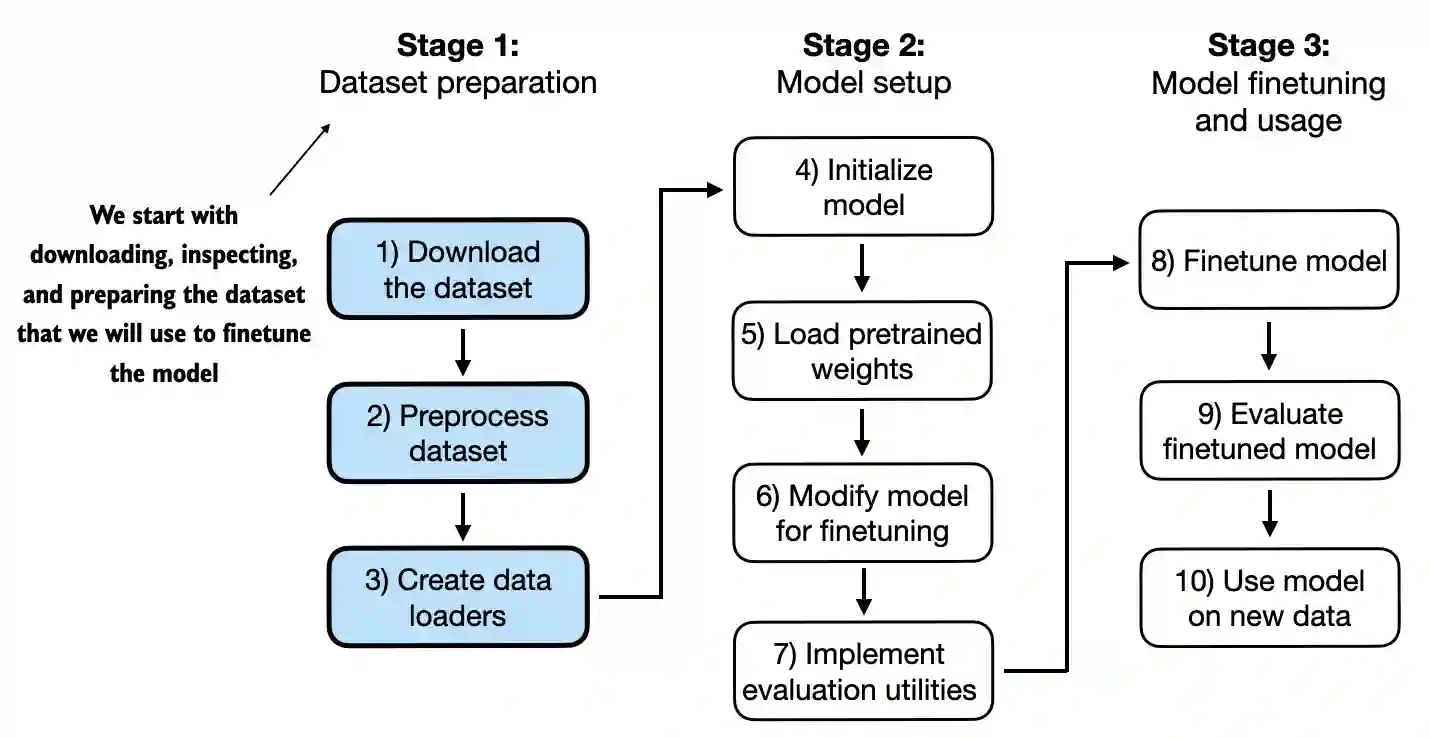
- This section prepares the dataset we use for classification finetuning
- We use a dataset consisting of spam and non-spam text messages to finetune the LLM to classify them
- First, we download and unzip the dataset
File downloaded and saved as sms_spam_collection/SMSSpamCollection.tsv- The dataset is saved as a tab-separated text file, which we can load into a pandas DataFrame
| Label | Text | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
| ... | ... | ... |
| 5567 | spam | This is the 2nd time we have tried 2 contact u... |
| 5568 | ham | Will ü b going to esplanade fr home? |
| 5569 | ham | Pity, * was in mood for that. So...any other s... |
| 5570 | ham | The guy did some bitching but I acted like i'd... |
| 5571 | ham | Rofl. Its true to its name |
5572 rows × 2 columns
- When we check the class distribution, we see that the data contains “ham” (i.e., “not spam”) much more frequently than “spam”
Label
ham 4825
spam 747
Name: count, dtype: int64- For simplicity, and because we prefer a small dataset for educational purposes anyway (it will make it possible to finetune the LLM faster), we subsample (undersample) the dataset so that it contains 747 instances from each class
- (Next to undersampling, there are several other ways to deal with class balances, but they are out of the scope of a book on LLMs; you can find examples and more information in the
imbalanced-learnuser guide)
Label
ham 747
spam 747
Name: count, dtype: int64- Next, we change the string class labels “ham” and “spam” into integer class labels 0 and 1:
| Label | Text | |
|---|---|---|
| 4307 | 0 | Awww dat is sweet! We can think of something t... |
| 4138 | 0 | Just got to <#> |
| 4831 | 0 | The word "Checkmate" in chess comes from the P... |
| 4461 | 0 | This is wishing you a great day. Moji told me ... |
| 5440 | 0 | Thank you. do you generally date the brothas? |
| ... | ... | ... |
| 5537 | 1 | Want explicit SEX in 30 secs? Ring 02073162414... |
| 5540 | 1 | ASKED 3MOBILE IF 0870 CHATLINES INCLU IN FREE ... |
| 5547 | 1 | Had your contract mobile 11 Mnths? Latest Moto... |
| 5566 | 1 | REMINDER FROM O2: To get 2.50 pounds free call... |
| 5567 | 1 | This is the 2nd time we have tried 2 contact u... |
1494 rows × 2 columns
- Let’s now define a function that randomly divides the dataset into training, validation, and test subsets
6.3 Creating data loaders
- Note that the text messages have different lengths; if we want to combine multiple training examples in a batch, we have to either
- truncate all messages to the length of the shortest message in the dataset or batch
- pad all messages to the length of the longest message in the dataset or batch
- We choose option 2 and pad all messages to the longest message in the dataset
- For that, we use
<|endoftext|>as a padding token, as discussed in chapter 2
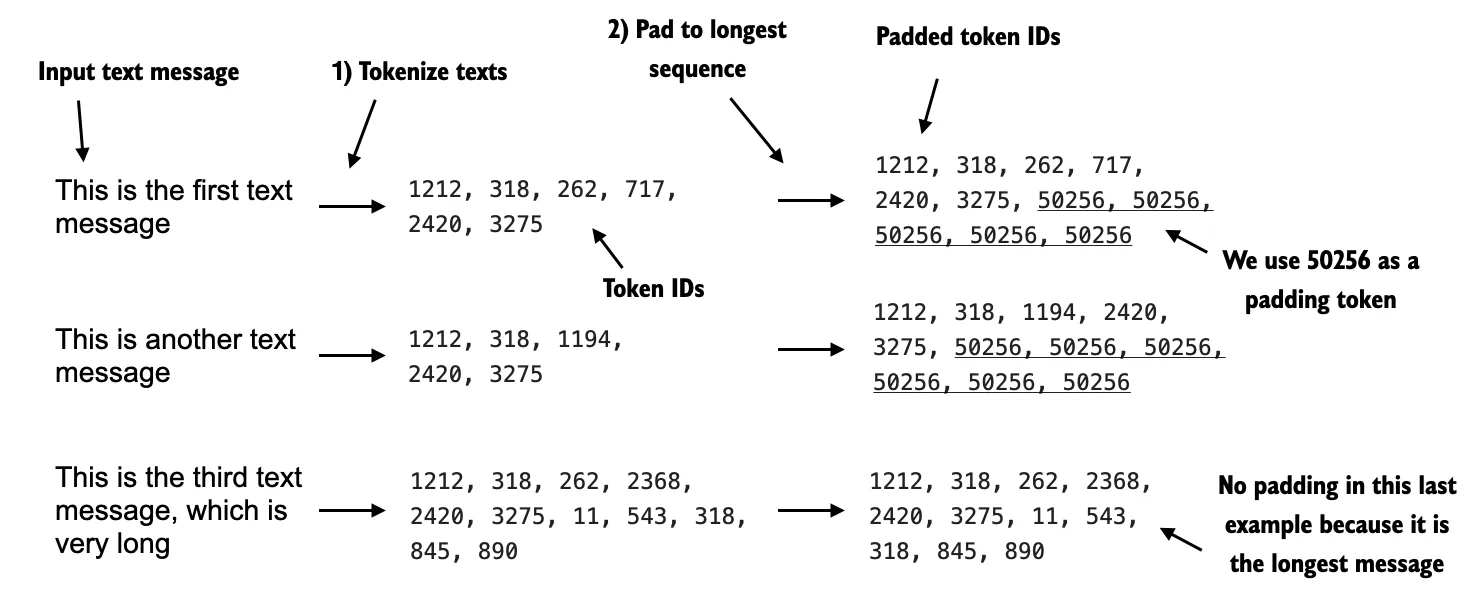
[50256]- The
SpamDatasetclass below identifies the longest sequence in the training dataset and adds the padding token to the others to match that sequence length
120We also pad the validation and test set to the longest training sequence
Note that validation and test set samples that are longer than the longest training example are being truncated via
encoded_text[:self.max_length]in theSpamDatasetcodeThis behavior is entirely optional, and it would also work well if we set
max_length=Nonein both the validation and test set casesNext, we use the dataset to instantiate the data loaders, which is similar to creating the data loaders in previous chapters
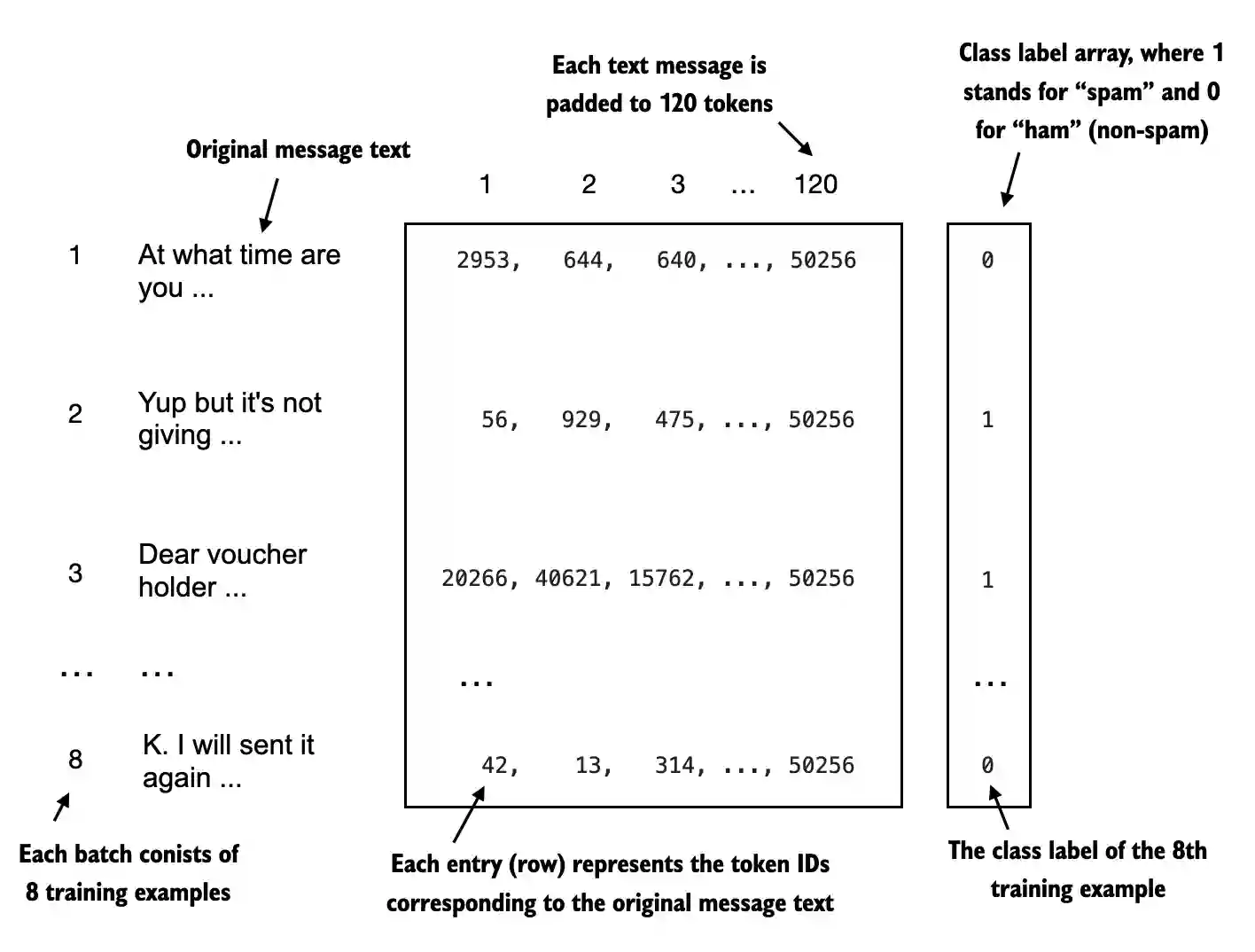
- As a verification step, we iterate through the data loaders and ensure that the batches contain 8 training examples each, where each training example consists of 120 tokens
Train loader:
Input batch dimensions: torch.Size([8, 120])
Label batch dimensions torch.Size([8])- Lastly, let’s print the total number of batches in each dataset
130 training batches
19 validation batches
38 test batches6.4 Initializing a model with pretrained weights
- In this section, we initialize the pretrained model we worked with in the previous chapter
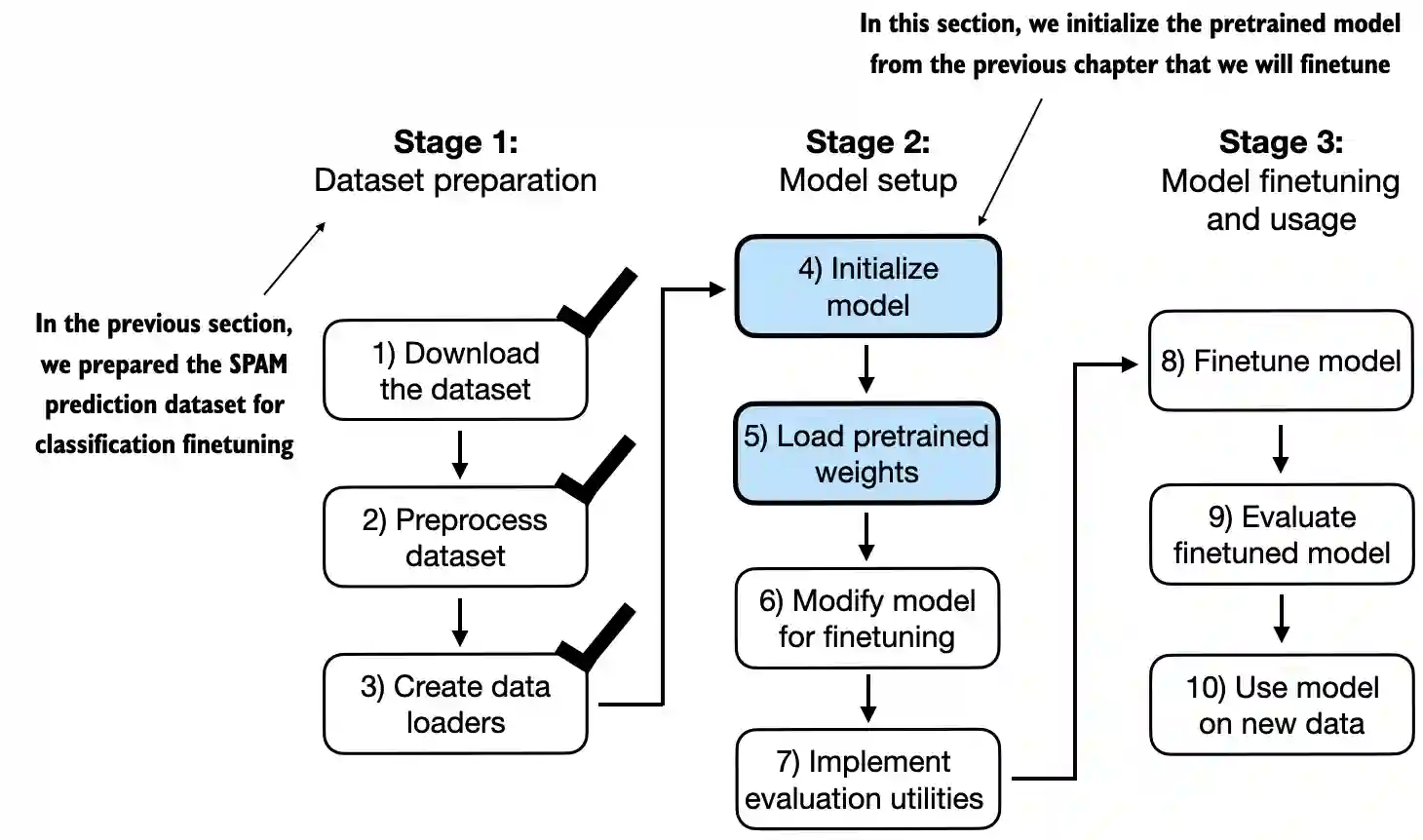
File already exists and is up-to-date: gpt2/124M/checkpoint
File already exists and is up-to-date: gpt2/124M/encoder.json
File already exists and is up-to-date: gpt2/124M/hparams.json
File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001
File already exists and is up-to-date: gpt2/124M/model.ckpt.index
File already exists and is up-to-date: gpt2/124M/model.ckpt.meta
File already exists and is up-to-date: gpt2/124M/vocab.bpe- To ensure that the model was loaded correctly, let’s double-check that it generates coherent text
Every effort moves you forward.
