from importlib.metadata import version
print("torch version:", version("torch"))
print("tiktoken version:", version("tiktoken"))torch version: 2.5.1
tiktoken version: 0.7.0Packages that are being used in this notebook:
In [1]:
from importlib.metadata import version
print("torch version:", version("torch"))
print("tiktoken version:", version("tiktoken"))torch version: 2.5.1
tiktoken version: 0.7.0


In [2]:
import os
import urllib.request
if not os.path.exists("the-verdict.txt"):
url = ("https://raw.githubusercontent.com/rasbt/"
"LLMs-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt")
file_path = "the-verdict.txt"
urllib.request.urlretrieve(url, file_path)ssl.SSLCertVerificationError when executing the previous code cell, it might be due to using an outdated Python version; you can find more information here on GitHub)In [3]:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no In [4]:
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']In [5]:
result = re.split(r'([,.]|\s)', text)
print(result)['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']In [6]:
# Strip whitespace from each item and then filter out any empty strings.
result = [item for item in result if item.strip()]
print(result)['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']In [7]:
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
In [8]:
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']In [9]:
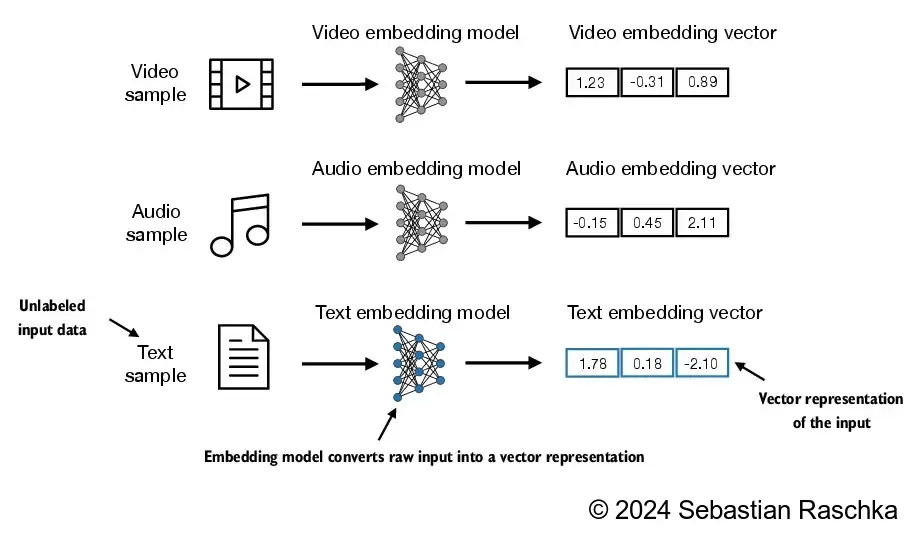
print(len(preprocessed))4690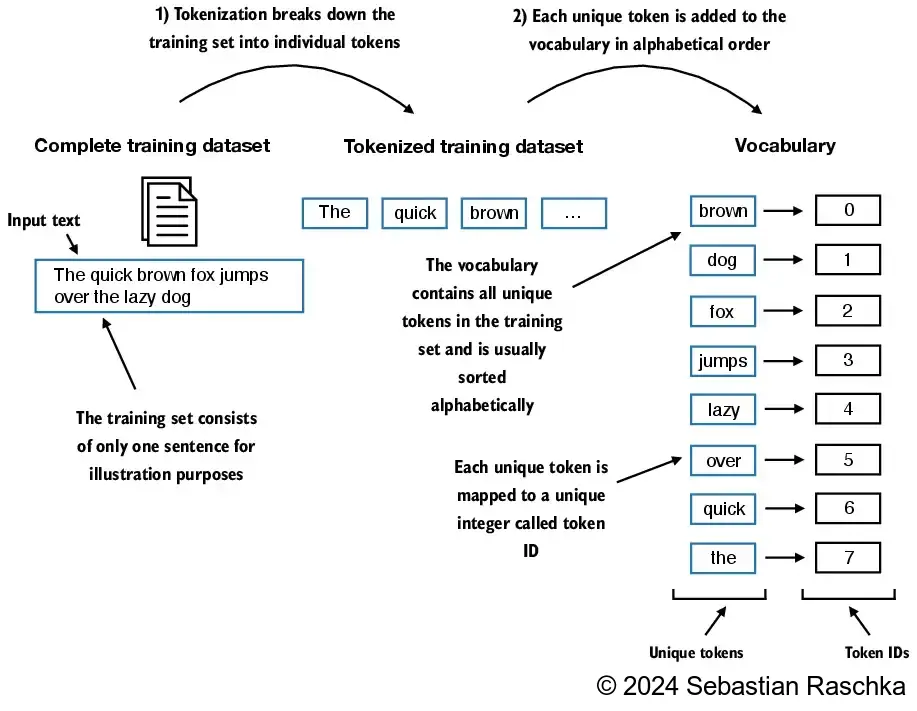
In [10]:
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)1130In [11]:
vocab = {token:integer for integer,token in enumerate(all_words)}In [12]:
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
break('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
('Chicago', 25)
('Claude', 26)
('Come', 27)
('Croft', 28)
('Destroyed', 29)
('Devonshire', 30)
('Don', 31)
('Dubarry', 32)
('Emperors', 33)
('Florence', 34)
('For', 35)
('Gallery', 36)
('Gideon', 37)
('Gisburn', 38)
('Gisburns', 39)
('Grafton', 40)
('Greek', 41)
('Grindle', 42)
('Grindles', 43)
('HAD', 44)
('Had', 45)
('Hang', 46)
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)
In [13]:
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return textencode function turns text into token IDsdecode function turns token IDs back into text
In [14]:
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]In [15]:
tokenizer.decode(ids)'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'In [16]:
tokenizer.decode(tokenizer.encode(text))'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
Some tokenizers use special tokens to help the LLM with additional context
Some of these special tokens are