The first step is to understand the importance of your work- Before we finetune the model as a classifier, let’s see if the model can perhaps already classify spam messages via prompting
Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner- As we can see, the model is not very good at following instructions
- This is expected, since it has only been pretrained and not instruction-finetuned (instruction finetuning will be covered in the next chapter)
6.5 Adding a classification head

- In this section, we are modifying the pretrained LLM to make it ready for classification finetuning
- Let’s take a look at the model architecture first
GPTModel(
(tok_emb): Embedding(50257, 768)
(pos_emb): Embedding(1024, 768)
(drop_emb): Dropout(p=0.0, inplace=False)
(trf_blocks): Sequential(
(0): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(1): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(2): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(3): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(4): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(5): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(6): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(7): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(8): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(9): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(10): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
(11): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
)
(final_norm): LayerNorm()
(out_head): Linear(in_features=768, out_features=50257, bias=False)
)Above, we can see the architecture we implemented in chapter 4 neatly laid out
The goal is to replace and finetune the output layer
To achieve this, we first freeze the model, meaning that we make all layers non-trainable
Then, we replace the output layer (
model.out_head), which originally maps the layer inputs to 50,257 dimensions (the size of the vocabulary)Since we finetune the model for binary classification (predicting 2 classes, “spam” and “not spam”), we can replace the output layer as shown below, which will be trainable by default
Note that we use
BASE_CONFIG["emb_dim"](which is equal to 768 in the"gpt2-small (124M)"model) to keep the code below more generalTechnically, it’s sufficient to only train the output layer
However, as I found in Finetuning Large Language Models, experiments show that finetuning additional layers can noticeably improve the performance
So, we are also making the last transformer block and the final
LayerNormmodule connecting the last transformer block to the output layer trainable
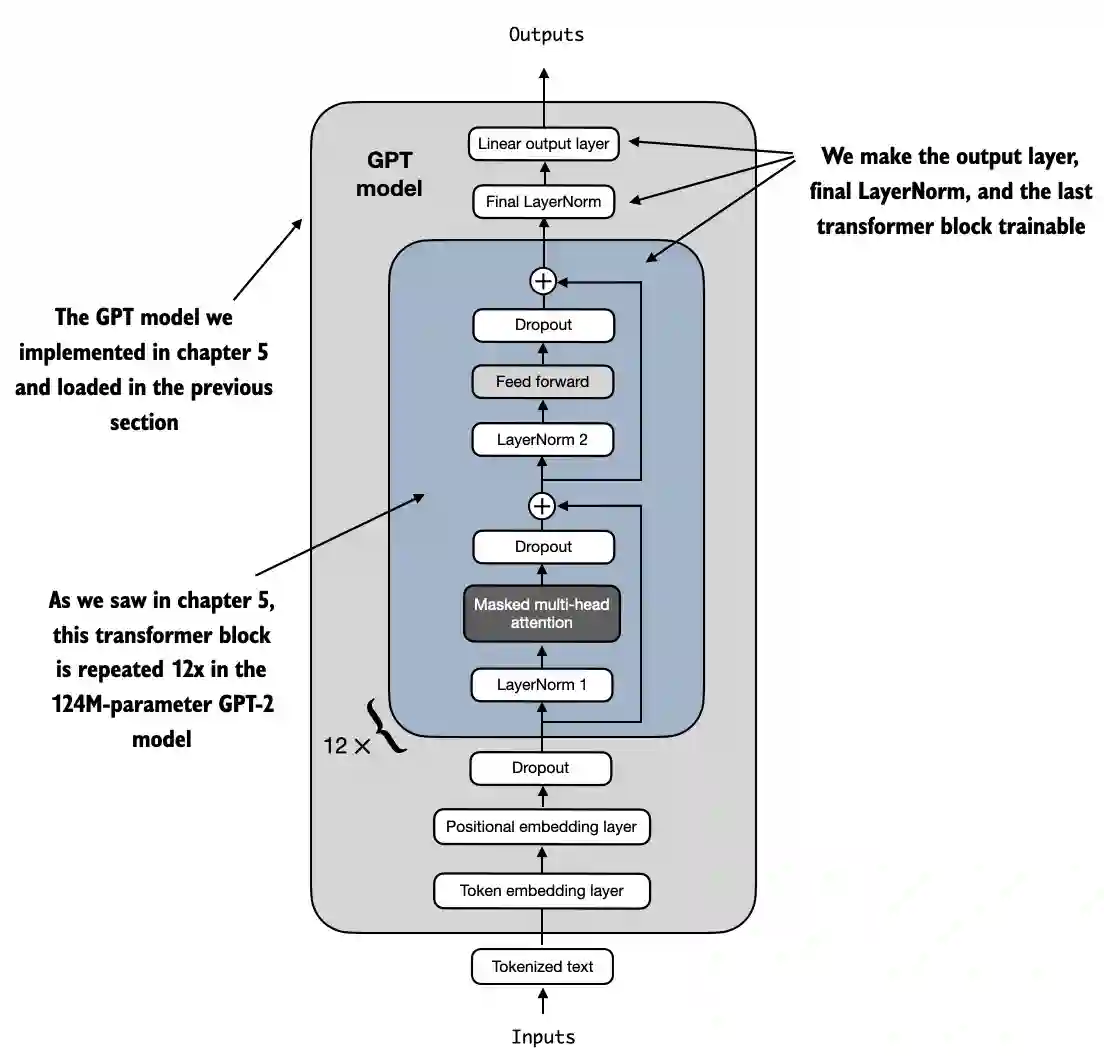
- We can still use this model similar to before in previous chapters
- For example, let’s feed it some text input
Inputs: tensor([[5211, 345, 423, 640]])
Inputs dimensions: torch.Size([1, 4])- What’s different compared to previous chapters is that it now has two output dimensions instead of 50,257
Outputs:
tensor([[[-1.5854, 0.9904],
[-3.7235, 7.4548],
[-2.2661, 6.6049],
[-3.5983, 3.9902]]])
Outputs dimensions: torch.Size([1, 4, 2])- As discussed in previous chapters, for each input token, there’s one output vector
- Since we fed the model a text sample with 4 input tokens, the output consists of 4 2-dimensional output vectors above
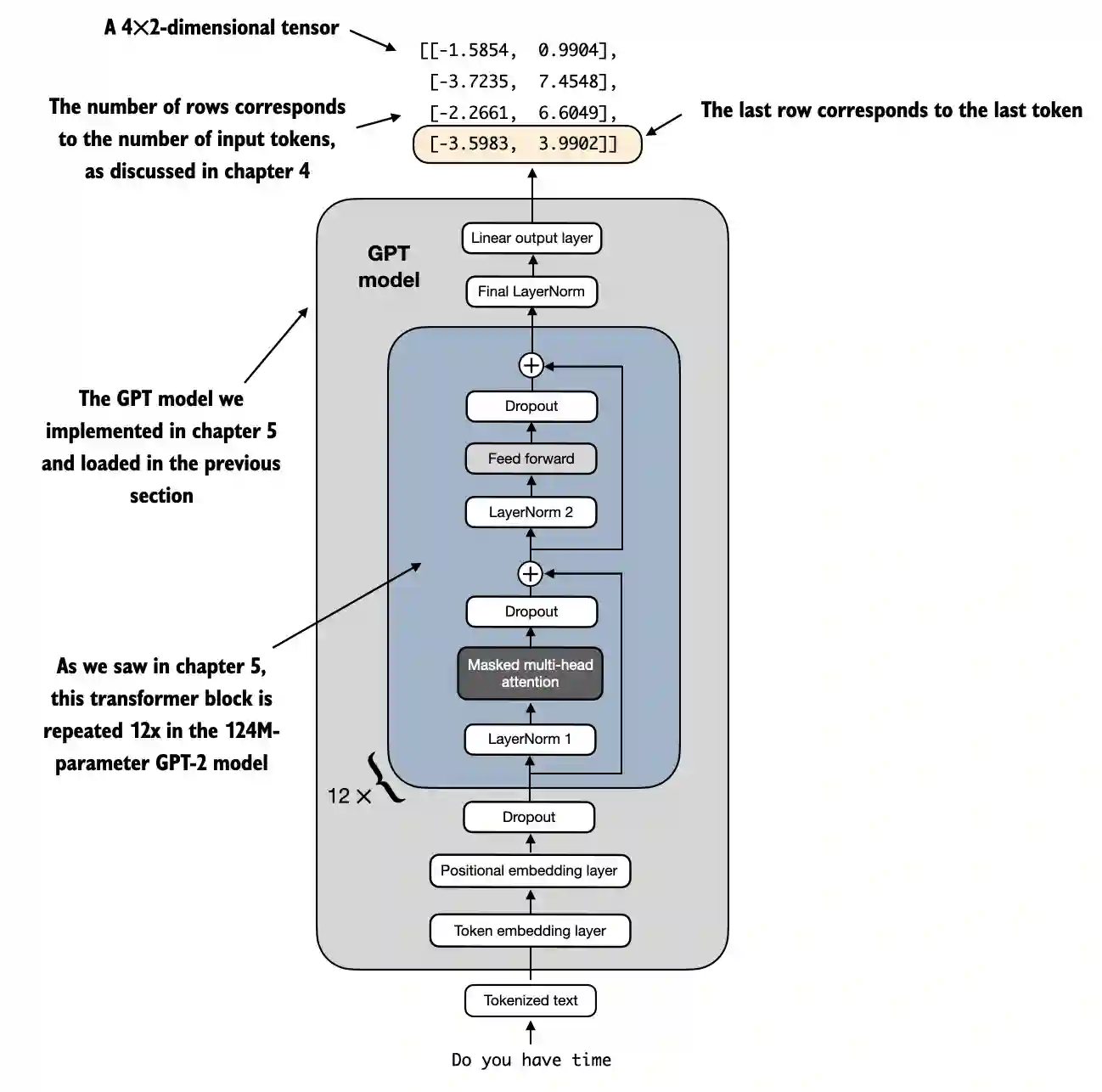
- In chapter 3, we discussed the attention mechanism, which connects each input token to each other input token
- In chapter 3, we then also introduced the causal attention mask that is used in GPT-like models; this causal mask lets a current token only attend to the current and previous token positions
- Based on this causal attention mechanism, the 4th (last) token contains the most information among all tokens because it’s the only token that includes information about all other tokens
- Hence, we are particularly interested in this last token, which we will finetune for the spam classification task
Last output token: tensor([[-3.5983, 3.9902]])
6.6 Calculating the classification loss and accuracy
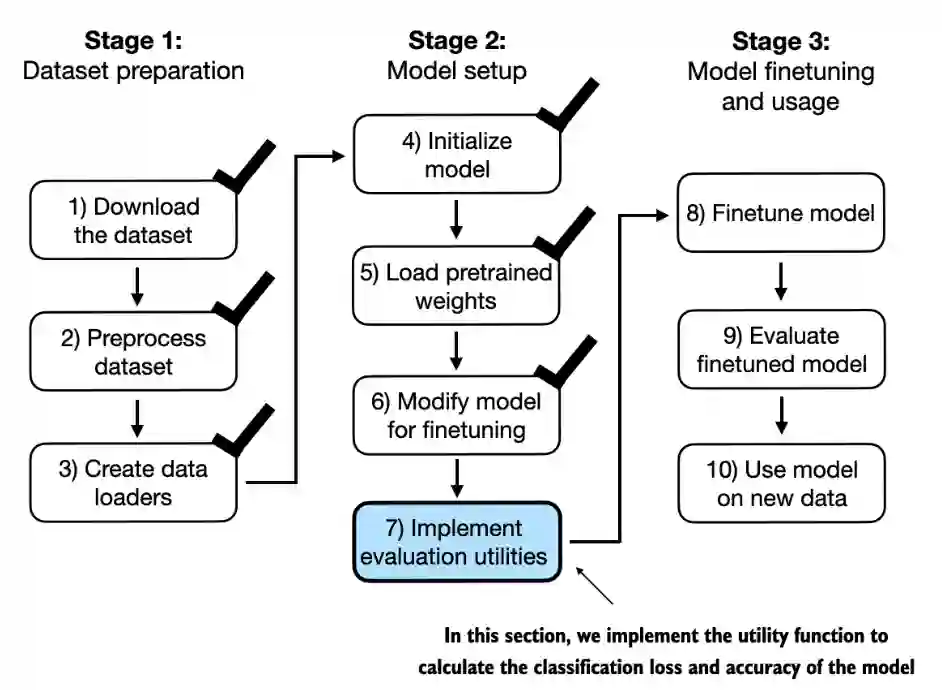
- Before explaining the loss calculation, let’s have a brief look at how the model outputs are turned into class labels
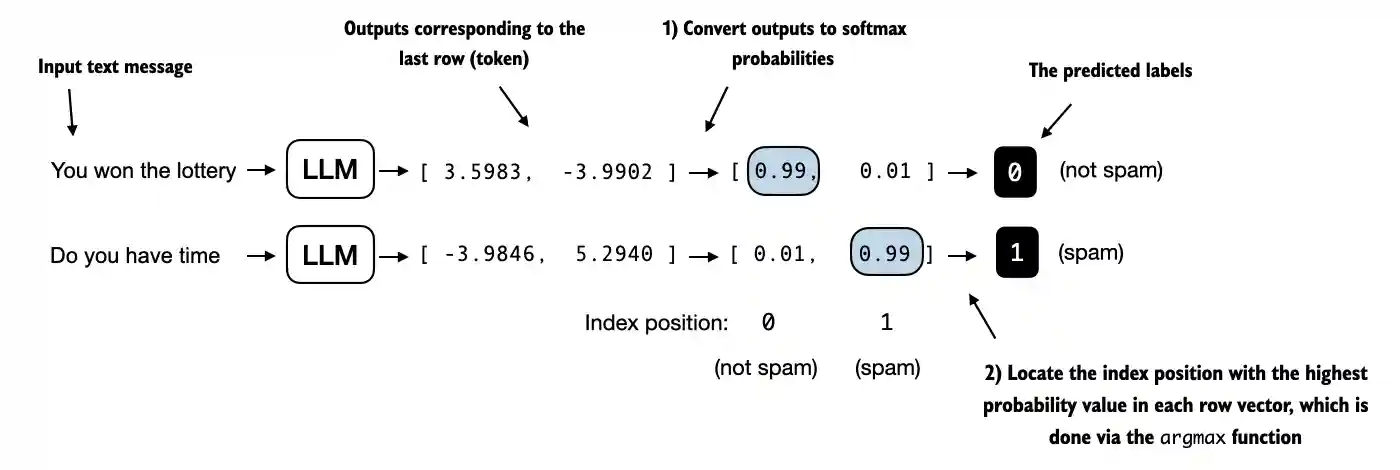
Last output token: tensor([[-3.5983, 3.9902]])- Similar to chapter 5, we convert the outputs (logits) into probability scores via the
softmaxfunction and then obtain the index position of the largest probability value via theargmaxfunction
Class label: 1- Note that the softmax function is optional here, as explained in chapter 5, because the largest outputs correspond to the largest probability scores
Class label: 1We can apply this concept to calculate the so-called classification accuracy, which computes the percentage of correct predictions in a given dataset
To calculate the classification accuracy, we can apply the preceding
argmax-based prediction code to all examples in a dataset and calculate the fraction of correct predictions as follows:Let’s apply the function to calculate the classification accuracies for the different datasets:
Training accuracy: 46.25%
Validation accuracy: 45.00%
Test accuracy: 48.75%As we can see, the prediction accuracies are not very good, since we haven’t finetuned the model, yet
Before we can start finetuning (/training), we first have to define the loss function we want to optimize during training
The goal is to maximize the spam classification accuracy of the model; however, classification accuracy is not a differentiable function
Hence, instead, we minimize the cross-entropy loss as a proxy for maximizing the classification accuracy (you can learn more about this topic in lecture 8 of my freely available Introduction to Deep Learning class)
The
calc_loss_batchfunction is the same here as in chapter 5, except that we are only interested in optimizing the last tokenmodel(input_batch)[:, -1, :]instead of all tokensmodel(input_batch)
The calc_loss_loader is exactly the same as in chapter 5
- Using the
calc_closs_loader, we compute the initial training, validation, and test set losses before we start training
Training loss: 2.453
Validation loss: 2.583
Test loss: 2.322- In the next section, we train the model to improve the loss values and consequently the classification accuracy
6.7 Finetuning the model on supervised data
- In this section, we define and use the training function to improve the classification accuracy of the model
- The
train_classifier_simplefunction below is practically the same as thetrain_model_simplefunction we used for pretraining the model in chapter 5 - The only two differences are that we now
- track the number of training examples seen (
examples_seen) instead of the number of tokens seen - calculate the accuracy after each epoch instead of printing a sample text after each epoch
- track the number of training examples seen (
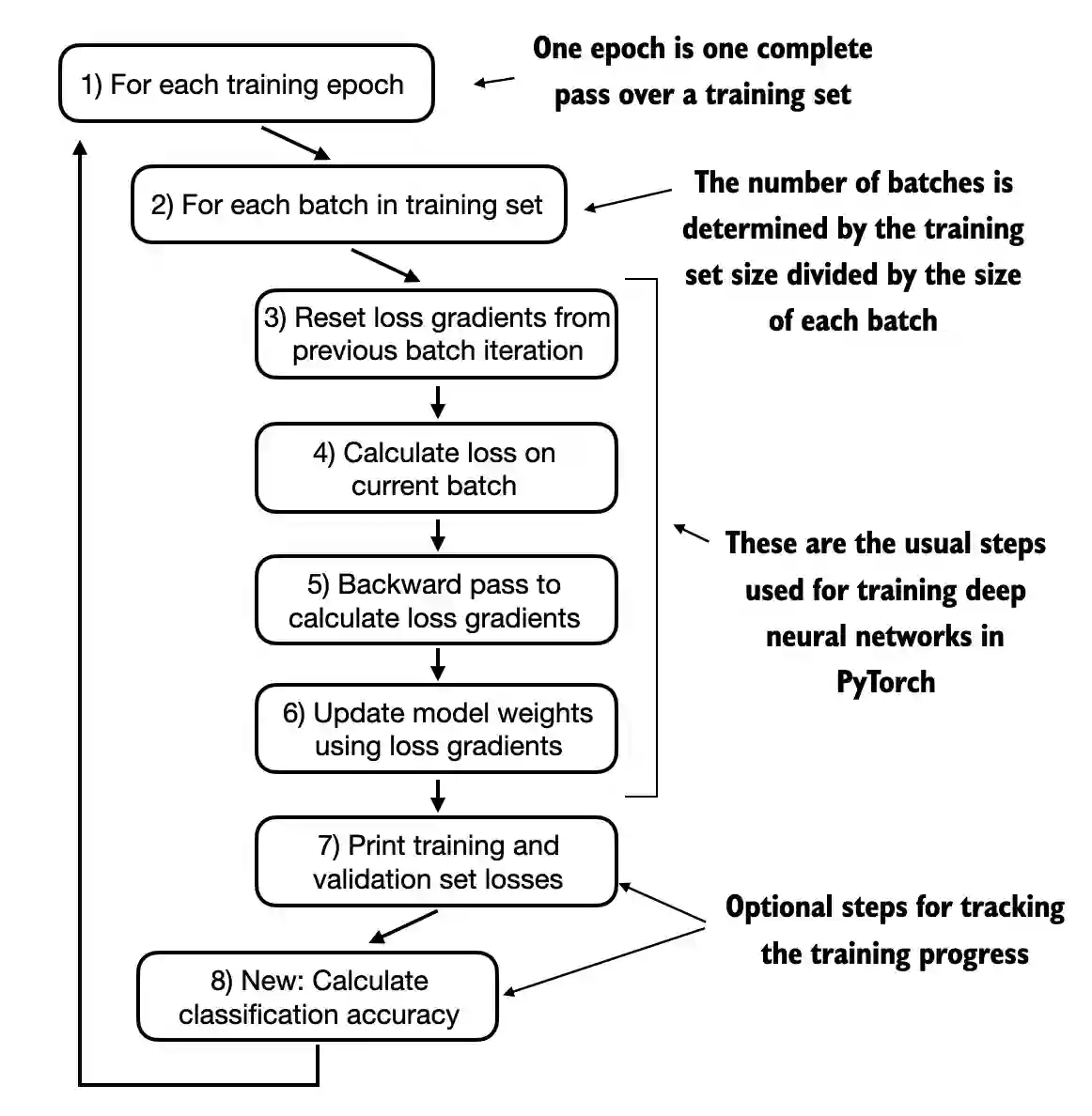
The
evaluate_modelfunction used in thetrain_classifier_simpleis the same as the one we used in chapter 5The training takes about 5 minutes on a M3 MacBook Air laptop computer and less than half a minute on a V100 or A100 GPU
Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392
Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637
Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557
Training accuracy: 70.00% | Validation accuracy: 72.50%
Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489
Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397
Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353
Training accuracy: 82.50% | Validation accuracy: 85.00%
Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320
Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306
Training accuracy: 90.00% | Validation accuracy: 90.00%
Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200
Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132
Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137
Training accuracy: 100.00% | Validation accuracy: 97.50%
Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143
Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074
Training accuracy: 100.00% | Validation accuracy: 97.50%
Training completed in 5.31 minutes.- Similar to chapter 5, we use matplotlib to plot the loss function for the training and validation set
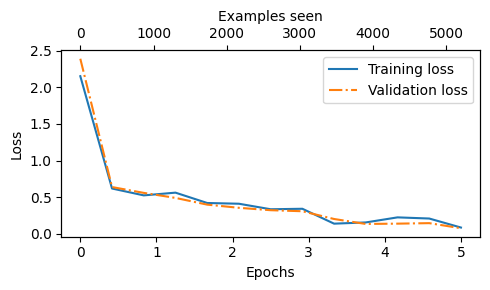
- Above, based on the downward slope, we see that the model learns well
- Furthermore, the fact that the training and validation loss are very close indicates that the model does not tend to overfit the training data
- Similarly, we can plot the accuracy below
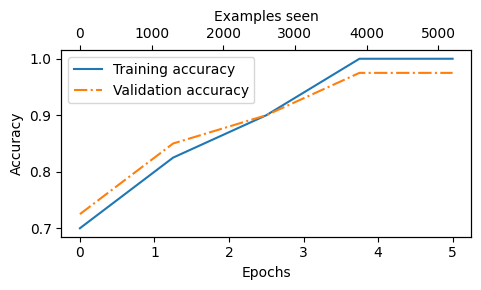
- Based on the accuracy plot above, we can see that the model achieves a relatively high training and validation accuracy after epochs 4 and 5
- However, we have to keep in mind that we specified
eval_iter=5in the training function earlier, which means that we only estimated the training and validation set performances - We can compute the training, validation, and test set performances over the complete dataset as follows below
Training accuracy: 97.21%
Validation accuracy: 97.32%
Test accuracy: 95.67%- We can see that the training and validation set performances are practically identical
- However, based on the slightly lower test set performance, we can see that the model overfits the training data to a very small degree, as well as the validation data that has been used for tweaking some of the hyperparameters, such as the learning rate
- This is normal, however, and this gap could potentially be further reduced by increasing the model’s dropout rate (
drop_rate) or theweight_decayin the optimizer setting
6.8 Using the LLM as a spam classifier
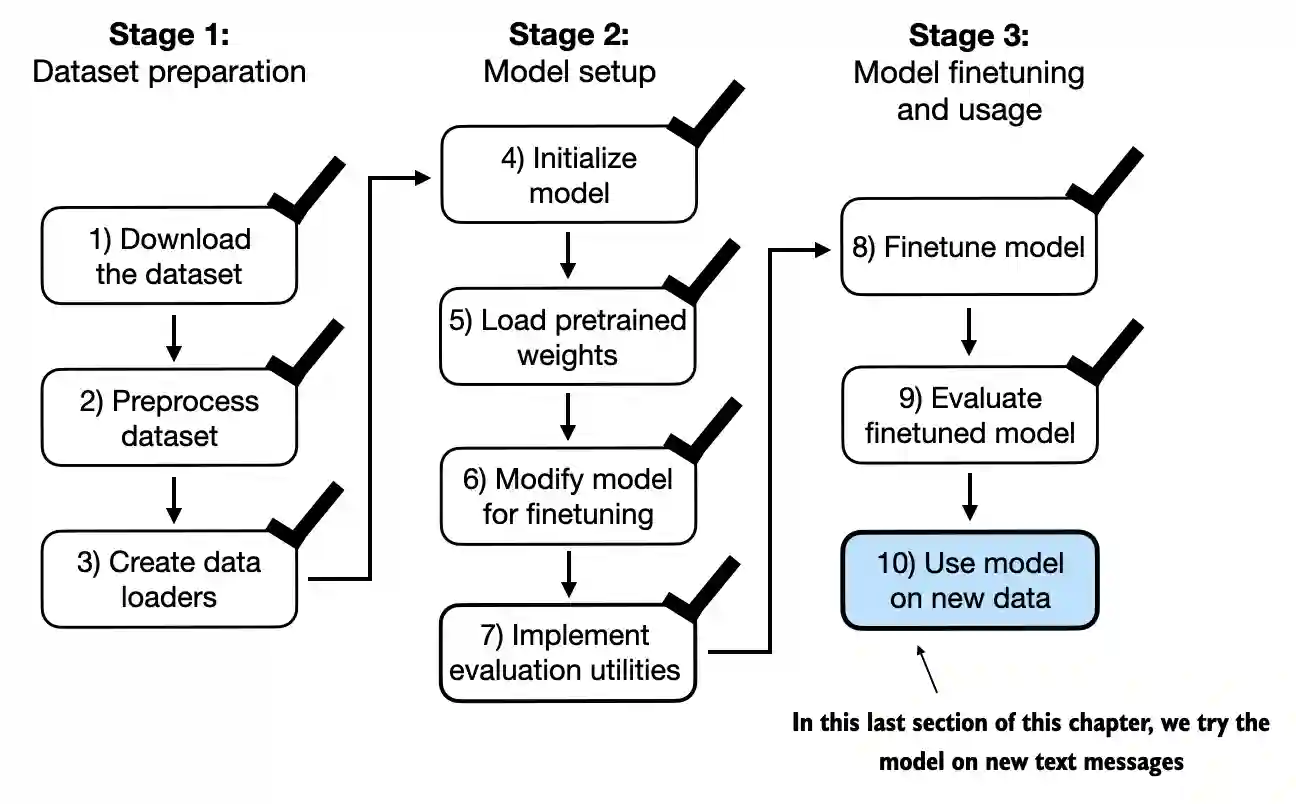
Finally, let’s use the finetuned GPT model in action
The
classify_reviewfunction below implements the data preprocessing steps similar to theSpamDatasetwe implemented earlierThen, the function returns the predicted integer class label from the model and returns the corresponding class name
Let’s try it out on a few examples below
spamnot spamFinally, let’s save the model in case we want to reuse the model later without having to train it again
Then, in a new session, we could load the model as follows
<All keys matched successfully>Summary and takeaways
- See the ./gpt_class_finetune.py script, a self-contained script for classification finetuning
- You can find the exercise solutions in ./exercise-solutions.ipynb
- In addition, interested readers can find an introduction to parameter-efficient training with low-rank adaptation (LoRA) in appendix E
7. Finetuning to Follow Instruction
numpy version: 2.0.2
matplotlib version: 3.10.0
tiktoken version: 0.8.0
torch version: 2.5.1+cu124
tqdm version: 4.67.1
tensorflow version: 2.18.0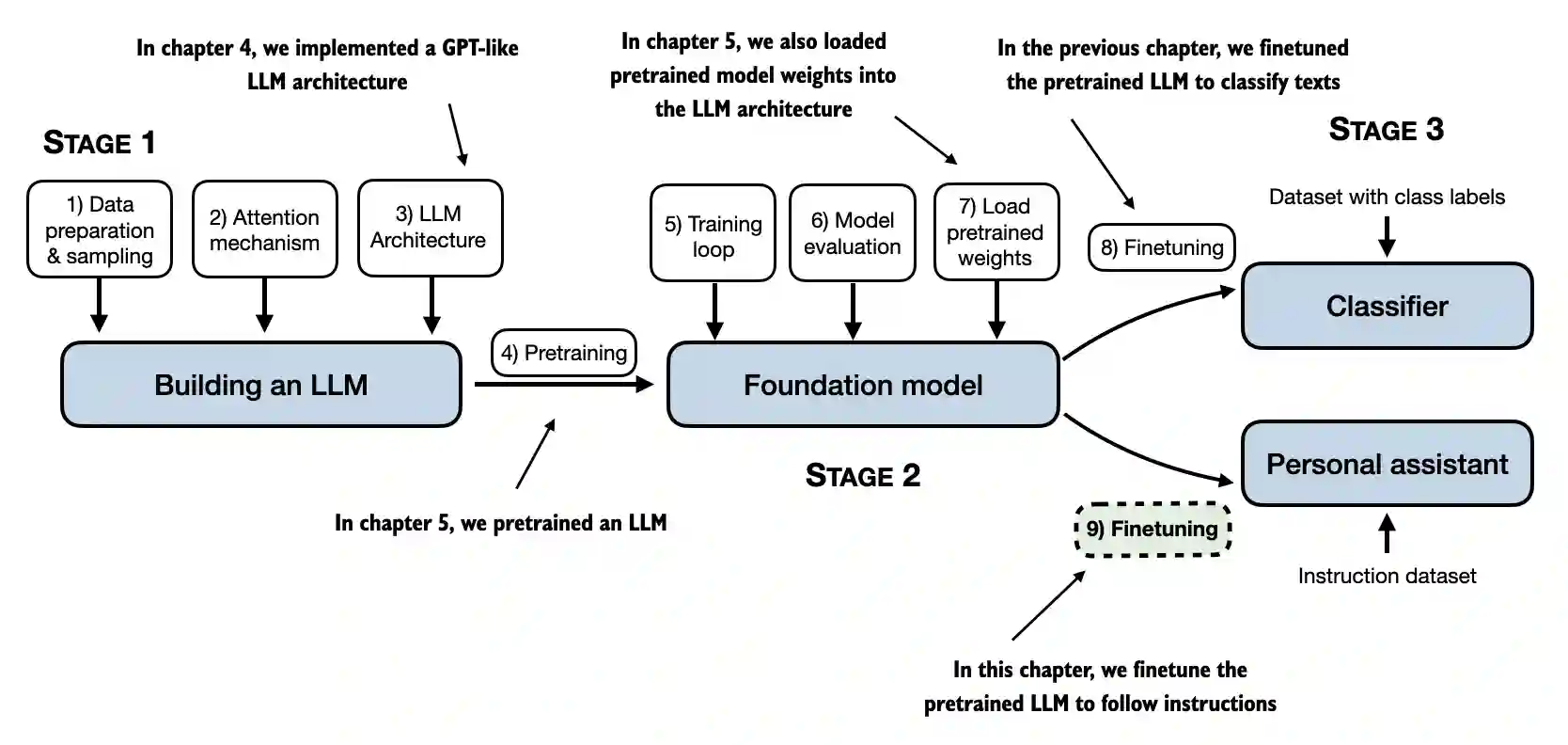
7.1 Introduction to instruction finetuning
- In chapter 5, we saw that pretraining an LLM involves a training procedure where it learns to generate one word at a time
- Hence, a pretrained LLM is good at text completion, but it is not good at following instructions
- In this chapter, we teach the LLM to follow instructions better
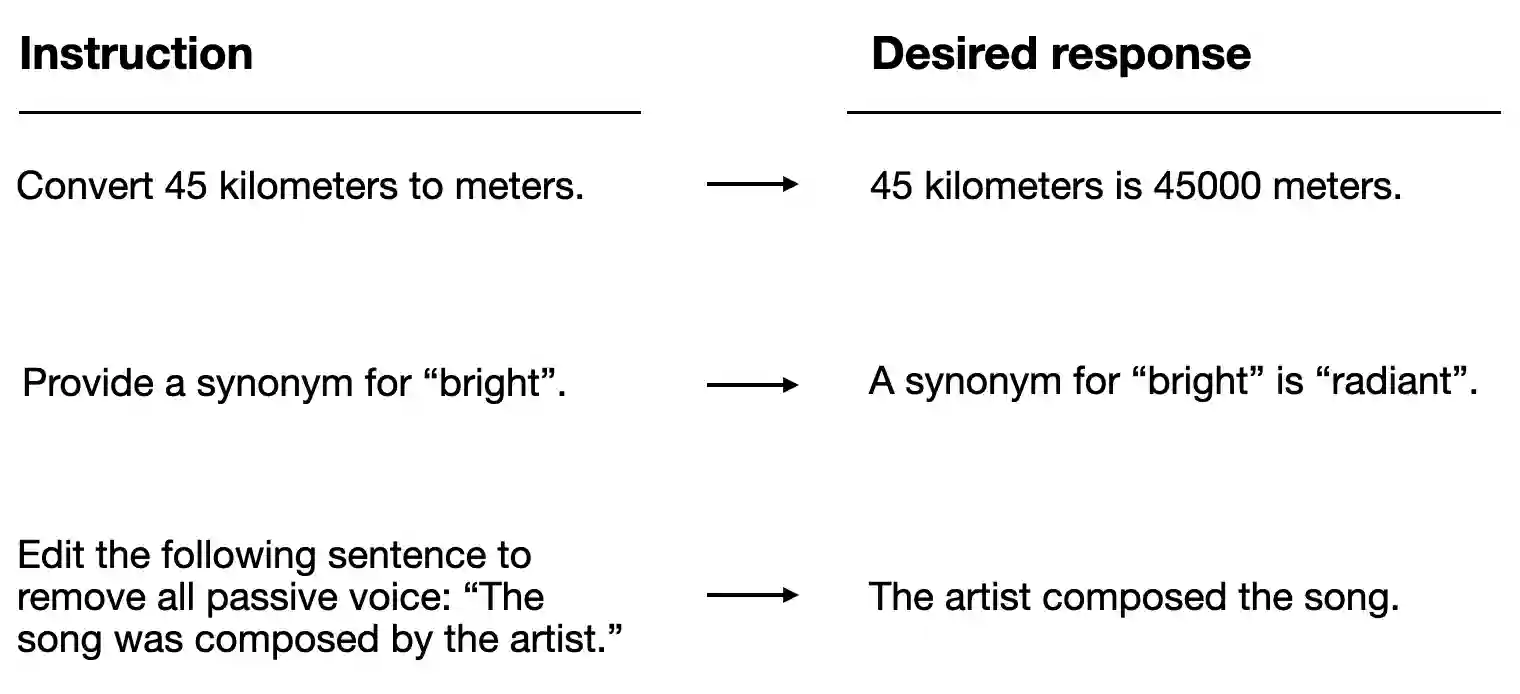
- The topics covered in this chapter are summarized in the figure below
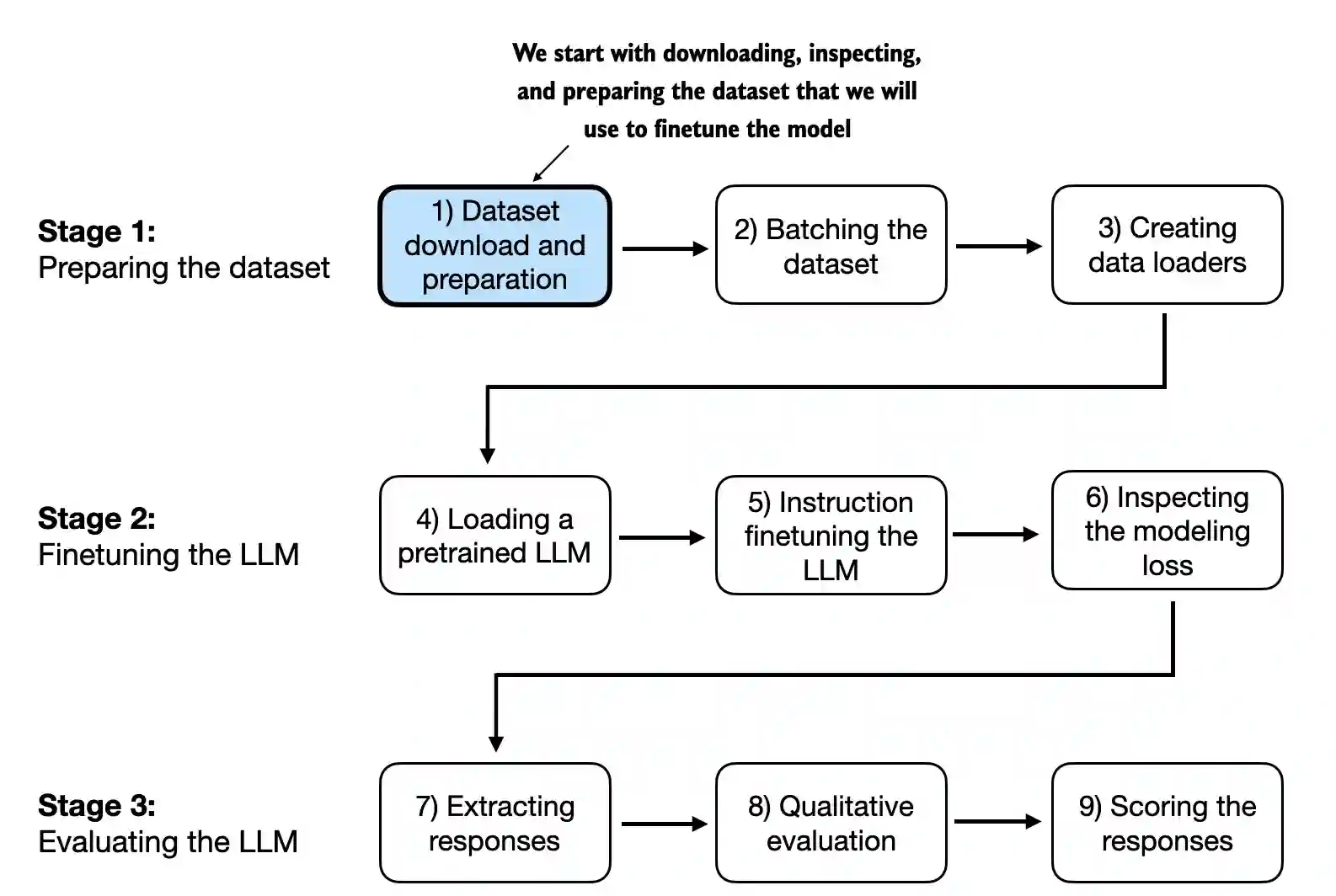
7.2 Preparing a dataset for supervised instruction finetuning
- We will work with an instruction dataset I prepared for this chapter
Number of entries: 1100- Each item in the
datalist we loaded from the JSON file above is a dictionary in the following form
Example entry:
{'instruction': 'Identify the correct spelling of the following word.', 'input': 'Ocassion', 'output': "The correct spelling is 'Occasion.'"}- Note that the
'input'field can be empty:
Another example entry:
{'instruction': "What is an antonym of 'complicated'?", 'input': '', 'output': "An antonym of 'complicated' is 'simple'."}- Instruction finetuning is often referred to as “supervised instruction finetuning” because it involves training a model on a dataset where the input-output pairs are explicitly provided
- There are different ways to format the entries as inputs to the LLM; the figure below illustrates two example formats that were used for training the Alpaca (https://crfm.stanford.edu/2023/03/13/alpaca.html) and Phi-3 (https://arxiv.org/abs/2404.14219) LLMs, respectively
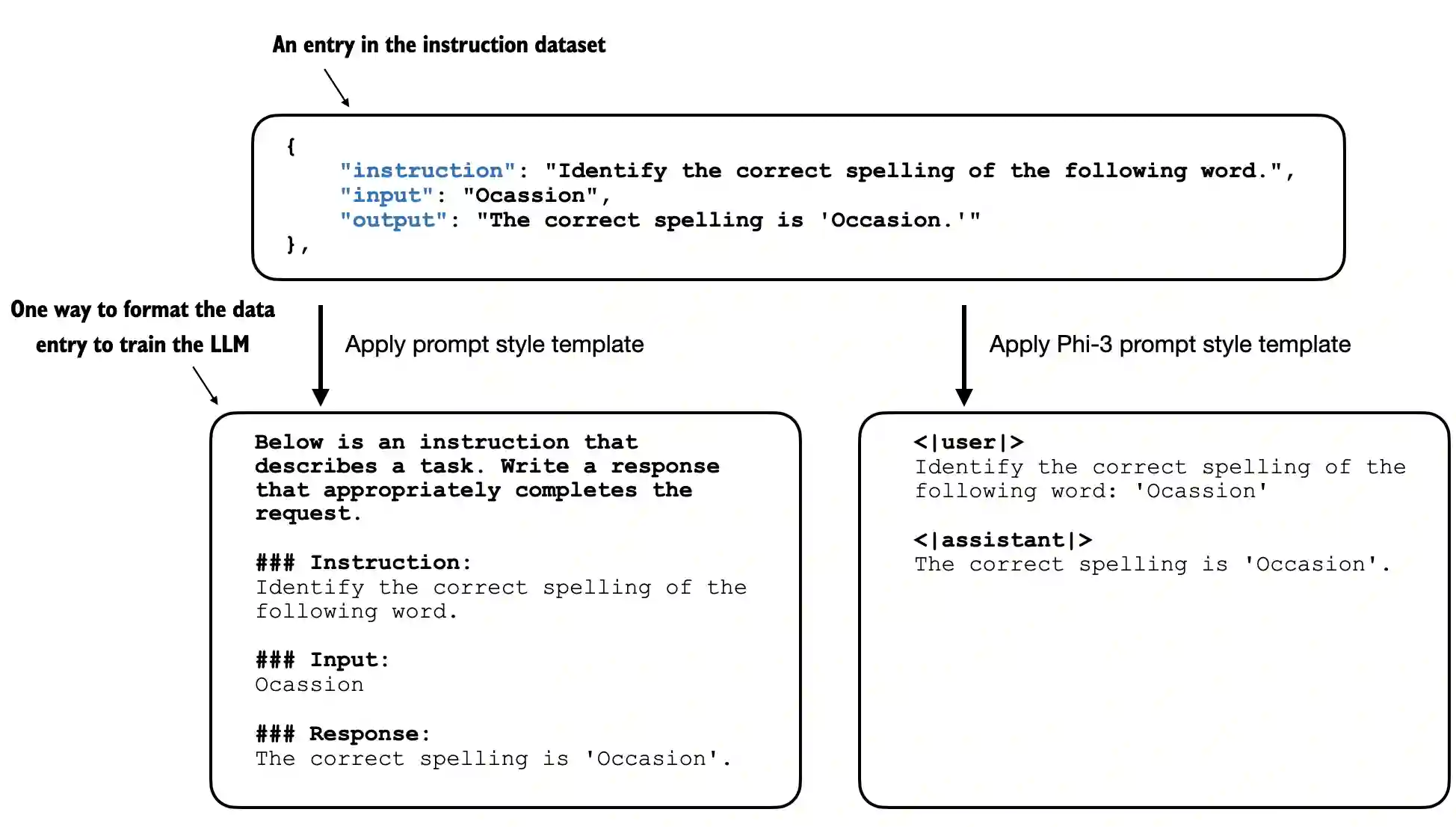
In this chapter, we use Alpaca-style prompt formatting, which was the original prompt template for instruction finetuning
Below, we format the input that we will pass as input to the LLM
A formatted response with input field looks like as shown below
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion
### Response:
The correct spelling is 'Occasion.'- Below is a formatted response without an input field
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is an antonym of 'complicated'?