[BOS] (beginning of sequence) marks the beginning of text[EOS] (end of sequence) marks where the text ends (this is usually used to concatenate multiple unrelated texts, e.g., two different Wikipedia articles or two different books, and so on)[PAD] (padding) if we train LLMs with a batch size greater than 1 (we may include multiple texts with different lengths; with the padding token we pad the shorter texts to the longest length so that all texts have an equal length)[UNK] to represent words that are not included in the vocabulary
Note that GPT-2 does not need any of these tokens mentioned above but only uses an <|endoftext|> token to reduce complexity
The <|endoftext|> is analogous to the [EOS] token mentioned above
GPT also uses the <|endoftext|> for padding (since we typically use a mask when training on batched inputs, we would not attend padded tokens anyways, so it does not matter what these tokens are)
GPT-2 does not use an <UNK> token for out-of-vocabulary words; instead, GPT-2 uses a byte-pair encoding (BPE) tokenizer, which breaks down words into subword units which we will discuss in a later section
<|endoftext|> tokens between two independent sources of text: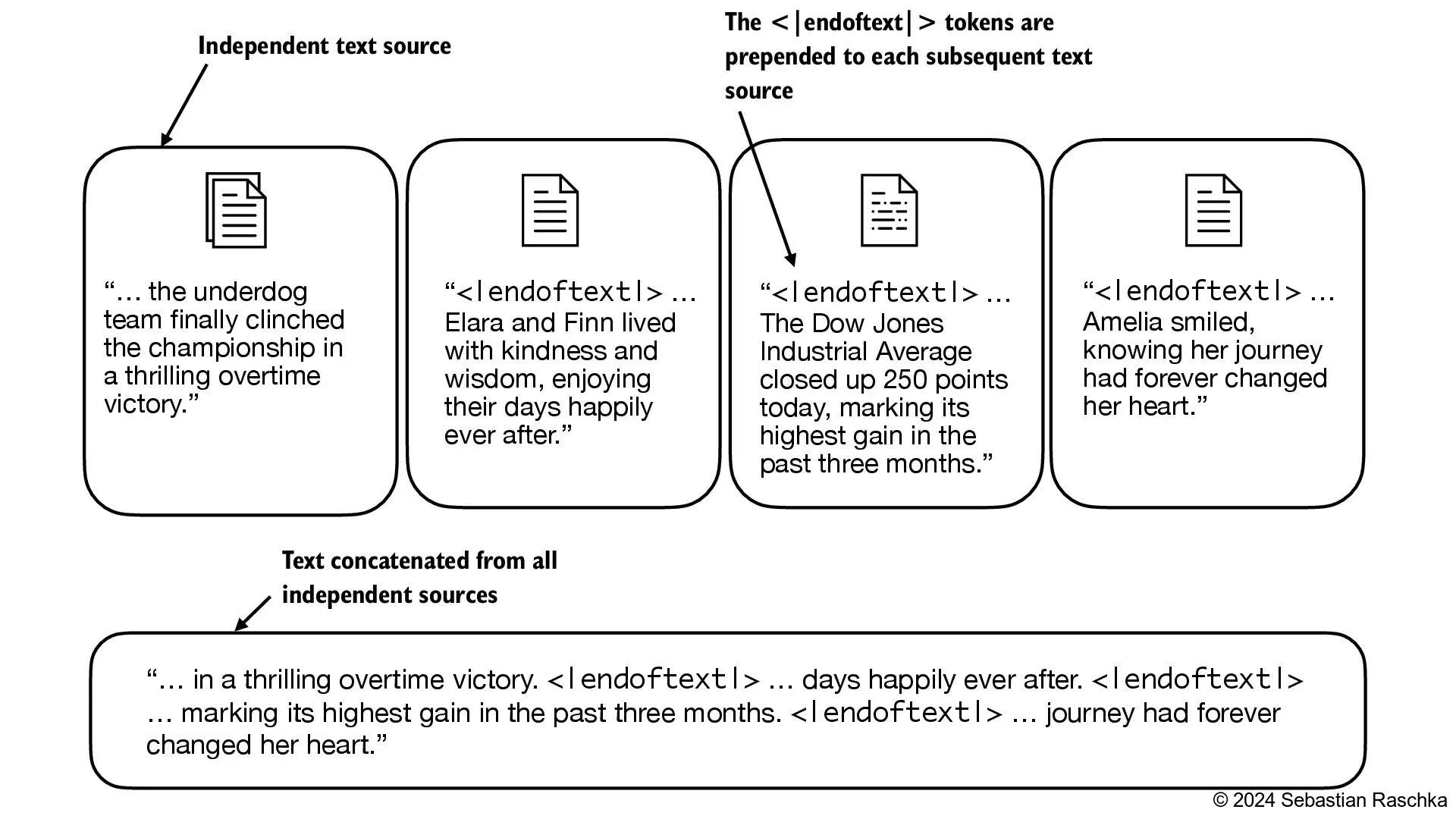
In [17]:
tokenizer = SimpleTokenizerV1(vocab)
text = "Hello, do you like tea. Is this-- a test?"