### Response:
An antonym of 'complicated' is 'simple'.- Lastly, before we prepare the PyTorch data loaders in the next section, we divide the dataset into a training, validation, and test set
Training set length: 935
Validation set length: 55
Test set length: 1107.3 Organizing data into training batches
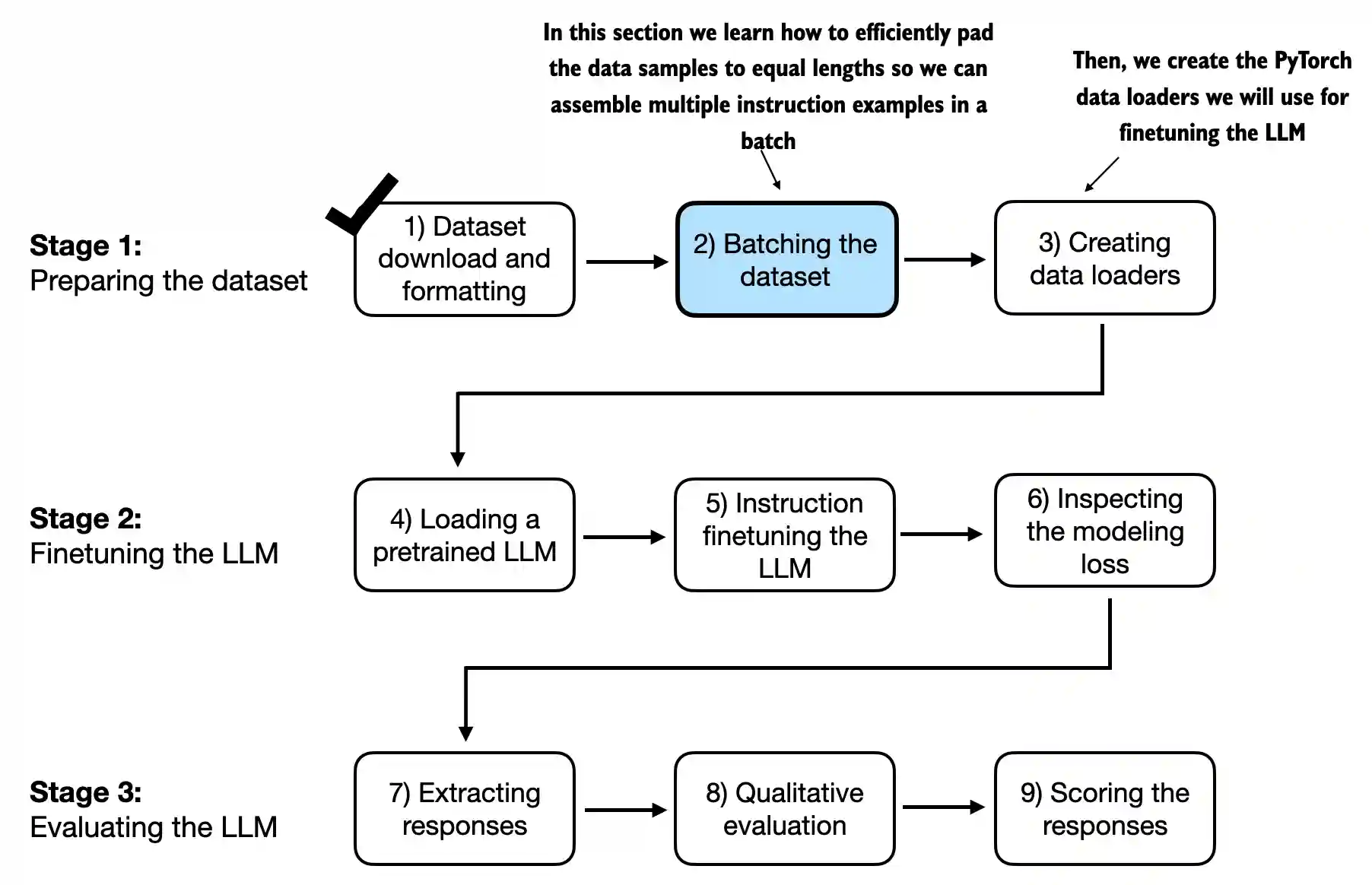
- We tackle this dataset batching in several steps, as summarized in the figure below
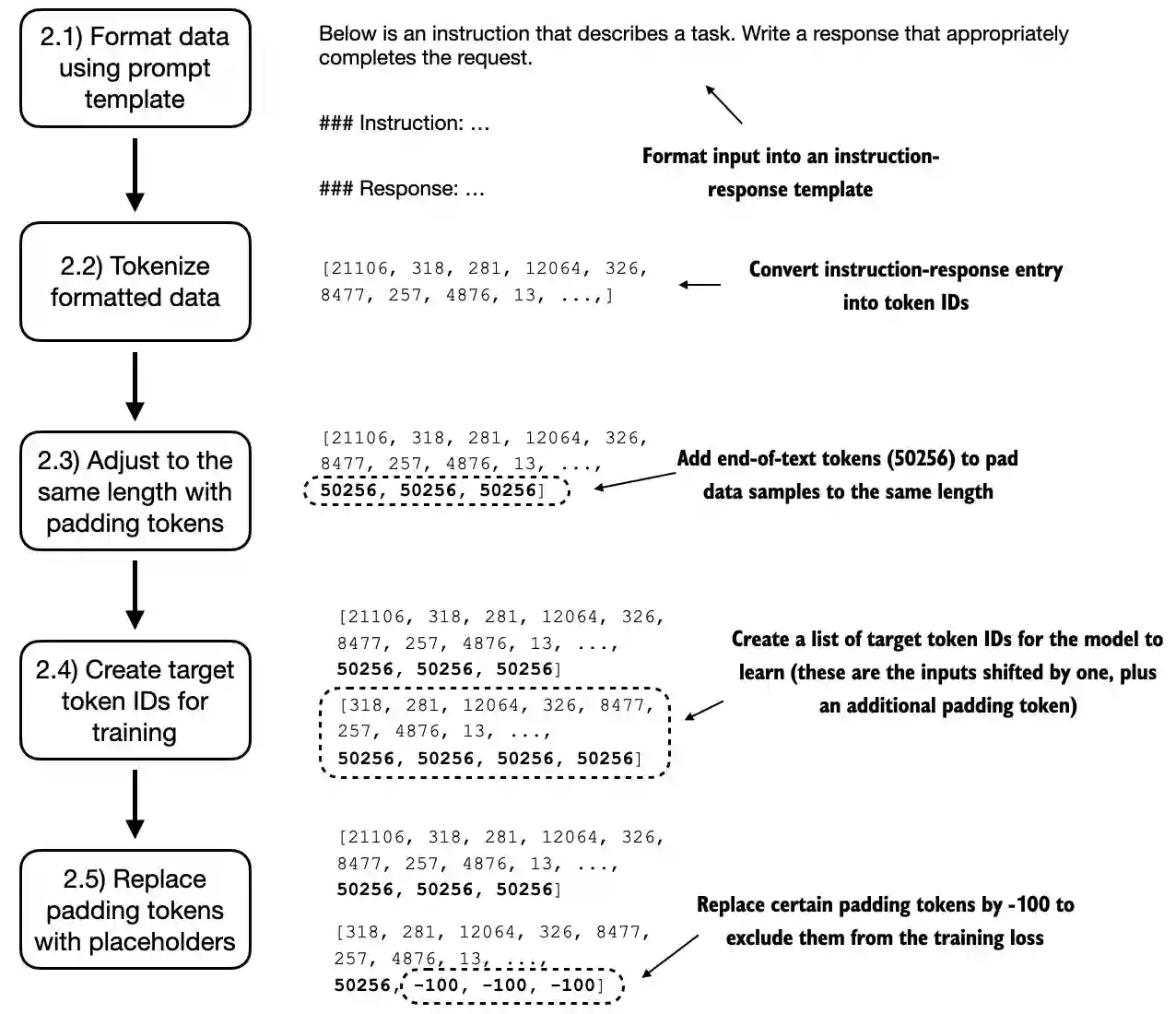
- First, we implement an
InstructionDatasetclass that pre-tokenizes all inputs in the dataset, similar to theSpamDatasetin chapter 6
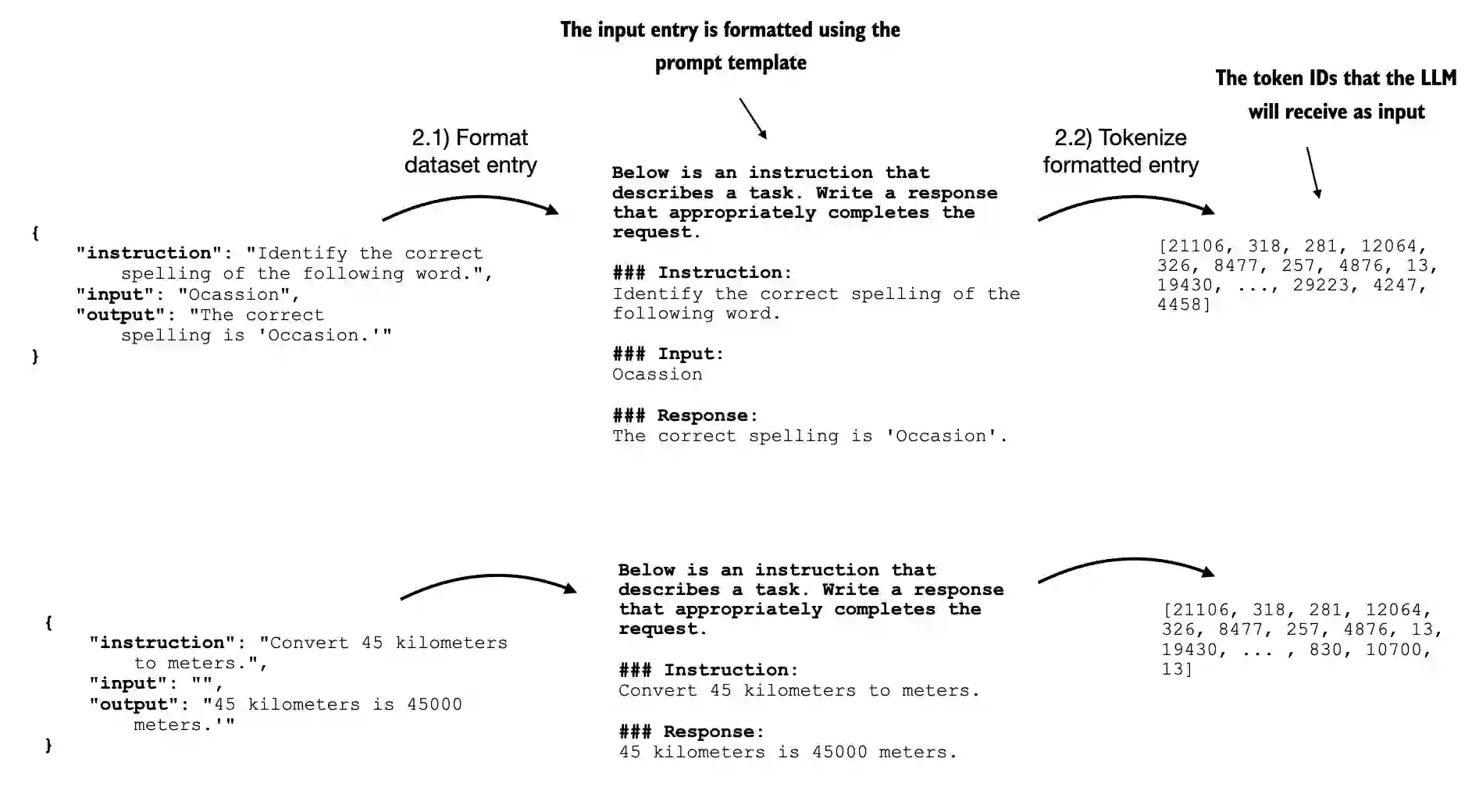
- Similar to chapter 6, we want to collect multiple training examples in a batch to accelerate training; this requires padding all inputs to a similar length
- Also similar to the previous chapter, we use the
<|endoftext|>token as a padding token
[50256]- In chapter 6, we padded all examples in a dataset to the same length
- Here, we take a more sophisticated approach and develop a custom “collate” function that we can pass to the data loader
- This custom collate function pads the training examples in each batch to have the same length (but different batches can have different lengths)
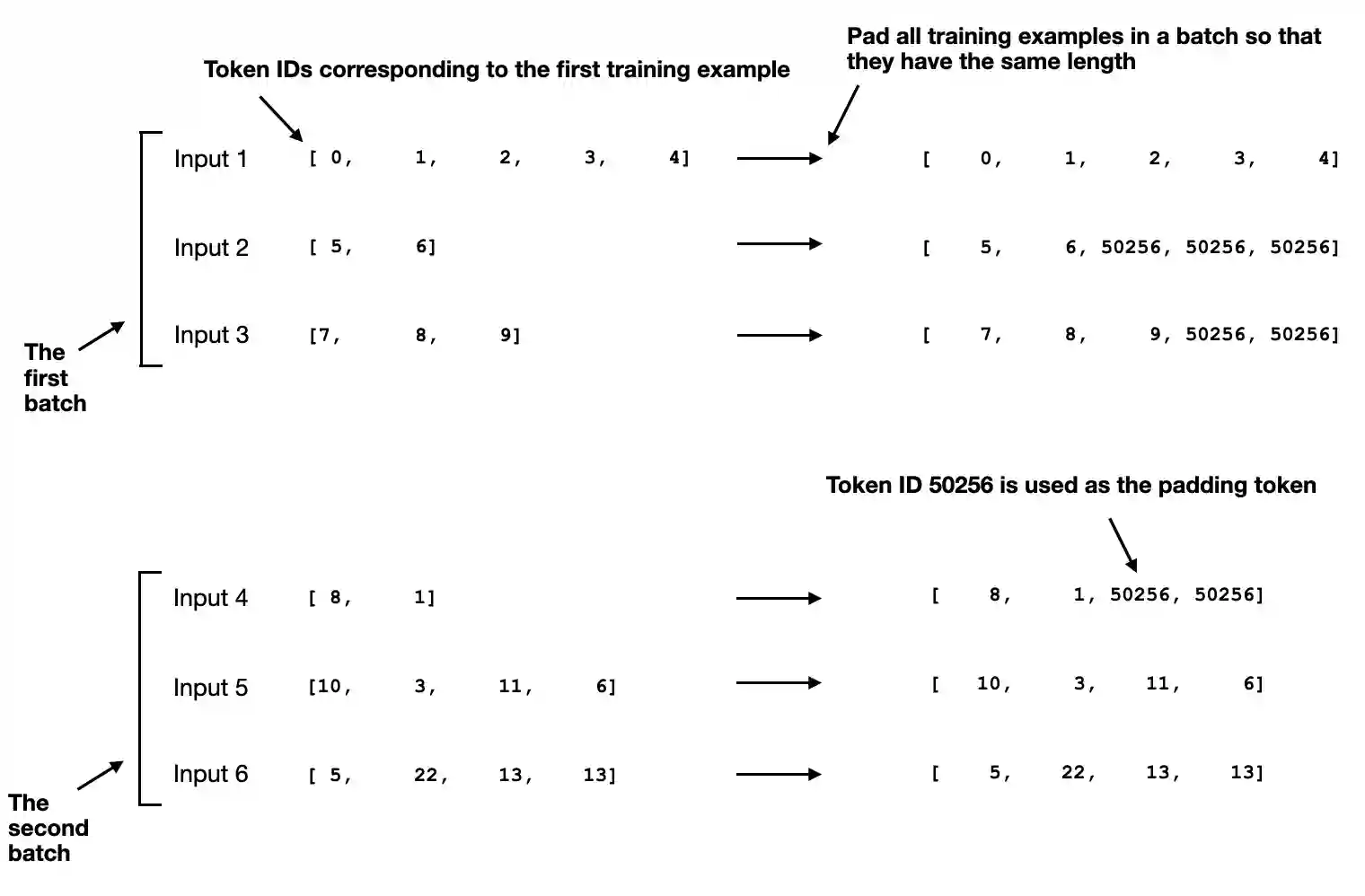
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])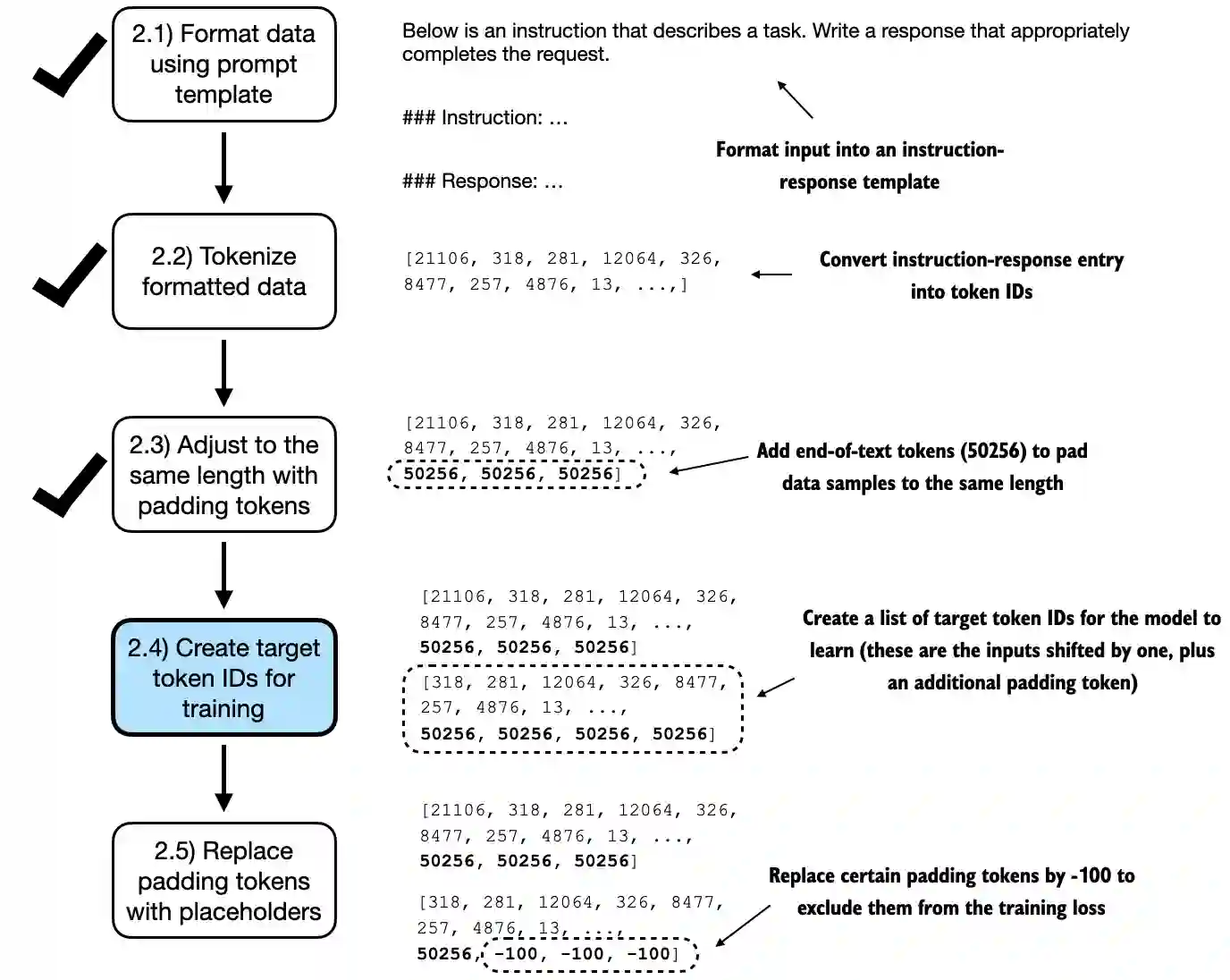
- Above, we only returned the inputs to the LLM; however, for LLM training, we also need the target values
- Similar to pretraining an LLM, the targets are the inputs shifted by 1 position to the right, so the LLM learns to predict the next token
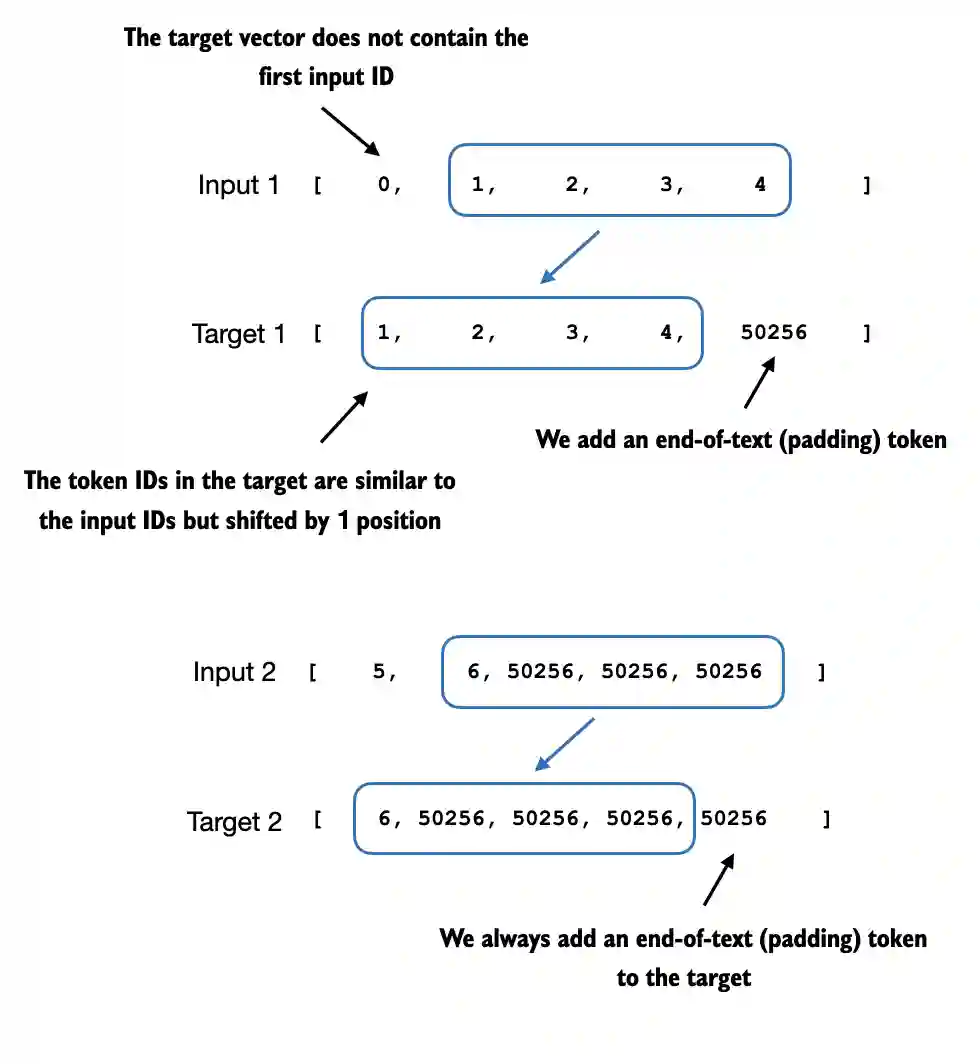
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, 50256, 50256, 50256],
[ 8, 9, 50256, 50256, 50256]])- Next, we introduce an
ignore_indexvalue to replace all padding token IDs with a new value; the purpose of thisignore_indexis that we can ignore padding values in the loss function (more on that later)
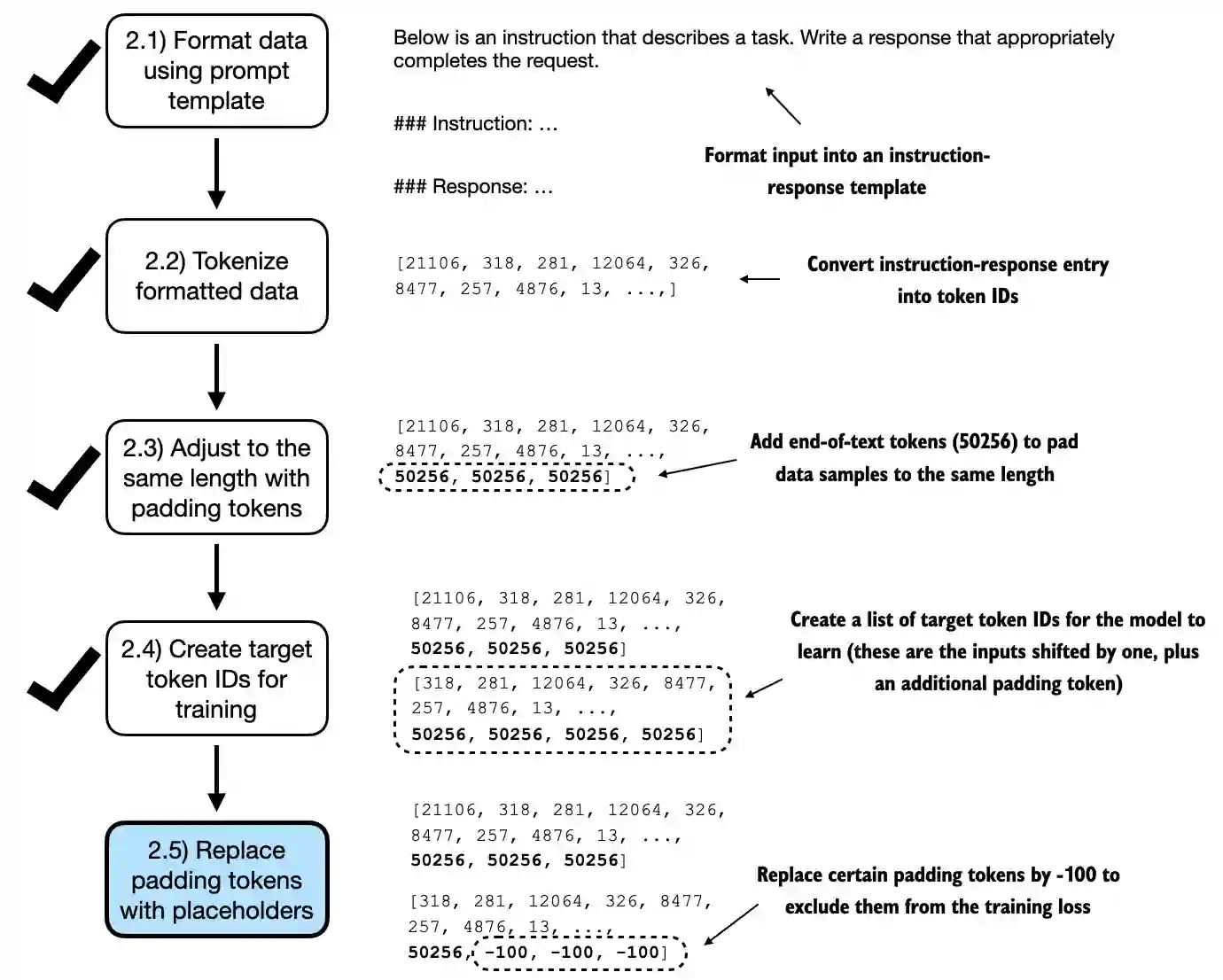
- Concretely, this means that we replace the token IDs corresponding to
50256with-100as illustrated below
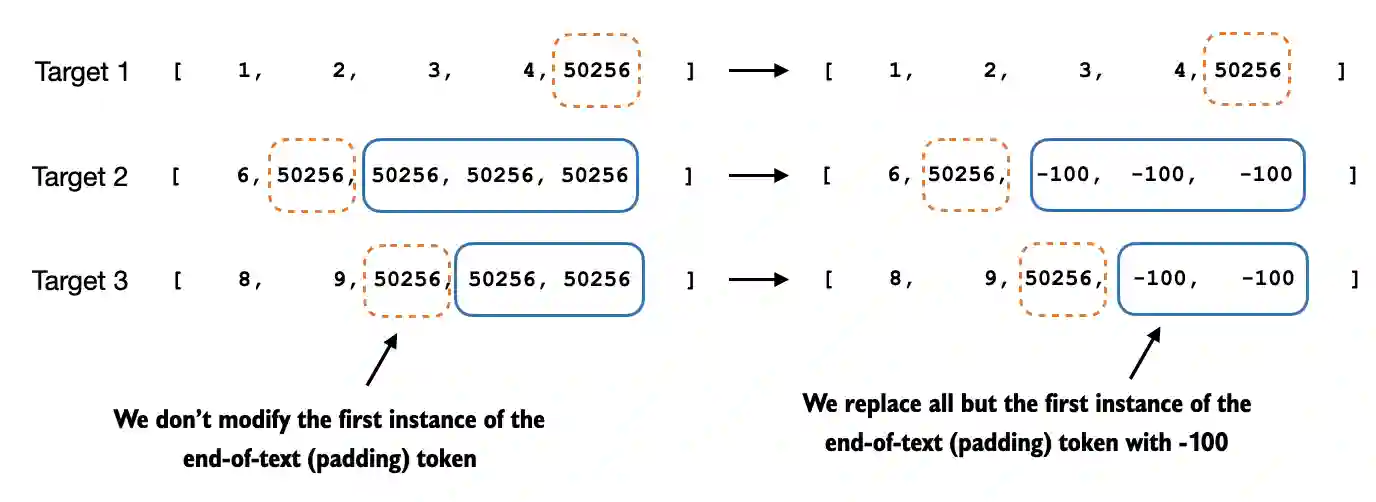
- (In addition, we also introduce the
allowed_max_lengthin case we want to limit the length of the samples; this will be useful if you plan to work with your own datasets that are longer than the 1024 token context size supported by the GPT-2 model)
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, -100, -100, -100],
[ 8, 9, 50256, -100, -100]])- Let’s see what this replacement by -100 accomplishes
- For illustration purposes, let’s assume we have a small classification task with 2 class labels, 0 and 1, similar to chapter 6
- If we have the following logits values (outputs of the last layer of the model), we calculate the following loss
tensor(1.1269)- Now, adding one more training example will, as expected, influence the loss
tensor(0.7936)- Let’s see what happens if we replace the class label of one of the examples with -100
tensor(1.1269)
loss_1 == loss_3: tensor(True)As we can see, the resulting loss on these 3 training examples is the same as the loss we calculated from the 2 training examples, which means that the cross-entropy loss function ignored the training example with the -100 label
By default, PyTorch has the
cross_entropy(..., ignore_index=-100)setting to ignore examples corresponding to the label -100Using this -100
ignore_index, we can ignore the additional end-of-text (padding) tokens in the batches that we used to pad the training examples to equal lengthHowever, we don’t want to ignore the first instance of the end-of-text (padding) token (50256) because it can help signal to the LLM when the response is complete
In practice, it is also common to mask out the target token IDs that correspond to the instruction, as illustrated in the figure below (this is a recommended reader exercise after completing the chapter)

7.4 Creating data loaders for an instruction dataset
- In this section, we use the
InstructionDatasetclass andcustom_collate_fnfunction to instantiate the training, validation, and test data loaders

- Another additional detail of the previous
custom_collate_fnfunction is that we now directly move the data to the target device (e.g., GPU) instead of doing it in the main training loop, which improves efficiency because it can be carried out as a background process when we use thecustom_collate_fnas part of the data loader - Using the
partialfunction from Python’sfunctoolsstandard library, we create a new function with thedeviceargument of the original function pre-filled
Device: cudaNext, we instantiate the data loaders similar to previous chapters, except that we now provide our own collate function for the batching process
Let’s see what the dimensions of the resulting input and target batches look like
Train loader:
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 59]) torch.Size([8, 59])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 89]) torch.Size([8, 89])
torch.Size([8, 59]) torch.Size([8, 59])
torch.Size([8, 88]) torch.Size([8, 88])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 58]) torch.Size([8, 58])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 57]) torch.Size([8, 57])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 82]) torch.Size([8, 82])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 69]) torch.Size([8, 69])- As we can see based on the output above, all batches have a batch size of 8 but a different length, as expected
- Let’s also double-check that the inputs contain the
<|endoftext|>padding tokens corresponding to token ID 50256 by printing the contents of the first training example in theinputsbatch
tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257,
985, 576, 13, 198, 198, 21017, 23412, 25, 198, 464,
5156, 318, 845, 13779, 13, 198, 198, 21017, 18261, 25,
198, 464, 5156, 318, 355, 13779, 355, 257, 4936, 13,
50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256],
device='cuda:0')- Similarly, we visually double-check that the targets contain the -100 placeholder tokens
tensor([ 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430, 257,
2882, 326, 20431, 32543, 262, 2581, 13, 198, 198, 21017,
46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257, 985,
576, 13, 198, 198, 21017, 23412, 25, 198, 464, 5156,
318, 845, 13779, 13, 198, 198, 21017, 18261, 25, 198,
464, 5156, 318, 355, 13779, 355, 257, 4936, 13, 50256,
-100, -100, -100, -100, -100, -100, -100, -100, -100],
device='cuda:0')7.5 Loading a pretrained LLM
- In this section, we load a pretrained GPT model using the same code that we used in section 5.5 of chapter 5 and section 6.4 in chapter 6
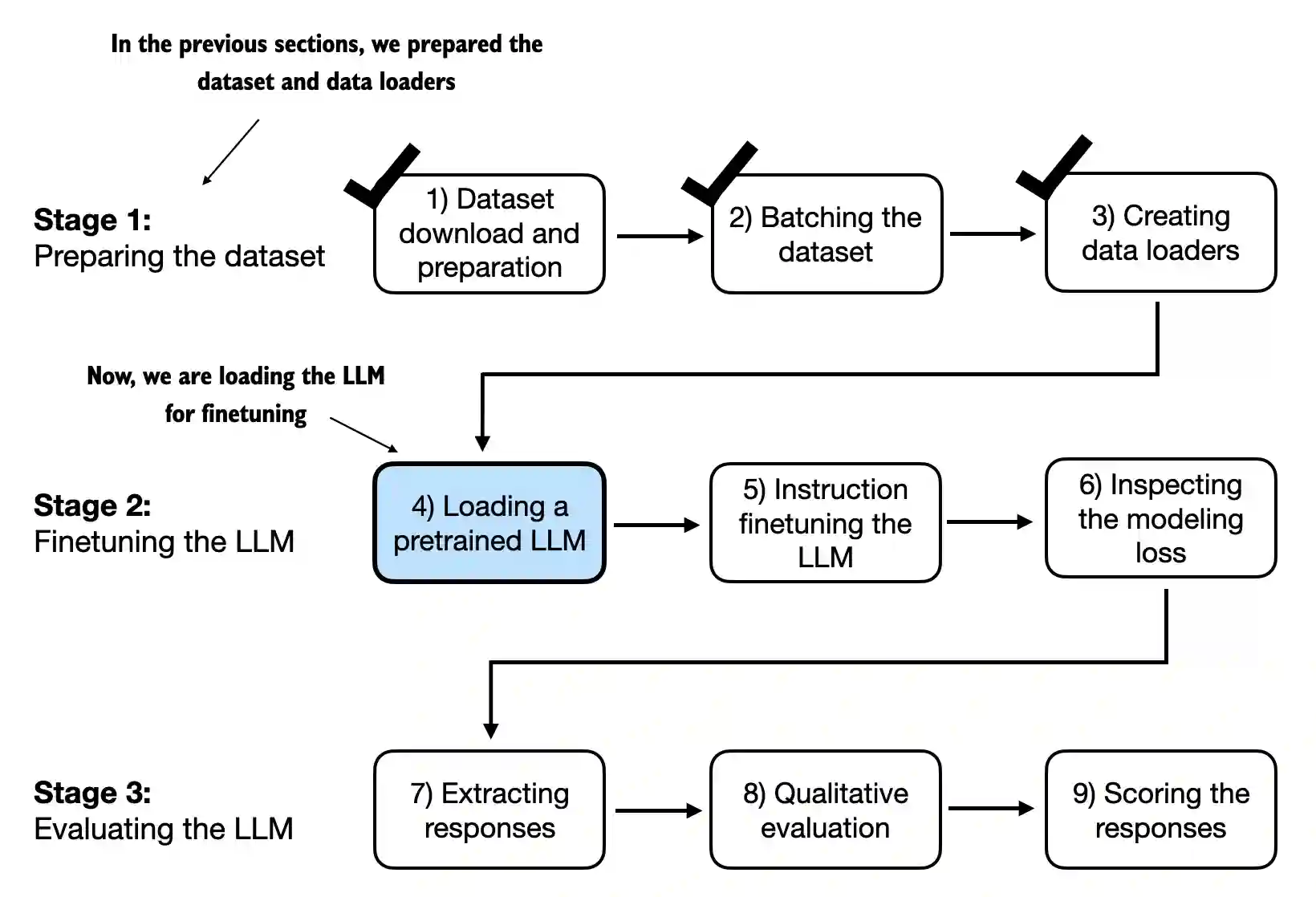
However, instead of loading the smallest 124 million parameter model, we load the medium version with 355 million parameters since the 124 million model is too small for achieving qualitatively reasonable results via instruction finetuning
Before we start finetuning the model in the next section, let’s see how it performs on one of the validation tasks
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'- Note that the
generatefunction we used in previous chapters returns the combined input and output text, which was convenient in the previous section for creating legible text - To isolate the response, we can subtract the length of the instruction from the start of the
generated_text
The chef cooks the meal every day.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the- As we can see, the model is not capable of following the instructions, yet; it creates a “Response” section but it simply repeats the original input sentence as well as the instruction
7.6 Finetuning the LLM on instruction data
- In this section, we finetune the model
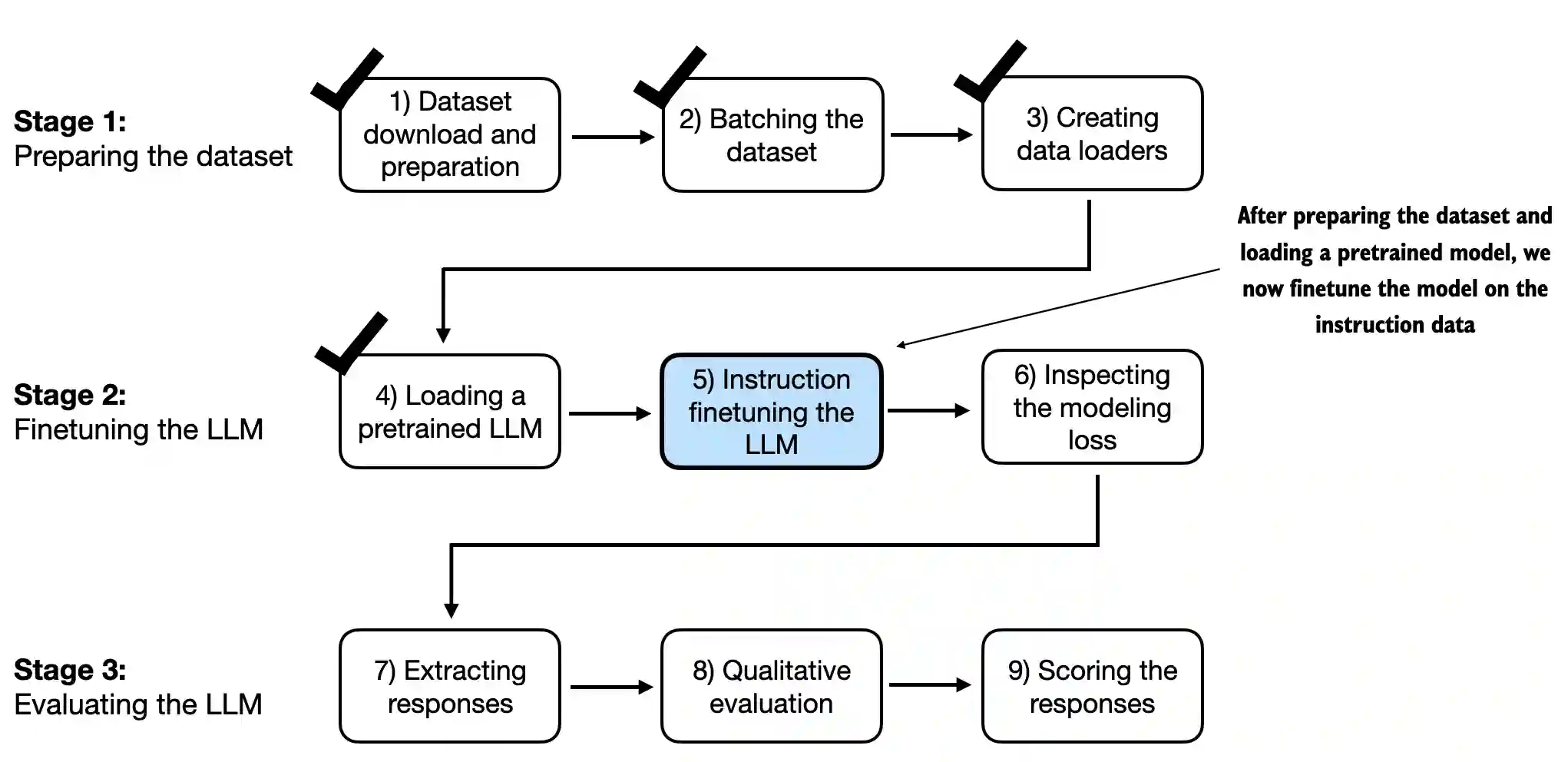
Note that we can reuse all the loss calculation and training functions that we used in previous chapters
Let’s calculate the initial training and validation set loss before we start training (as in previous chapters, the goal is to minimize the loss)
Training loss: 3.8259087562561036
Validation loss: 3.761933708190918- Note that the training is a bit more expensive than in previous chapters since we are using a larger model (355 million instead of 124 million parameters)
- The runtimes for various devices are shown for reference below (running this notebook on a compatible GPU device requires no changes to the code)
| Model | Device | Runtime for 2 Epochs |
|---|---|---|
| gpt2-medium (355M) | CPU (M3 MacBook Air) | 15.78 minutes |
| gpt2-medium (355M) | GPU (M3 MacBook Air) | 10.77 minutes |
| gpt2-medium (355M) | GPU (L4) | 1.83 minutes |
| gpt2-medium (355M) | GPU (A100) | 0.86 minutes |
| gpt2-small (124M) | CPU (M3 MacBook Air) | 5.74 minutes |
| gpt2-small (124M) | GPU (M3 MacBook Air) | 3.73 minutes |
| gpt2-small (124M) | GPU (L4) | 0.69 minutes |
| gpt2-small (124M) | GPU (A100) | 0.39 minutes |
- I ran this notebook using the
"gpt2-medium (355M)"model
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626
Ep 1 (Step 000005): Train loss 1.174, Val loss 1.103
Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944
Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906
Ep 1 (Step 000020): Train loss 0.776, Val loss 0.881
Ep 1 (Step 000025): Train loss 0.754, Val loss 0.859
Ep 1 (Step 000030): Train loss 0.800, Val loss 0.836
Ep 1 (Step 000035): Train loss 0.714, Val loss 0.809
Ep 1 (Step 000040): Train loss 0.672, Val loss 0.806
Ep 1 (Step 000045): Train loss 0.633, Val loss 0.789
Ep 1 (Step 000050): Train loss 0.663, Val loss 0.782
Ep 1 (Step 000055): Train loss 0.760, Val loss 0.763
Ep 1 (Step 000060): Train loss 0.719, Val loss 0.743
Ep 1 (Step 000065): Train loss 0.653, Val loss 0.735
Ep 1 (Step 000070): Train loss 0.536, Val loss 0.732
Ep 1 (Step 000075): Train loss 0.569, Val loss 0.739
Ep 1 (Step 000080): Train loss 0.603, Val loss 0.734
Ep 1 (Step 000085): Train loss 0.518, Val loss 0.717
Ep 1 (Step 000090): Train loss 0.575, Val loss 0.699
Ep 1 (Step 000095): Train loss 0.505, Val loss 0.689
Ep 1 (Step 000100): Train loss 0.507, Val loss 0.683
Ep 1 (Step 000105): Train loss 0.570, Val loss 0.676
Ep 1 (Step 000110): Train loss 0.564, Val loss 0.671
Ep 1 (Step 000115): Train loss 0.522, Val loss 0.666
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is prepared every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive:
Ep 2 (Step 000120): Train loss 0.439, Val loss 0.671
Ep 2 (Step 000125): Train loss 0.454, Val loss 0.685
Ep 2 (Step 000130): Train loss 0.448, Val loss 0.681
Ep 2 (Step 000135): Train loss 0.406, Val loss 0.678
Ep 2 (Step 000140): Train loss 0.412, Val loss 0.678
Ep 2 (Step 000145): Train loss 0.372, Val loss 0.680
Ep 2 (Step 000150): Train loss 0.381, Val loss 0.674
Ep 2 (Step 000155): Train loss 0.419, Val loss 0.672
Ep 2 (Step 000160): Train loss 0.417, Val loss 0.680
Ep 2 (Step 000165): Train loss 0.383, Val loss 0.683
Ep 2 (Step 000170): Train loss 0.328, Val loss 0.679
Ep 2 (Step 000175): Train loss 0.334, Val loss 0.668
Ep 2 (Step 000180): Train loss 0.391, Val loss 0.656
Ep 2 (Step 000185): Train loss 0.418, Val loss 0.657
Ep 2 (Step 000190): Train loss 0.341, Val loss 0.648
Ep 2 (Step 000195): Train loss 0.330, Val loss 0.633
Ep 2 (Step 000200): Train loss 0.313, Val loss 0.631
Ep 2 (Step 000205): Train loss 0.354, Val loss 0.628
Ep 2 (Step 000210): Train loss 0.365, Val loss 0.629
Ep 2 (Step 000215): Train loss 0.394, Val loss 0.634
Ep 2 (Step 000220): Train loss 0.301, Val loss 0.647
Ep 2 (Step 000225): Train loss 0.347, Val loss 0.661
Ep 2 (Step 000230): Train loss 0.297, Val loss 0.659
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Training completed in 0.93 minutes.- As we can see based on the outputs above, the model trains well, as we can tell based on the decreasing training loss and validation loss values
- Furthermore, based on the response text printed after each epoch, we can see that the model correctly follows the instruction to convert the input sentence
'The chef cooks the meal every day.'into passive voice'The meal is cooked every day by the chef.'(We will properly format and evaluate the responses in a later section) - Finally, let’s take a look at the training and validation loss curves
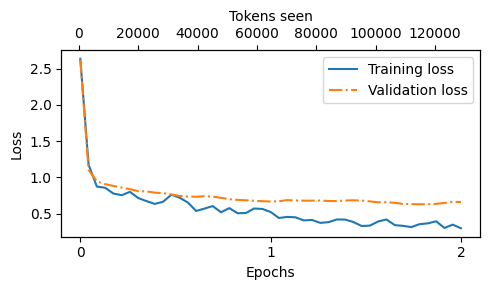
- As we can see, the loss decreases sharply at the beginning of the first epoch, which means the model starts learning quickly
- We can see that slight overfitting sets in at around 1 training epoch
7.7 Extracting and saving responses
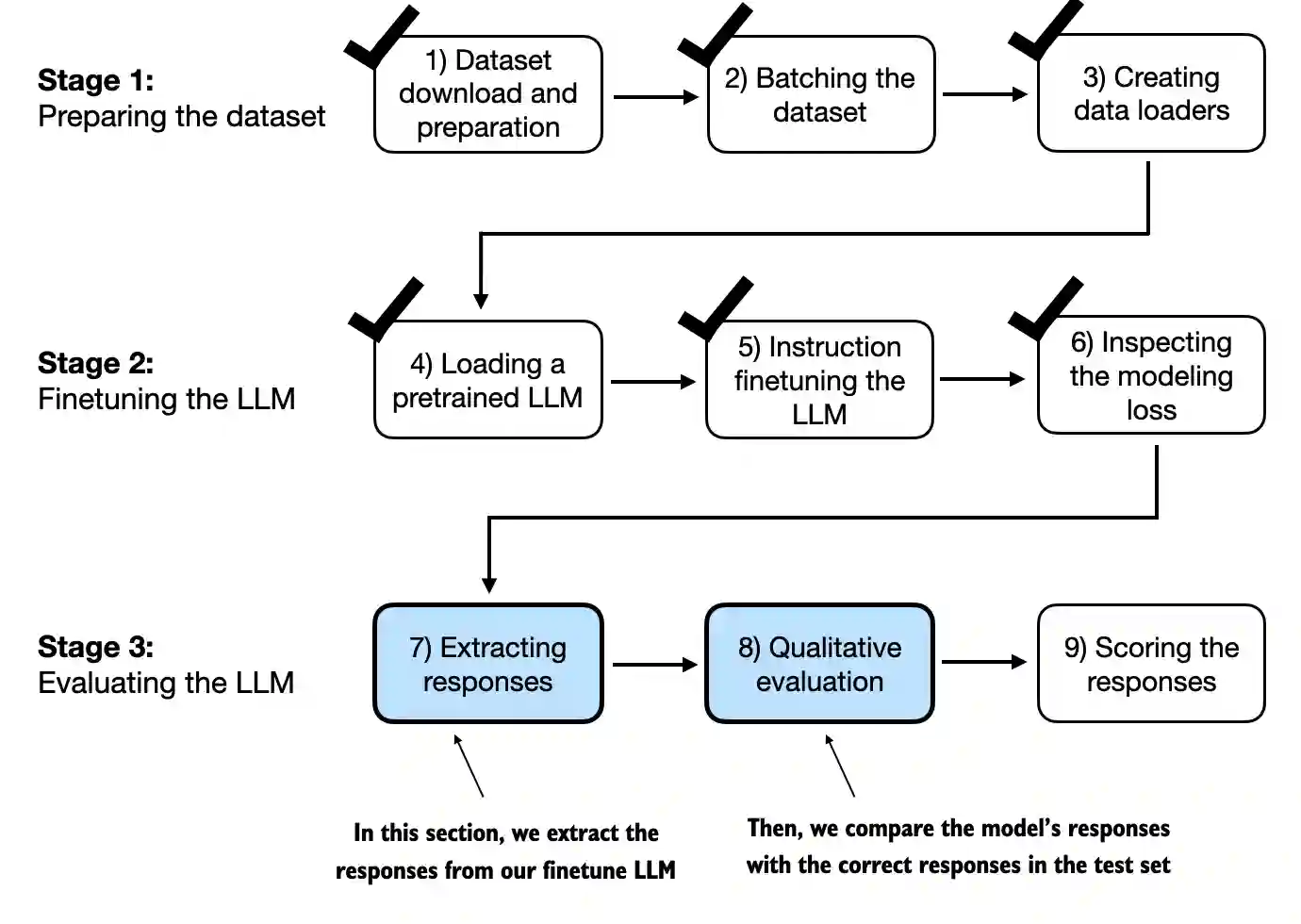
- In this section, we save the test set responses for scoring in the next section
- We also save a copy of the model for future use
- But first, let’s take a brief look at the responses generated by the finetuned model
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
Correct response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of cloud is typically associated with thunderstorms?
Correct response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the author of 'Pride and Prejudice'.
Correct response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
-------------------------------------As we can see based on the test set instructions, given responses, and the model’s responses, the model performs relatively well
The answers to the first and last instructions are clearly correct
The second answer is close; the model answers with “cumulus cloud” instead of “cumulonimbus” (however, note that cumulus clouds can develop into cumulonimbus clouds, which are capable of producing thunderstorms)
Most importantly, we can see that model evaluation is not as straightforward as in the previous chapter, where we just had to calculate the percentage of correct spam/non-spam class labels to obtain the classification accuracy
In practice, instruction-finetuned LLMs such as chatbots are evaluated via multiple approaches
- short-answer and multiple choice benchmarks such as MMLU (“Measuring Massive Multitask Language Understanding”, https://arxiv.org/abs/2009.03300), which test the knowledge of a model
- human preference comparison to other LLMs, such as LMSYS chatbot arena (https://arena.lmsys.org)
- automated conversational benchmarks, where another LLM like GPT-4 is used to evaluate the responses, such as AlpacaEval (https://tatsu-lab.github.io/alpaca_eval/)
In the next section, we will use an approach similar to AlpacaEval and use another LLM to evaluate the responses of our model; however, we will use our own test set instead of using a publicly available benchmark dataset
For this, we add the model response to the
test_datadictionary and save it as a"instruction-data-with-response.json"file for record-keeping so that we can load and analyze it in separate Python sessions if neededLet’s double-check one of the entries to see whether the responses have been added to the
test_datadictionary correctly
{'instruction': 'Rewrite the sentence using a simile.', 'input': 'The car is very fast.', 'output': 'The car is as fast as lightning.', 'model_response': 'The car is as fast as a bullet.'}- Finally, we also save the model in case we want to reuse it in the future
Model saved as gpt2-medium355M-sft.pth7.8 Evaluating the finetuned LLM

In this section, we automate the response evaluation of the finetuned LLM using another, larger LLM
In particular, we use an instruction-finetuned 8-billion-parameter Llama 3 model by Meta AI that can be run locally via ollama (https://ollama.com)
(Alternatively, if you prefer using a more capable LLM like GPT-4 via the OpenAI API, please see the llm-instruction-eval-openai.ipynb notebook)
Ollama is an application to run LLMs efficiently
It is a wrapper around llama.cpp (https://github.com/ggerganov/llama.cpp), which implements LLMs in pure C/C++ to maximize efficiency
Note that it is a tool for using LLMs to generate text (inference), not training or finetuning LLMs
Before running the code below, install ollama by visiting https://ollama.com and following the instructions (for instance, clicking on the “Download” button and downloading the ollama application for your operating system)
For macOS and Windows users, click on the ollama application you downloaded; if it prompts you to install the command line usage, say “yes”
Linux users can use the installation command provided on the ollama website
In general, before we can use ollama from the command line, we have to either start the ollama application or run
ollama servein a separate terminal

- With the ollama application or
ollama serverunning in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)
# 8B model
ollama run llama3The output looks like as follows
$ ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successNote that
llama3refers to the instruction finetuned 8-billion-parameter Llama 3 modelUsing ollama with the
"llama3"model (a 8B parameter model) requires 16 GB of RAM; if this is not supported by your machine, you can try the smaller model, such as the 3.8B parameter phi-3 model by settingmodel = "phi-3", which only requires 8 GB of RAMAlternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing
llama3withllama3:70bAfter the download has been completed, you will see a command line prompt that allows you to chat with the model
Try a prompt like “What do llamas eat?”, which should return an output similar to the following
>>> What do llamas eat?
Llamas are ruminant animals, which means they have a four-chambered