tokenizer.encode(text)--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Cell In[17], line 5 1 tokenizer = SimpleTokenizerV1(vocab) 3 text = "Hello, do you like tea. Is this-- a test?" ----> 5 tokenizer.encode(text) Cell In[13], line 12, in SimpleTokenizerV1.encode(self, text) 7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text) 9 preprocessed = [ 10 item.strip() for item in preprocessed if item.strip() 11 ] ---> 12 ids = [self.str_to_int[s] for s in preprocessed] 13 return ids Cell In[13], line 12, in <listcomp>(.0) 7 preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text) 9 preprocessed = [ 10 item.strip() for item in preprocessed if item.strip() 11 ] ---> 12 ids = [self.str_to_int[s] for s in preprocessed] 13 return ids KeyError: 'Hello'
"<|unk|>" to the vocabulary to represent unknown words"<|endoftext|>" which is used in GPT-2 training to denote the end of a text (and it’s also used between concatenated text, like if our training datasets consists of multiple articles, books, etc.)In [18]:
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}In [19]:
len(vocab.items())1132In [20]:
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)<unk> tokenIn [21]:
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return textLet’s try to tokenize text with the modified tokenizer:
In [22]:
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.In [23]:
tokenizer.encode(text)[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]In [24]:
tokenizer.decode(tokenizer.encode(text))'<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'In [25]:
# pip install tiktokenIn [26]:
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))tiktoken version: 0.7.0In [27]:
tokenizer = tiktoken.get_encoding("gpt2")In [28]:
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13]In [29]:
strings = tokenizer.decode(integers)
print(strings)Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.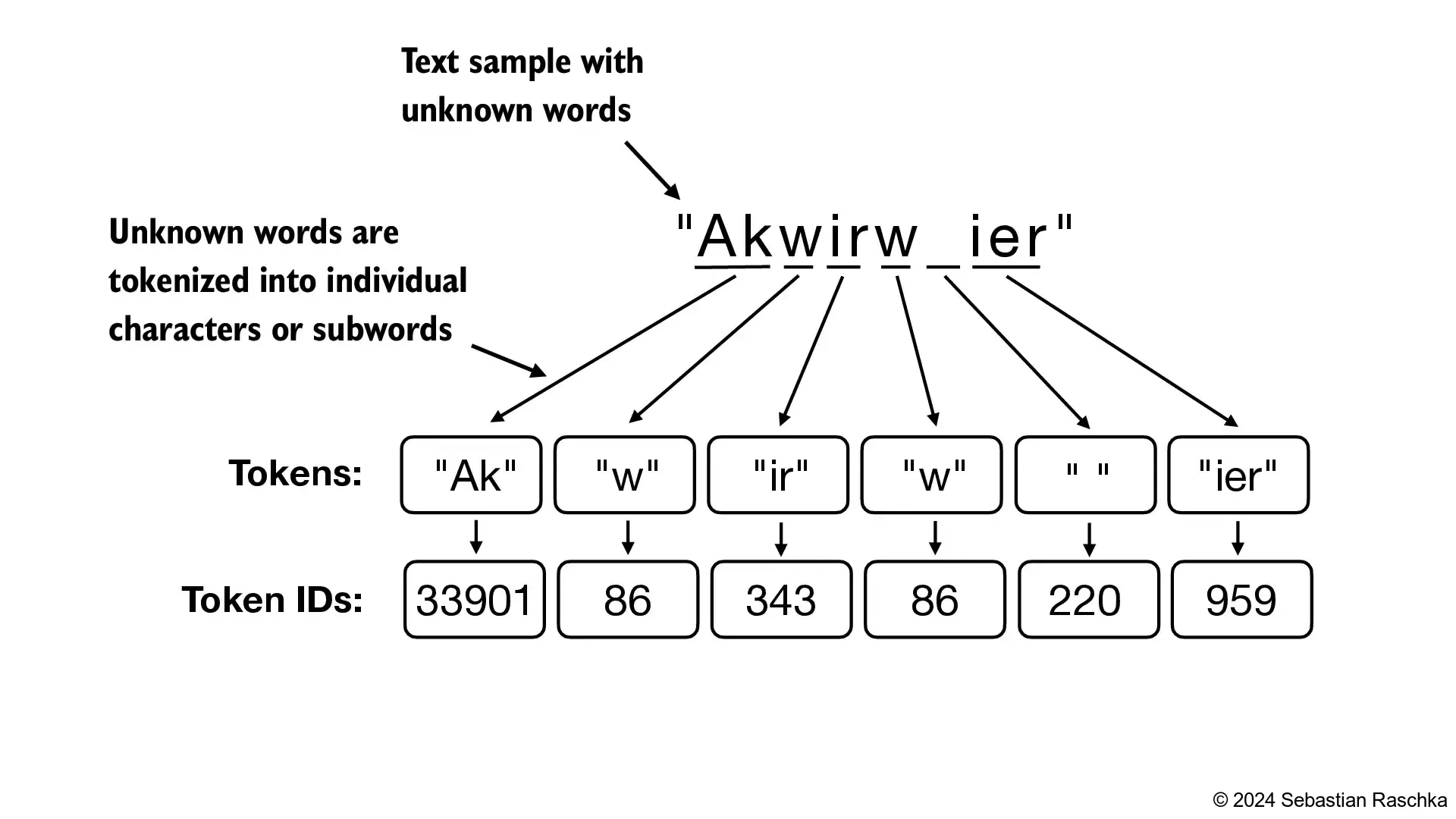

In [30]:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
print(len(enc_text))5145In [31]:
enc_sample = enc_text[50:]In [32]:
context_size = 4
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]In [33]:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(context, "---->", desired)[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257In [34]:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired])) and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> aIn [35]:
import torch
print("PyTorch version:", torch.__version__)PyTorch version: 2.5.1
In [36]:
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