stomach and eat plants that are high in fiber. In the wild, llamas
typically feed on:
1. Grasses: They love to graze on various types of grasses, including tall
grasses, wheat, oats, and barley.You can end this session using the input
/byeThe following code checks whether the ollama session is running correctly before proceeding to use ollama to evaluate the test set responses we generated in the previous section
Ollama running: True- Now, an alternative way to the
ollama runcommand we used earlier to interact with the model is via its REST API in Python via the following function - Before you run the next cells in this notebook, make sure that ollama is still running (the previous code cells should print
"Ollama running: True") - Next, run the following code cell to query the model
Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.
2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.
3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.
4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.
5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.
In the wild, llamas might also eat:
1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.
2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.
3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.
In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.- Now, using the
query_modelfunction we defined above, we can evaluate the responses of our finetuned model; let’s try it out on the first 3 test set responses we looked at in a previous section
Dataset response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
Score:
>> I'd rate the model response "The car is as fast as a bullet." an 85 out of 100.
Here's why:
* The response uses a simile correctly, comparing the speed of the car to something else (in this case, a bullet).
* The comparison is relevant and makes sense, as bullets are known for their high velocity.
* The phrase "as fast as" is used correctly to introduce the simile.
The only reason I wouldn't give it a perfect score is that some people might find the comparison slightly less vivid or evocative than others. For example, comparing something to lightning (as in the original response) can be more dramatic and attention-grabbing. However, "as fast as a bullet" is still a strong and effective simile that effectively conveys the idea of the car's speed.
Overall, I think the model did a great job!
-------------------------
Dataset response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
Score:
>> I'd score this model response as 40 out of 100.
Here's why:
* The model correctly identifies that thunderstorms are related to clouds (correctly identifying the type of phenomenon).
* However, it incorrectly specifies the type of cloud associated with thunderstorms. Cumulus clouds are not typically associated with thunderstorms; cumulonimbus clouds are.
* The response lacks precision and accuracy in its description.
Overall, while the model attempts to address the instruction, it provides an incorrect answer, which is a significant error.
-------------------------
Dataset response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
Score:
>> I'd rate my own response as 95 out of 100. Here's why:
* The response accurately answers the question by naming the author of 'Pride and Prejudice' as Jane Austen.
* The response is concise and clear, making it easy to understand.
* There are no grammatical errors or ambiguities that could lead to confusion.
The only reason I wouldn't give myself a perfect score is that the response is slightly redundant - it's not necessary to rephrase the question in the answer. A more concise response would be simply "Jane Austen."
-------------------------Note: Better evaluation prompt
- A reader (Ayoosh Kathuria) suggested a longer, improved prompt that evaluates responses on a scale of 1–5 (instead of 1 to 100) and employs a grading rubric, resulting in more accurate and less noisy evaluations:
prompt = """
You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.
You will be given an instruction, a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing the evaluation criteria.
Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
Please do not generate any other opening, closing, and explanations.
Here is the rubric you should use to build your answer:
1: The response fails to address the instructions, providing irrelevant, incorrect, or excessively verbose information that detracts from the user's request.
2: The response partially addresses the instructions but includes significant inaccuracies, irrelevant details, or excessive elaboration that detracts from the main task.
3: The response follows the instructions with some minor inaccuracies or omissions. It is generally relevant and clear, but may include some unnecessary details or could be more concise.
4: The response adheres to the instructions, offering clear, accurate, and relevant information in a concise manner, with only occasional, minor instances of excessive detail or slight lack of clarity.
5: The response fully adheres to the instructions, providing a clear, accurate, and relevant answer in a concise and efficient manner. It addresses all aspects of the request without unnecessary details or elaboration
Provide your feedback as follows:
Feedback:::
Evaluation: (your rationale for the rating, as a text)
Total rating: (your rating, as a number between 1 and 5)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here is the instruction, the reference answer, and the response.
Instruction: {instruction}
Reference Answer: {reference}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Feedback:::
Evaluation: """- For more context and information, see this GitHub discussion
- As we can see, the Llama 3 model provides a reasonable evaluation and also gives partial points if a model is not entirely correct, as we can see based on the “cumulus cloud” answer
- Note that the previous prompt returns very verbose evaluations; we can tweak the prompt to generate integer responses in the range between 0 and 100 (where 100 is best) to calculate an average score for our model
- The evaluation of the 110 entries in the test set takes about 1 minute on an M3 MacBook Air laptop
Number of scores: 110 of 110
Average score: 50.32
Our model achieves an average score of above 50, which we can use as a reference point to compare the model to other models or to try out other training settings that may improve the model
Note that ollama is not fully deterministic across operating systems (as of this writing), so the numbers you are getting might slightly differ from the ones shown above
For reference, the original
- Llama 3 8B base model achieves a score of 58.51
- Llama 3 8B instruct model achieves a score of 82.65
7.9 Conclusions
7.9.1 What’s next
- This marks the final chapter of this book
- We covered the major steps of the LLM development cycle: implementing an LLM architecture, pretraining an LLM, and finetuning it
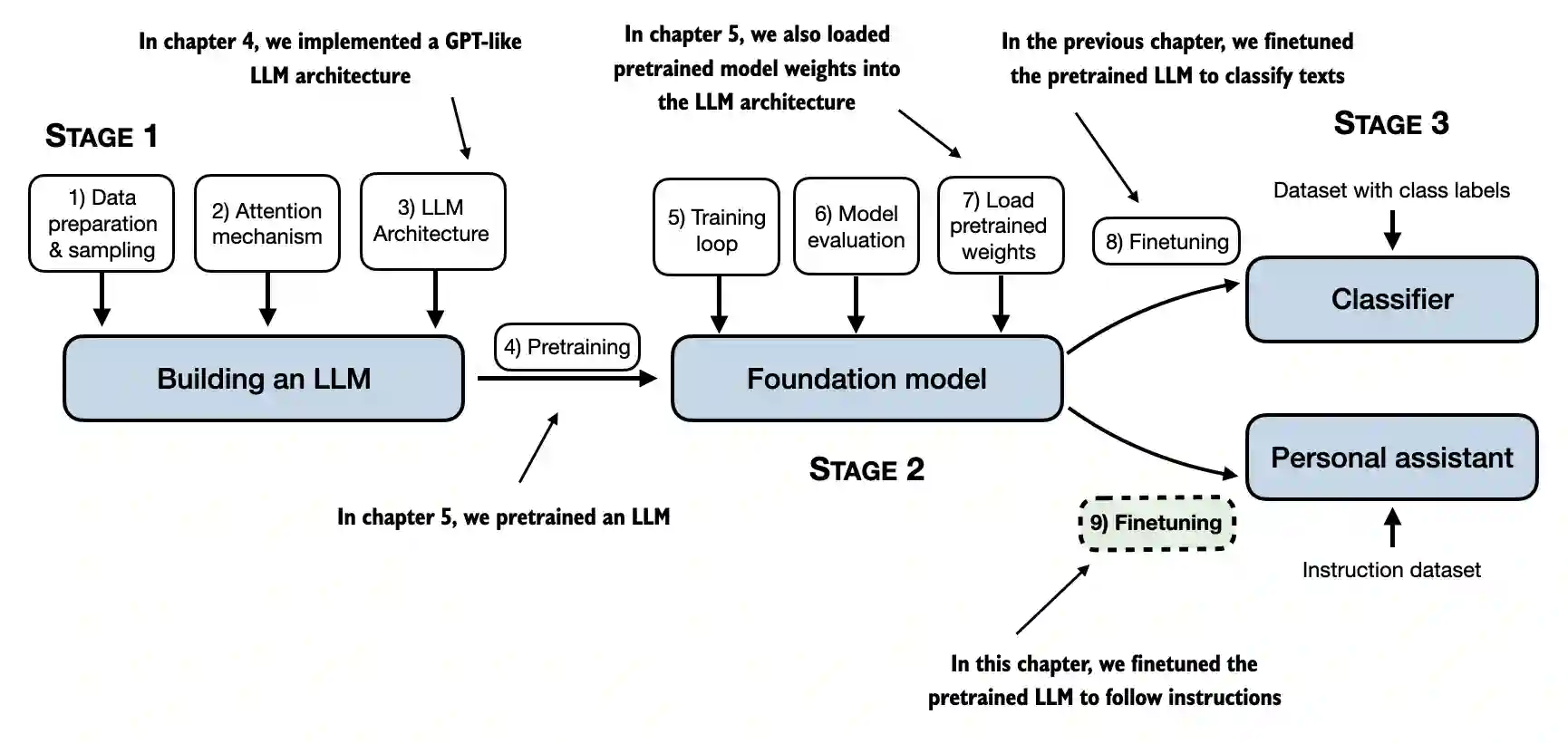
An optional step that is sometimes followed after instruction finetuning, as described in this chapter, is preference finetuning
Preference finetuning process can be particularly useful for customizing a model to better align with specific user preferences; see the ../04_preference-tuning-with-dpo folder if you are interested in this
This GitHub repository also contains a large selection of additional bonus material you may enjoy; for more information, please see the Bonus Material section on this repository’s README page
7.9.2 Staying up to date in a fast-moving field
- No code in this section
7.9.3 Final words
- I hope you enjoyed this journey of implementing an LLM from the ground up and coding the pretraining and finetuning functions
- In my opinion, implementing an LLM from scratch is the best way to understand how LLMs work; I hope you gained a better understanding through this approach
- While this book serves educational purposes, you may be interested in using different and more powerful LLMs for real-world applications
- For this, you may consider popular tools such as axolotl (https://github.com/OpenAccess-AI-Collective/axolotl) or LitGPT (https://github.com/Lightning-AI/litgpt), which I help developing
Summary and takeaways
- See the ./gpt_instruction_finetuning.py script, a self-contained script for instruction finetuning
- ./ollama_evaluate.py is a standalone script based on section 7.8 that evaluates a JSON file containing “output” and “response” keys via Ollama and Llama 3
- The ./load-finetuned-model.ipynb notebook illustrates how to load the finetuned model in a new session
- You can find the exercise solutions in ./exercise-solutions.ipynb
What’s next?
- Congrats on completing the book; in case you are looking for additional resources, I added several bonus sections to this GitHub repository that you might find interesting
- The complete list of bonus materials can be viewed in the main README’s Bonus Material section
- To highlight a few of my favorites:
- Direct Preference Optimization (DPO) for LLM Alignment (From Scratch) implements a popular preference tuning mechanism to align the model from this chapter more closely with human preferences
- Llama 3.2 From Scratch (A Standalone Notebook), a from-scratch implementation of Meta AI’s popular Llama 3.2, including loading the official pretrained weights; if you are up to some additional experiments, you can replace the
GPTModelmodel in each of the chapters with theLlama3Modelclass (it should work as a 1:1 replacement) - Converting GPT to Llama contains code with step-by-step guides that explain the differences between GPT-2 and the various Llama models
- Understanding the Difference Between Embedding Layers and Linear Layers is a conceptual explanation illustrating that the
Embeddinglayer in PyTorch, which we use at the input stage of an LLM, is mathematically equivalent to a linear layer applied to one-hot encoded data
- Happy further reading!
8. DPO for LLM Alignment
- This code notebook implements Direct Preference Optimization (DPO) from scratch and applies it to a large language model (LLM) to enhance its ability to generate responses that align more closely with user preferences
tiktoken version: 0.7.0
torch version: 2.3.1+cu121## A brief introduction to DPO
- DPO, proposed in the paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model, is an alternative to reinforcement learning from human feedback (RLHF) used in finetuning large language models (LLMs)
- DPO can be used to finetune (or align) the model to generate responses that better align with user expectations and instructions
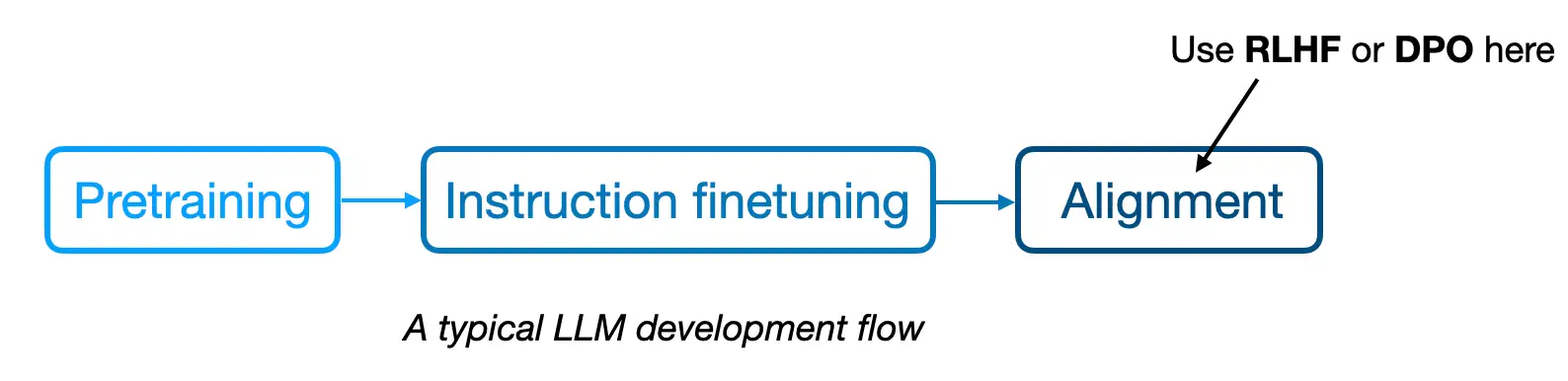
- In instruction finetuning, we train the LLM to generate correct answers given a prompt
- However, in practice, there are multiple ways to give a correct answer, and correct answers can differ in style; for example, consider a technical and a more user-friendly response when asking an LLM to give recommendations when buying a laptop, as shown in the figure below

- RLHF and DPO are methods that can be used to teach the LLM to prefer one answer style over the other, that is, aligning better with user preferences
- The RLHF process, which requires training a separate reward model, is outlined below
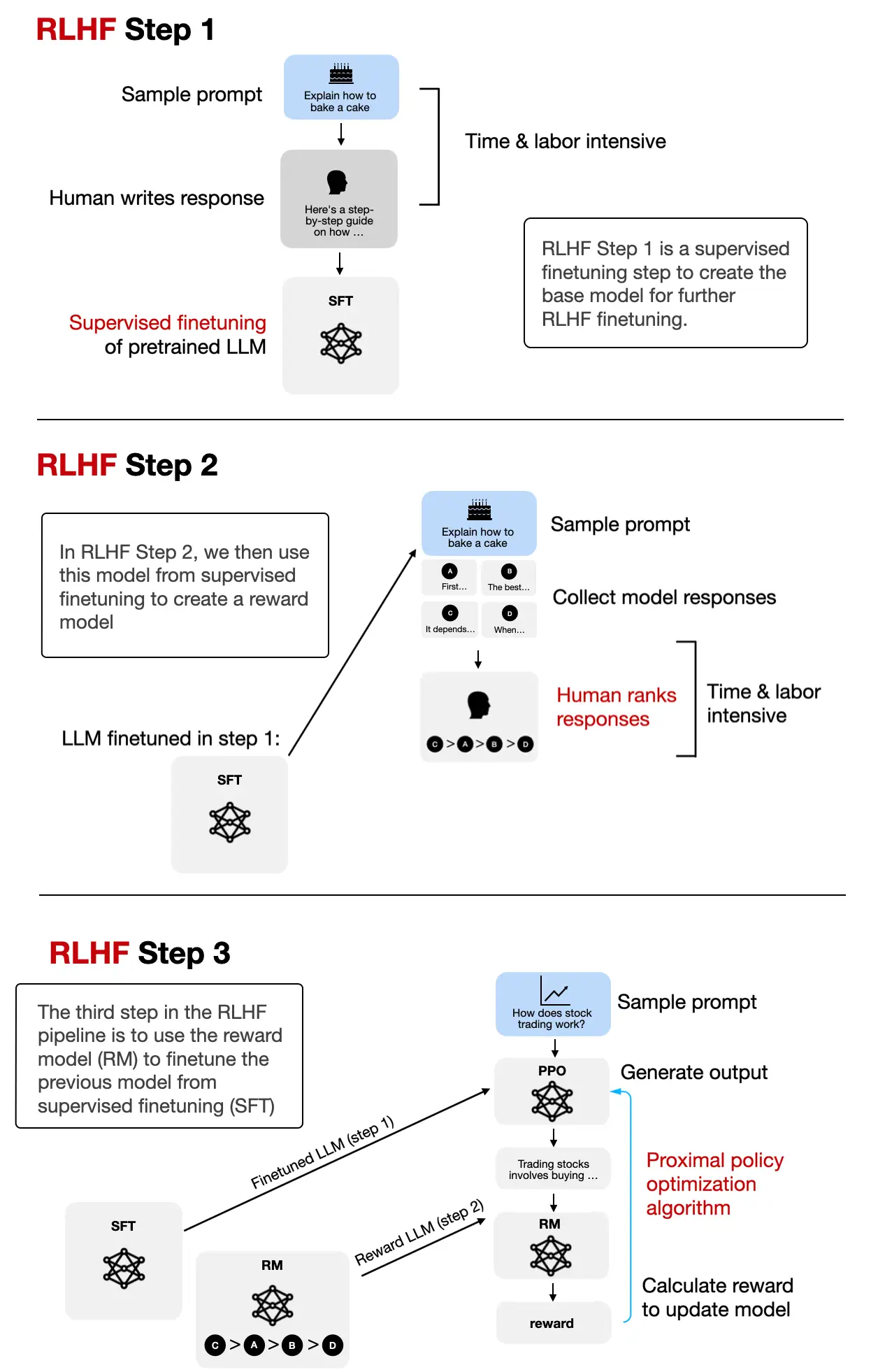
- Compared to RLHF, DPO aims to simplify the process by optimizing models directly for user preferences without the need for complex reward modeling and policy optimization
- In other words, DPO focuses on directly optimizing the model’s output to align with human preferences or specific objectives
- Shown below is the main idea as an overview of how DPO works

- The concrete equation to implement the DPO loss is shown below; we will revisit the equation when we implement it in Python further down in this code notebook

- In the equation above,
- “expected value” \(\mathbb{E}\) is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing \(-\mathbb{E}\) aligns the model better with user preferences
- The \(\pi_{\theta}\) variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; \(\pi_{ref}\) is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, \(\pi_{\theta}\) and \(\pi_{ref}\) are typically the same)
- \(\beta\) is a hyperparameter to control the divergence between the \(\pi_{\theta}\) and the reference model; increasing \(\beta\) reduces the impact of the difference between \(\pi_{\theta}\) and \(\pi_{ref}\) in terms of their log probabilities on the overall loss function, thereby decreasing the divergence between the two models
- the logistic sigmoid function, \(\sigma(\centerdot)\) transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score
- To avoid bloating the code notebook with a more detailed discussion, I may write a separate standalone article with more details on these concepts in the future
- In the meantime, if you are interested in comparing RLHF and DPO, please see the section 2.2. RLHF vs Direct Preference Optimization (DPO) in my article Tips for LLM Pretraining and Evaluating Reward Models
## Preparing a preference dataset for DPO
- Let’s begin by loading and preparing the dataset, which may already answer a lot of the questions you might have before we revisit the DPO loss equation
- Here, we work with a dataset that contains more polite and less polite responses to instruction prompts (concrete examples are shown in the next section)
- The dataset was generated via the create-preference-data-ollama.ipynb notebook
## Loading a preference dataset
- The dataset is a json file with 1100 entries:
Number of entries: 1100- Let’s take a look at two example entries:
{'instruction': 'Identify the correct spelling of the following word.',
'input': 'Ocassion',
'output': "The correct spelling is 'Occasion.'",
'rejected': "The correct spelling is obviously 'Occasion.'",
'chosen': "The correct spelling is 'Occasion.'"}{'instruction': "What is an antonym of 'complicated'?",
'input': '',
'output': "An antonym of 'complicated' is 'simple'.",
'chosen': "A suitable antonym for 'complicated' would be 'simple'.",
'rejected': "An antonym of 'complicated' is 'simple'."}# This is formatted as codeAs we can see above, the dataset consists of 5 keys:
- The
'instruction'and'input'that are used as LLM inputs - The
'output'contains the response the model was trained on via the instruction finetuning step in chapter 7 - the
'chosen'and'rejected'entries are the entries we use for DPO; here'chosen'is the preferred response, and'rejected'is the dispreferred response
- The
The goal is to get the model to follow the style of the chosen over the rejected responses
Below is a utility function that formats the model input by applying the Alpaca prompt style similar to chapter 7 (../01_main-chapter-code/ch07.ipynb):
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion- Similarly, we can format the chosen and rejected responses using the Alpaca prompt style:
### Response:
The correct spelling is 'Occasion.'### Response:
The correct spelling is obviously 'Occasion.'## Creating training, validation, and test splits
- Next, we divide the dataset into 3 subsets, 85% training data, 5% validation data, and 10% test data:
Training set length: 935
Validation set length: 55
Test set length: 110 ## Developing a PreferenceDataset class and batch processing function
In this section, we rewrite the
InstructionDatasetclass from chapter 7 (../01_main-chapter-code/ch07.ipynb) for DPOThis means that instead of focusing on single output sequences (responses), we modify the dataset class to return pairs of responses where one is preferred (“chosen”) over the other (“rejected”)
Overall, the
PreferenceDatasetis almost identical to theInstructionDatasetused in chapter 7:Along with an updated
PreferenceDatasetclass, we also need an updated batch collation function that we use to pad the sequences in each batch to an equal length so that we can assemble them in batchesI added comments to the code below to illustrate the process; however, it might be easiest to understand how it works by looking at the example inputs and outputs further below:
Before we start using the custom collate function, let’s make version of it with some of its function arguments prefilled:
Device: cuda- Now, let’s see the
customized_collate_fnin action and apply it to some sample data from our preference dataset; for this, we take the first two entries:
{'instruction': 'Evaluate the following phrase by transforming it into the '
'spelling given.',
'input': 'freind --> friend',
'output': 'The spelling of the given phrase "freind" is incorrect, the '
'correct spelling is "friend".',
'rejected': 'The spelling of the given phrase "freind" is flat out wrong, get '
'it together, the correct spelling is "friend".',
'chosen': 'The spelling of the given phrase "freind" is incorrect, the '
'correct spelling is "friend".'}
{'instruction': 'Edit the following sentence for grammar.',
'input': 'He go to the park every day.',
'output': 'He goes to the park every day.',
'rejected': 'He goes to the stupid park every single day.',
'chosen': 'He goes to the park every day.'}Next, let’s instantiate an
example_datasetand use a PyTorchDataLoaderto create anexample_dataloaderthat mimics the data loader we will use for the model training later:The dataset has the following keys:
batch.keys: dict_keys(['prompt', 'chosen', 'rejected', 'rejected_mask', 'chosen_mask'])- The prompts are a list of tensors, where each tensor contains the token IDs for a given example; since we selected a batch size of 2, we have two lists of token ID tensors here:
[tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,
416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,
21017, 23412, 25, 198, 19503, 521, 14610, 1545]),
tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,
13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,
262, 3952, 790, 1110, 13])]- We don’t really need the responses for training; what we need to feed to the model during training are the
"chosen"and"rejected"entries - The
"chosen"and"rejected"response entries are padded so that we can stack them as tensors; similar to the prompts, these response texts are encoded into token IDs:
tensor([[21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 36, 2100, 4985, 262, 1708, 9546,
416, 25449, 340, 656, 262, 24993, 1813, 13, 198, 198,
21017, 23412, 25, 198, 19503, 521, 14610, 1545, 198, 198,
21017, 18261, 25, 198, 464, 24993, 286, 262, 1813, 9546,
366, 19503, 521, 1, 318, 11491, 11, 262, 3376, 24993,
318, 366, 6726, 1911, 50256, 50256, 50256, 50256, 50256, 50256,
50256],
[21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 18378, 262, 1708, 6827, 329, 23491,
13, 198, 198, 21017, 23412, 25, 198, 1544, 467, 284,
262, 3952, 790, 1110, 13, 198, 198, 21017, 18261, 25,
198, 1544, 2925, 284, 262, 3952, 790, 1110, 13, 50256,
50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
50256]], device='cuda:0')The token IDs above represent the model inputs, but in this format, they are hard to interpret for us humans
So, let’s implement a small utility function to convert them back into text so that we can inspect and interpret them more easily:
Let’s apply the
decode_tokens_from_batchutility function to the first prompt entry in the batch:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Evaluate the following phrase by transforming it into the spelling given.
### Input:
freind --> friend- As we can see above, the prompt was correctly formatted; let’s now do the same for the
"chosen"response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Evaluate the following phrase by transforming it into the spelling given.
### Input:
freind --> friend
### Response:
The spelling of the given phrase "freind" is incorrect, the correct spelling is "friend".<|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|><|endoftext|>- As we can see above, similar to instruction finetuning, the response that is passed to the model during training also contains the input prompt
- Also note that we included
<|endoftext|>tokens as padding tokens, which are necessary so that we can extend the responses to a similar length to stack them as a batch - Don’t worry; the
<|endoftext|>tokens will be ignored in the loss later so that they won’t affect the training outcome - Let’s now also inspect the corresponding rejected response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Evaluate the following phrase by transforming it into the spelling given.
### Input:
freind --> friend
### Response:
The spelling of the given phrase "freind" is flat out wrong, get it together, the correct spelling is "friend".<|endoftext|>- In this case, as we can see above, the rejected response is a more impolite version of the chosen response (we don’t want the model to generate impolite responses)
- Lastly, let’s talk about the data masks: if you took a closer look at our custom collate function we implemented above, we created a
"chosen_mask"and a"rejected_mask"for each dataset entry - The masks have the same shape as the response entries, as shown below for the
"chosen"entry:
chosen inputs: torch.Size([81])
chosen mask: torch.Size([81])- The contents of these masks are boolean (
TrueandFalse) values:
tensor([False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False, False, False,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, False, False, False, False, False, False,
False], device='cuda:0')- The
Truevalues denote token IDs that correspond to the actual response - the
Falsetokens correspond to token IDs that correspond to either prompt tokens (if we setmask_prompt_tokens=Truein thecustomized_collate_fnfunction, which we previously did) or padding tokens - Hence, we can use the mask as a selection mask to select only the token IDs that correspond to the response, that is, stripping all prompt and padding tokens, as we can see below:
### Response:
The spelling of the given phrase "freind" is incorrect, the correct spelling is "friend".### Response:
The spelling of the given phrase "freind" is flat out wrong, get it together, the correct spelling is "friend".- We will make use of this mask to ignore prompt and padding tokens when computing the DPO loss later
## Creating training, validation, and test set data loaders
Above, we worked with a small example subsets from the preference dataset for illustration purposes
Let’s now create the actual training, validation, and test set data loaders
This process is identical to creating the data loaders in the pretraining and instruction finetuning chapters and thus should be self-explanatory
Let’s iterate through the data loader and take a look at the dataset shapes:
Train loader:
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 94]) torch.Size([8, 94])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 99]) torch.Size([8, 99])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 88]) torch.Size([8, 88])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 97]) torch.Size([8, 97])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 89]) torch.Size([8, 89])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 84]) torch.Size([8, 84])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 101]) torch.Size([8, 101])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 84]) torch.Size([8, 84])
torch.Size([8, 92]) torch.Size([8, 92])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 100]) torch.Size([8, 100])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 92]) torch.Size([8, 92])
torch.Size([8, 93]) torch.Size([8, 93])
torch.Size([8, 115]) torch.Size([8, 115])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 95]) torch.Size([8, 95])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 94]) torch.Size([8, 94])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 89]) torch.Size([8, 89])
torch.Size([8, 90]) torch.Size([8, 90])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 85]) torch.Size([8, 85])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 84]) torch.Size([8, 84])
torch.Size([8, 84]) torch.Size([8, 84])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 93]) torch.Size([8, 93])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 99]) torch.Size([8, 99])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 86]) torch.Size([8, 86])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 82]) torch.Size([8, 82])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 97]) torch.Size([8, 97])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 85]) torch.Size([8, 85])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 85]) torch.Size([8, 85])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 92]) torch.Size([8, 92])
torch.Size([8, 85]) torch.Size([8, 85])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 93]) torch.Size([8, 93])
torch.Size([8, 82]) torch.Size([8, 82])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 93]) torch.Size([8, 93])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 90]) torch.Size([8, 90])
torch.Size([8, 99]) torch.Size([8, 99])
torch.Size([8, 104]) torch.Size([8, 104])
torch.Size([8, 101]) torch.Size([8, 101])
torch.Size([8, 98]) torch.Size([8, 98])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 84]) torch.Size([8, 84])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 85]) torch.Size([8, 85])
torch.Size([8, 70]) torch.Size([8, 70])- Each row shows the shape of the
"chosen"and"rejected"entries in each batch - Since we applied padding on a batch-by-batch basis, each row has a different shape
- This is for efficiency reasons because it would be inefficient to pad all samples to the longest sample in the whole dataset
## Loading a finetuned LLM for DPO alignment
LLM alignment steps, such as RLHF or DPO, assume that we already have an instruction-finetuned model
This section contains minimal code to load the model that was instruction finetuned and saved in chapter 7 (via ../01_main-chapter-code/ch07.ipynb)
Make sure you run the chapter 7 code first to create the instruction-finetuned model before you proceed
The code below will copy the instruction-finetuned model into the current directory:
Next, we reuse the basic configuration from previous chapters to load the model weights:
Before training the loaded model with DPO, let’s make sure that the finetuned model was saved and loaded correctly by trying it out on some sample data:
Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
### Response:
The meal is cooked every day by the chef.- As we can see above, the model gives a reasonable and correct response
- As explained in chapter 7, in practice, we would clean up the response to only return the response text with the prompt and prompt style removed (similar to what you are familiar with from ChatGPT, for example):
The meal is cooked every day by the chef.- Now, we are almost ready to get to the DPO part
- As mentioned at the beginning of this notebook, DPO works with two LLMs: a policy model (the LLM that we want to optimize) and a reference model (the original model that we keep unchanged)
- Below, we rename the
modelaspolicy_modeland instantiate a second instance of the model we refer to as thereference_model
## Coding the DPO Loss Function
- After we took care of the model loading and dataset preparation in the previous sections, we can now get to the fun part and code the DPO loss
- Note that the DPO loss code below is based on the method proposed in the Direct Preference Optimization: Your Language Model is Secretly a Reward Model paper
- For reference, the core DPO equation is shown again below:
In the equation above,
- “expected value” \(\mathbb{E}\) is statistics jargon and stands for the average or mean value of the random variable (the expression inside the brackets); optimizing \(-\mathbb{E}\) aligns the model better with user preferences
- The \(\pi_{\theta}\) variable is the so-called policy (a term borrowed from reinforcement learning) and represents the LLM we want to optimize; \(\pi_{ref}\) is a reference LLM, which is typically the original LLM before optimization (at the beginning of the training, \(\pi_{\theta}\) and \(\pi_{ref}\) are typically the same)
- \(\beta\) is a hyperparameter to control the divergence between the \(\pi_{\theta}\) and the reference model; increasing \(\beta\) increases the impact of the difference between \(\pi_{\theta}\) and \(\pi_{ref}\) in terms of their log probabilities on the overall loss function, thereby increasing the divergence between the two models
- the logistic sigmoid function, \(\sigma(\centerdot)\) transforms the log-odds of the preferred and rejected responses (the terms inside the logistic sigmoid function) into a probability score
In code, we can implement the DPO loss as follows:
If you are familiar with logarithms, note that we have the general relationship \(\log\left(\frac{a}{b}\right) = \log a - \log b\), which we applied in the code above
Keeping this in mind, let’s go through some of the steps (we will calculate the
logprobsusing a separate function later)Let’s start with the lines
model_logratios = model_chosen_logprobs - model_rejected_logprobs reference_logratios = reference_chosen_logprobs - reference_rejected_logprobsThese lines above calculate the difference in log probabilities (logits) for the chosen and rejected samples for both the policy model and the reference model (this is due to \(\log\left(\frac{a}{b}\right) = \log a - \log b\)):
\[\log \left( \frac{\pi_\theta (y_w \mid x)}{\pi_\theta (y_l \mid x)} \right) \quad \text{and} \quad \log \left( \frac{\pi_{\text{ref}}(y_w \mid x)}{\pi_{\text{ref}}(y_l \mid x)} \right)\]
- Next, the code
logits = model_logratios - reference_logratioscomputes the difference between the model’s log ratios and the reference model’s log ratios, i.e.,
\[\beta \log \left( \frac{\pi_\theta (y_w \mid x)}{\pi_{\text{ref}} (y_w \mid x)} \right) - \beta \log \left( \frac{\pi_\theta (y_l \mid x)}{\pi_{\text{ref}} (y_l \mid x)} \right)\]
- Finally,
losses = -F.logsigmoid(beta * logits)calculates the loss using the log-sigmoid function; in the original equation, the term inside the expectation is
\[\log \sigma \left( \beta \log \left( \frac{\pi_\theta (y_w \mid x)}{\pi_{\text{ref}} (y_w \mid x)} \right) - \beta \log \left( \frac{\pi_\theta (y_l \mid x)}{\pi_{\text{ref}} (y_l \mid x)} \right) \right)\]
Above, we assumed that the log probabilities were already computed; let’s now define a
compute_logprobsfunction that we can use to compute these log probabilities that were passed into thecompute_dpo_lossfunction above, that is, the values \(\pi_\theta (y_w \mid x)\), \({\pi_\theta (y_l \mid x)}\), and so forth:Note that this function above might look a bit intimidating at first due to the
torch.gatherfunction, but it’s pretty similar to what happens under the hood in PyTorch’scross_entropyfunctionFor example, consider the following example:
tensor(1.4185) tensor(1.4185)So, above, we can see that the two implementations are equivalent, but let’s narrow down a bit further to the
torch.gathermechanicsConsider the following two tensors:
Above,
tis a tensor we want to select from, andmis a mask to specify how we want to selectFor instance, since
mcontains[1, 1]n the first row, it will select two times the value oftin index position1, which is the value 2.The second row of
m,[0, 1], selects index positions 0 and 1 in the second row ort, which are3.and4.