assert len(token_ids) > max_length, "Number of tokenized inputs must at least be equal to max_length+1"
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]In [37]:
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloaderIn [38]:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()In [39]:
dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]In [40]:
second_batch = next(data_iter)
print(second_batch)[tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]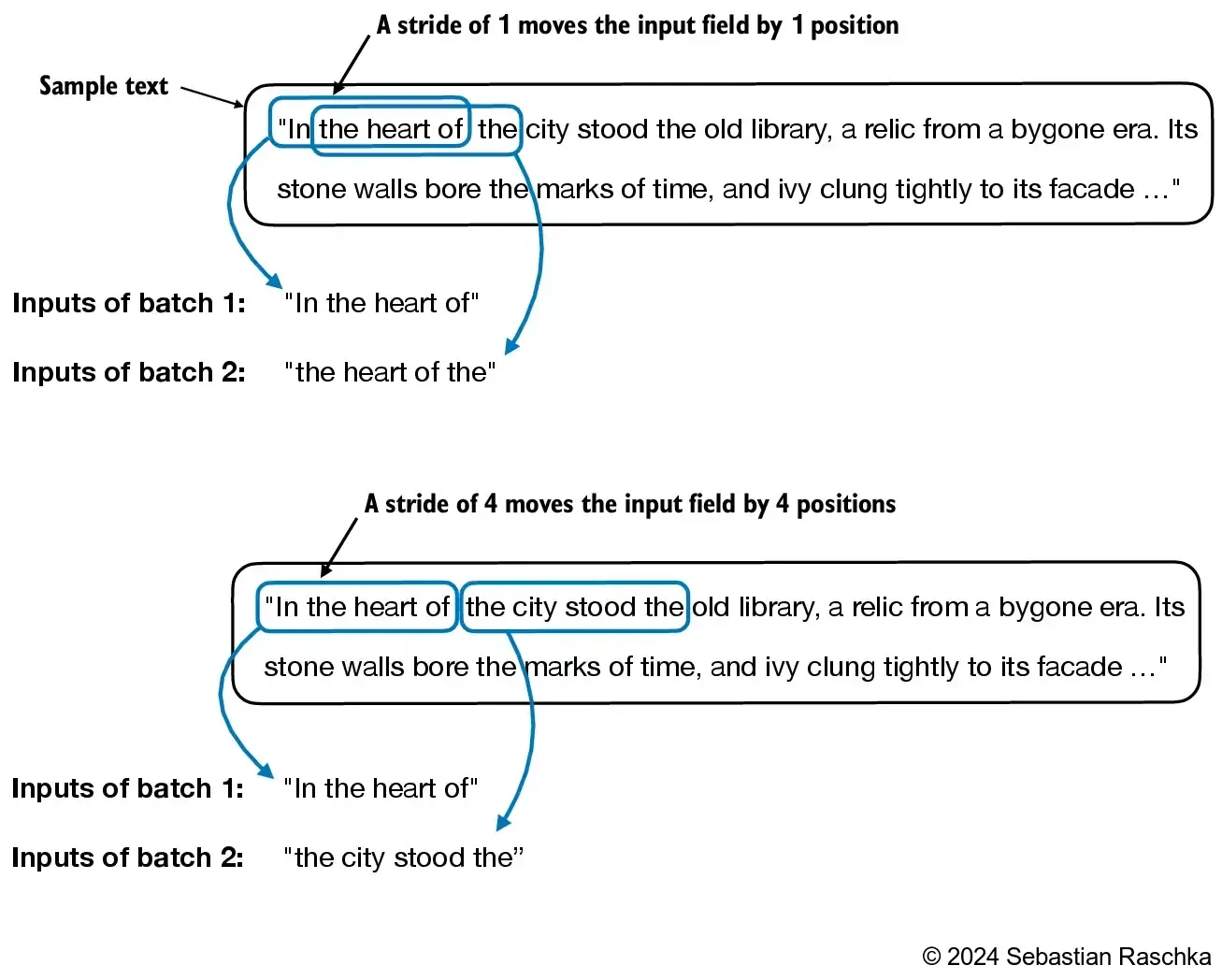
In [41]:
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])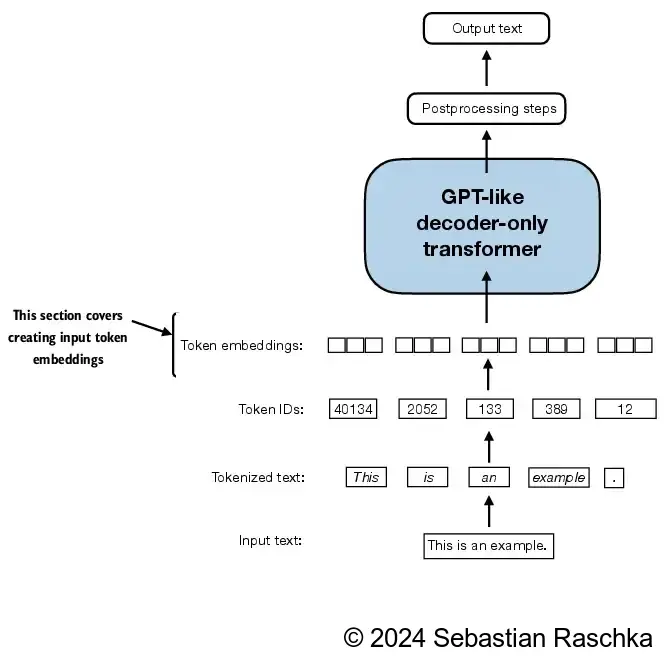
In [42]:
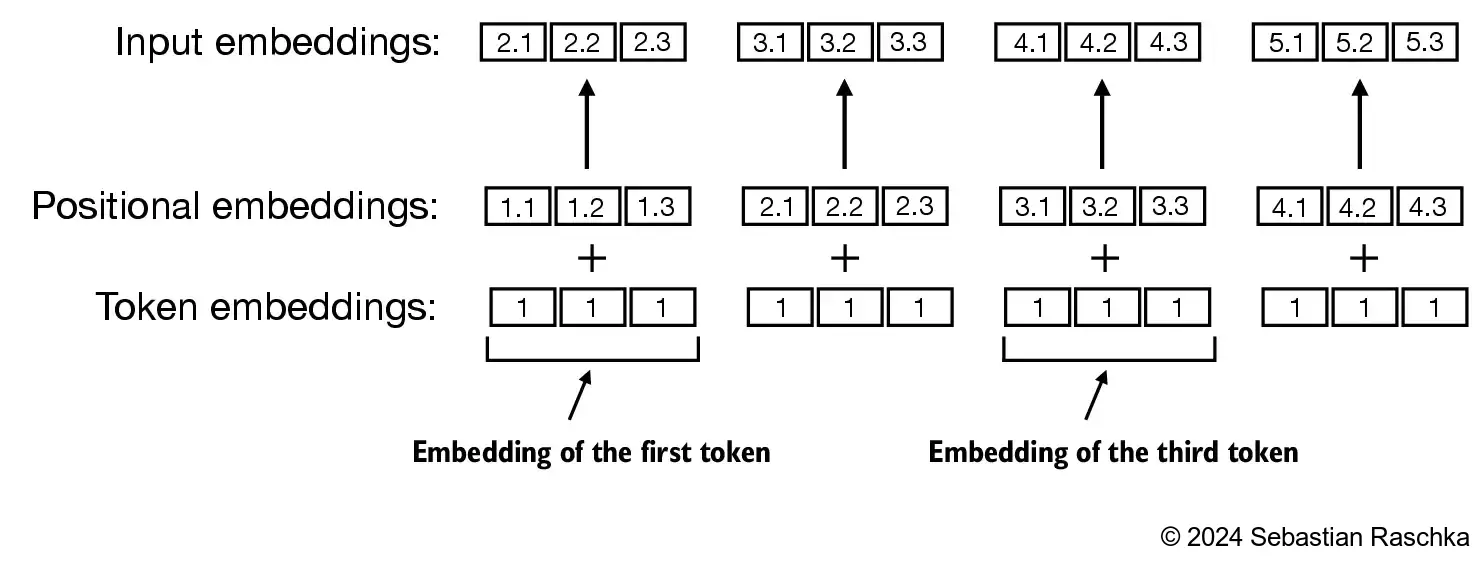
input_ids = torch.tensor([2, 3, 5, 1])In [43]:
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)In [44]:
print(embedding_layer.weight)Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)In [45]:
print(embedding_layer(torch.tensor([3])))tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)embedding_layer weight matrixinput_ids values above, we doIn [46]:
print(embedding_layer(input_ids))tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)

In [47]:
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)In [48]:
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)In [49]:
print("Token IDs:\n", inputs)