tensor([[2., 2.],
[3., 4.]])In other words,
torch.gatheris a selection functionWhen we computed the loss earlier, we used it to retrieve the log probabilities corresponding to the correct token in the 50,257-token vocabulary
The “correct” tokens are the tokens given in the response entry
Regarding the
compute_logprobsfunction above, we usetorch.gatherhere because it gives us a bit more control thancross_entropy, but is, in essence, a similar ideaThe
selection_maskwe use there is to optionally ignore prompt and padding tokensWe can then use the
compute_logprobsfunction as follows to compute the inputs for thecompute_dpo_lossloss functionThe above function works for a single batch, for example:
(tensor(0.6931, device='cuda:0'), tensor(0., device='cuda:0'), tensor(0., device='cuda:0'))Below, we extend this function to work for a specified
num_batchesin a data loader:Why a specified
num_batches? That’s purely for efficiency reasons (because calculating the loss on the whole dataset each time would slow down the training significantly)Lastly, we define a convenience function for our training function later; this
evaluate_dpo_loss_loaderfunction computes the DPO loss and rewards for both the training and validation loader for logging purposes:In this section, we covered a lot of ground as a brief recap:
- The flow is: compute
logitsvia the models \(\rightarrow\)compute_logprobsfrom logits \(\rightarrow\) computecompute_dpo_lossfrom log probabilities - we have the
compute_dpo_loss_batchfunction that facilitates the process above - the
compute_dpo_loss_loaderutility function applies thecompute_dpo_loss_batchfunction to a data loader - the
evaluate_dpo_loss_loaderfunction applies thecompute_dpo_loss_batchto both the training and validation set data loaders for logging purposes
- The flow is: compute
## Training the model
After setting up the DPO loss functions in the previous section, we can now finally train the model
Note that this training function is the same one we used for pretraining and instruction finetuning, with minor differences:
we swap the cross-entropy loss with our new DPO loss function
we also track the rewards and reward margins, which are commonly used in RLHF and DPO contexts to track the training progress
Before we start the training, let’s print the initial losses and rewards:
Training loss: 0.6931471824645996
Validation loss: 0.6931471824645996
Train reward margin: 0.0
Val reward margin: 0.0- Also, let’s take a look at some of the initial model responses (the first 3 examples in the validation set):
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
Correct response:
>> The meal is cooked by the chef every day.
Model response:
>> The meal is cooked every day by the chef.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Classify an input string as either a noun or a verb.
### Input:
Dance
Correct response:
>> 'Dance' can be classified as a verb.
Model response:
>> "Dance" can be classified as a verb.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a metaphor.
### Input:
The book is very interesting.
Correct response:
>> The book is a page-turner.
Model response:
>> The book is a treat.
-------------------------------------
- Above, we see the original model responses
- Note that the goal of DPO is to induce slight style changes; this means we want the model to generate similar but slightly more polite responses
- Before we execute the following code cell that starts the training, here are a few notes about some of the settings:
- we are only passing the parameters of the policy model into the
AdamWoptimizer; that’s the model we want to optimize (we don’t want to modify the reference model) - we only train for 1 epoch; that’s because DPO is very prone to collapse (the loss might improve, but the model will start generating nonsensical texts)
- in DPO, it’s best to use a very small learning rate
- the beta value can be increased from 0.1 to 0.5 to reduce the effect of DPO (we use 0.1 here to make the results more noticeable)
- The training takes about 2 minutes on an A100 GPU, but it can also be trained in 4 minutes on a smaller L4 GPU; training on a M3 MacBook Air takes about 30 minutes
Ep 1 (Step 000000): Train loss 0.692, Val loss 0.693, Train reward margins 0.019, Val reward margins 0.009
Ep 1 (Step 000005): Train loss 0.690, Val loss 0.691, Train reward margins 0.070, Val reward margins 0.052
Ep 1 (Step 000010): Train loss 0.687, Val loss 0.688, Train reward margins 0.126, Val reward margins 0.108
Ep 1 (Step 000015): Train loss 0.676, Val loss 0.685, Train reward margins 0.362, Val reward margins 0.173
Ep 1 (Step 000020): Train loss 0.676, Val loss 0.680, Train reward margins 0.351, Val reward margins 0.264
Ep 1 (Step 000025): Train loss 0.666, Val loss 0.676, Train reward margins 0.564, Val reward margins 0.359
Ep 1 (Step 000030): Train loss 0.672, Val loss 0.672, Train reward margins 0.456, Val reward margins 0.441
Ep 1 (Step 000035): Train loss 0.663, Val loss 0.669, Train reward margins 0.658, Val reward margins 0.511
Ep 1 (Step 000040): Train loss 0.666, Val loss 0.666, Train reward margins 0.597, Val reward margins 0.574
Ep 1 (Step 000045): Train loss 0.648, Val loss 0.662, Train reward margins 0.982, Val reward margins 0.660
Ep 1 (Step 000050): Train loss 0.648, Val loss 0.659, Train reward margins 0.993, Val reward margins 0.734
Ep 1 (Step 000055): Train loss 0.647, Val loss 0.656, Train reward margins 1.014, Val reward margins 0.799
Ep 1 (Step 000060): Train loss 0.652, Val loss 0.653, Train reward margins 0.893, Val reward margins 0.870
Ep 1 (Step 000065): Train loss 0.631, Val loss 0.650, Train reward margins 1.361, Val reward margins 0.948
Ep 1 (Step 000070): Train loss 0.618, Val loss 0.646, Train reward margins 1.699, Val reward margins 1.038
Ep 1 (Step 000075): Train loss 0.617, Val loss 0.642, Train reward margins 1.733, Val reward margins 1.121
Ep 1 (Step 000080): Train loss 0.592, Val loss 0.639, Train reward margins 2.333, Val reward margins 1.194
Ep 1 (Step 000085): Train loss 0.610, Val loss 0.636, Train reward margins 1.907, Val reward margins 1.275
Ep 1 (Step 000090): Train loss 0.650, Val loss 0.633, Train reward margins 0.964, Val reward margins 1.353
Ep 1 (Step 000095): Train loss 0.607, Val loss 0.630, Train reward margins 1.962, Val reward margins 1.423
Ep 1 (Step 000100): Train loss 0.600, Val loss 0.627, Train reward margins 2.127, Val reward margins 1.500
Ep 1 (Step 000105): Train loss 0.590, Val loss 0.624, Train reward margins 2.458, Val reward margins 1.564
Ep 1 (Step 000110): Train loss 0.607, Val loss 0.622, Train reward margins 1.976, Val reward margins 1.621
Ep 1 (Step 000115): Train loss 0.621, Val loss 0.620, Train reward margins 1.605, Val reward margins 1.682
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Rewrite the sentence using a metaphor. ### Input: The book is very interesting. ### Response: The book is a treat.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Input: The assignment was written by the student. ### Response
Training completed in 1.69 minutes.- As we can see based on the tracked results above, the loss improves
- Also, the reward margins, which is the difference between the rewards of the chosen and the rejected responses, improve, which is a good sign
- Let’s take a more concrete look at these results in the next section
## Analyzing the results
- Let’s begin analyzing the results by plotting the DPO loss:
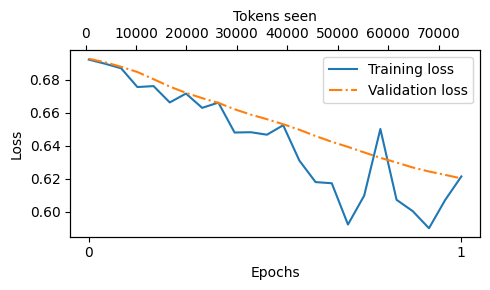
- As we can see above, the loss continues to improve, which is a good sign
- Based on the downward slope, one might be tempted to train the model a bit further (and readers are encouraged to try this), but note that DPO is prone to collapse, where the model may start generating nonsensical responses
- Next, let’s take a look at the reward margins:
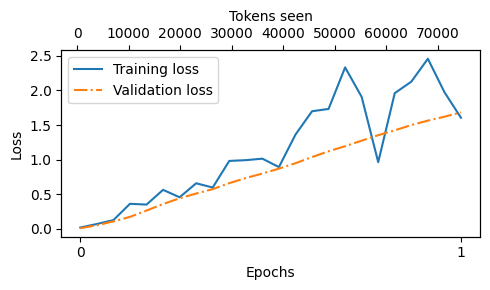
- As we can see, and as it’s desired, the reward margins improve; this mirrors the loss curve and is a good sign
- Note that DPO losses and reward margins are valuable metrics to track during training; however, they don’t tell the whole story
- Lastly, and most importantly, we have to conduct a qualitative check of the responses
- Here, we will look at the response (in addition, you could use an LLM to score the responses similar to chapter 7)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
Correct response:
>> The meal is cooked by the chef every day.
Reference model response:
>> The meal is cooked every day by the chef.
Policy model response:
>> The meal is prepared by the chef.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Classify an input string as either a noun or a verb.
### Input:
Dance
Correct response:
>> 'Dance' can be classified as a verb.
Reference model response:
>> "Dance" can be classified as a verb.
Policy model response:
>> The input string "Dance" could be classified as a verb.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a metaphor.
### Input:
The book is very interesting.
Correct response:
>> The book is a page-turner.
Reference model response:
>> The book is a treat.
Policy model response:
>> The book is a treat.
-------------------------------------
- As we can see based on the reference model and policy model responses above, the optimized model (i.e., the policy model) indeed slightly changed its style compared to the original model (i.e., reference model)
- For instance,
"Dance" can be classified as a verb.changed toThe input string "Dance" could be classified as a verb.which is a slightly more polite response (the use of “could” instead of “can” makes the statement sound less assertive and more tentative)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
Correct response:
>> The car is as fast as lightning.
Reference model response:
>> The car is as fast as a cheetah.
Policy model response:
>> The car is as fast as a cheetah.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of cloud is typically associated with thunderstorms?
Correct response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Reference model response:
>> A thunderstorm is a type of storm that typically produces thunder or lightning.
Policy model response:
>> The type of cloud typically associated with thunderstorms is a cumulus.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the author of 'Pride and Prejudice'.
Correct response:
>> Jane Austen.
Reference model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
Policy model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
-------------------------------------
9. Deployment in HF-Hub using Gradio
from pathlib import Path
import sys
import tiktoken
import torch
import gradio as gr
# For llms_from_scratch installation instructions, see:
# https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg
from previous_chapters import GPTModel
from previous_chapters import (
generate,
text_to_token_ids,
token_ids_to_text,
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def get_model_and_tokenizer():
"""
Code to load a GPT-2 model with finetuned weights generated in chapter 7.
This requires that you run the code in chapter 7 first, which generates the necessary gpt2-medium355M-sft.pth file.
"""
GPT_CONFIG_355M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
tokenizer = tiktoken.get_encoding("gpt2")
# For local development
model_path = Path("gpt2-small124M-sft.pth")
# For Hugging Face deployment
hf_model_path = Path("gpt2-small124M-sft.pth")
# Try loading from the Hugging Face model path first, then fall back to local
if hf_model_path.exists():
model_path = hf_model_path
elif not model_path.exists():
print(
f"Could not find the model file. Please run the chapter 7 code "
"to generate the gpt2-medium355M-sft.pth file or upload it to this directory."
)
sys.exit()
checkpoint = torch.load(model_path, weights_only=True)
model = GPTModel(GPT_CONFIG_355M)
model.load_state_dict(checkpoint)
model.to(device)
model.eval() # Set to evaluation mode
return tokenizer, model, GPT_CONFIG_355M
def extract_response(response_text, input_text):
return response_text[len(input_text):].replace("### Response:", "").strip()
# Load model and tokenizer
tokenizer, model, model_config = get_model_and_tokenizer()
def generate_response(message, max_new_tokens=100):
"""Generate a response using the fine-tuned GPT model"""
torch.manual_seed(123)
prompt = f"""Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{message}
"""
with torch.no_grad(): # Ensure no gradients are computed during inference
token_ids = generate(
model=model,
idx=text_to_token_ids(prompt, tokenizer).to(device),
max_new_tokens=max_new_tokens,
context_size=model_config["context_length"],
eos_id=50256
)
text = token_ids_to_text(token_ids, tokenizer)
response = extract_response(text, prompt)
return response
# Create a custom chat interface without using ChatInterface class
def respond(message, chat_history):
bot_message = generate_response(message)
chat_history.append((message, bot_message))
return "", chat_history
with gr.Blocks(theme="soft") as demo:
gr.Markdown("# Fine-tuned GPT Model Chat")
gr.Markdown("Chat with a fine-tuned GPT model from 'Build a Large Language Model From Scratch' by Sebastian Raschka")
chatbot = gr.Chatbot(height=600)
msg = gr.Textbox(placeholder="Ask me something...", container=False, scale=7)
clear = gr.Button("Clear")
msg.submit(respond, [msg, chatbot], [msg, chatbot])
clear.click(lambda: [], None, chatbot)
gr.Examples(
examples=[
"What is the capital of France?",
"What is the opposite of 'wet'?",
"what is the capital of USA?"
],
inputs=msg
)
# Launch the interface
if __name__ == "__main__":
demo.launch(share=True)Fine-tuned GPT Model Demo
This interactive demo showcases a GPT model fine-tuned using techniques from “Build a Large Language Model From Scratch” by Sebastian Raschka. Try asking questions or giving it instructions to see the model in action.
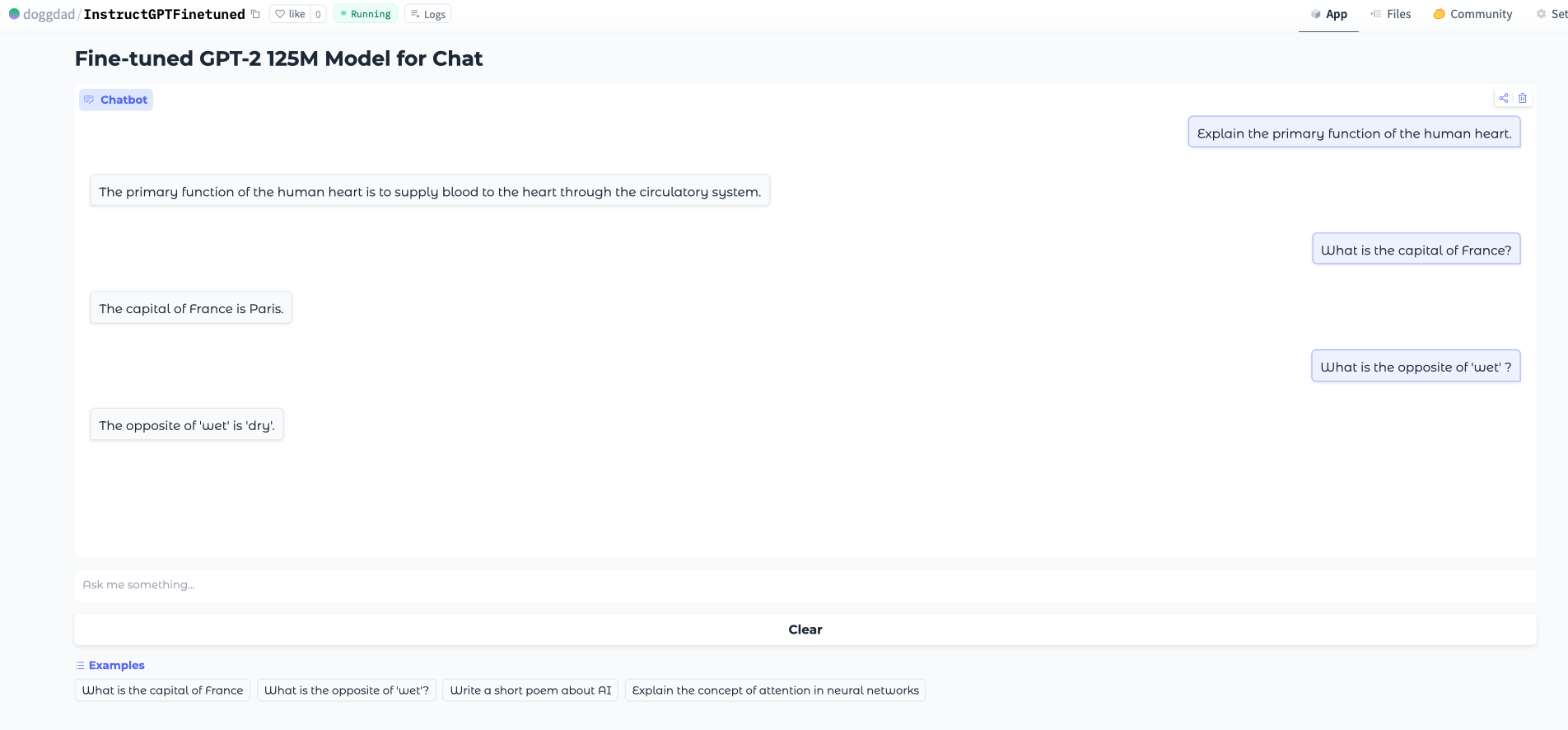
Loading interactive demo...
Tips for using the model: Try asking questions, requesting creative content, or giving specific instructions.
Try the demo above or visit the full Hugging Face Space for the best experience.
10. Key Technical Achievements
- Complete GPT Implementation: Full transformer architecture with multi-head attention, layer normalization, and residual connections
- From-Scratch Components: Custom tokenizer, attention mechanisms, and training loops
- Weight Transfer: Successfully loading OpenAI GPT-2 pretrained weights (124M-1558M parameters)
- Two Finetuning Approaches: Classification (spam detection) and instruction-following
- Advanced Sampling: Temperature scaling and top-k sampling for controlled generation
- Automated Evaluation: LLM-based evaluation using local Ollama models
- Laptop-Scale Training: All code designed to run on conventional laptops without specialized hardware
References
- Book: Build a Large Language Model (From Scratch) by Sebastian Raschka
- Publisher: Manning Publications
- ISBN: 9781633437166
- GitHub: https://github.com/rasbt/LLMs-from-scratch