print("\nInputs shape:\n", inputs.shape)Token IDs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Inputs shape:
torch.Size([8, 4])In [50]:
token_embeddings = token_embedding_layer(inputs)
print(token_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
# print(token_embeddings)torch.Size([8, 4, 256])In [51]:
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
# uncomment & execute the following line to see how the embedding layer weights look like
# print(pos_embedding_layer.weight)In [52]:
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
print(pos_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
# print(pos_embeddings)torch.Size([4, 256])In [53]:
input_embeddings = token_embeddings + pos_embeddings
print(input_embeddings.shape)
# uncomment & execute the following line to see how the embeddings look like
# print(input_embeddings)torch.Size([8, 4, 256])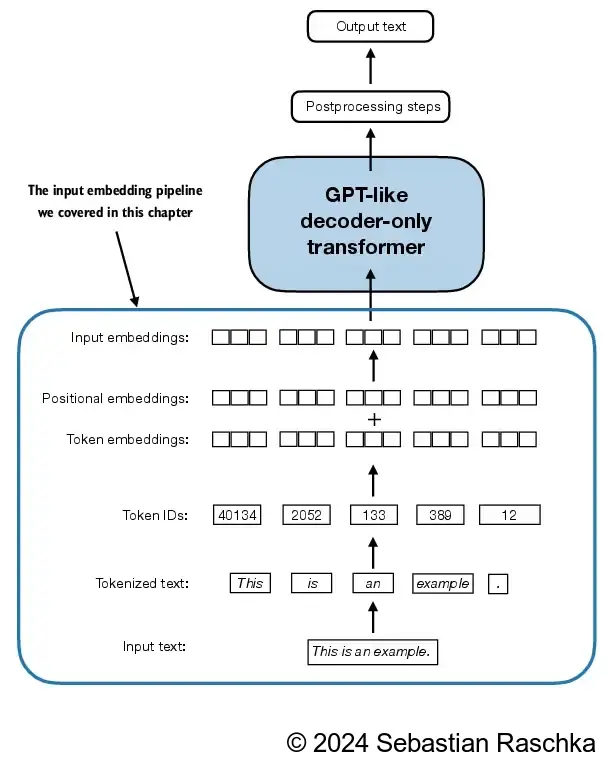
See the ./dataloader.ipynb code notebook, which is a concise version of the data loader that we implemented in this chapter and will need for training the GPT model in upcoming chapters.
See ./exercise-solutions.ipynb for the exercise solutions.
See the Byte Pair Encoding (BPE) Tokenizer From Scratch notebook if you are interested in learning how the GPT-2 tokenizer can be implemented and trained from scratch.